一个规模比较大,用户比较多的数据仓库/数据平台中,肯定会面临这两个问题:多用户的资源分配与竞争、服务的高可用与负载均衡。我们的平台中,95%的离线计算和即席查询任务都通过Hive和SparkSQL来完成,平台的开发和内部用户有十来个,Hive和SparkSQL的使用,自然也会面临上面的两个问题。
如果只是Hive,这两个问题的解决方案是很成熟的,可以使用Hadoop的资源调度策略和Hive的HA机制来完成。可参考我之前的两篇博文:《Yarn公平调度器Fair Scheduler根据用户组分配资源池》 和 《HiveServer2的高可用-HA配置》.
现在我们通过SparkThriftServer(On Yarn)来给用户提供SparkSQL操作Hive数据的服务,也得解决这两个问题,第一个问题,对于多用户的资源分配与竞争,也请参考我的两篇博文:《Spark动态资源分配-Dynamic Resource Allocation》和《SparkThrfitServer多用户资源竞争与分配问题》。
本文介绍的是SparkThriftServer的第二个问题,高可用与负载均衡。
理论上来说,SparkThriftServer使用的是HiveServer2,它自然也应该继承HiveServer2的HA机制,可惜没有,至于为什么没有,请参考JD的大牛提的这个ISSUE 《HiveThriftServer HA issue,HiveThriftServer not registering with Zookeeper》,同时他也提供了Patch,我就是参考他的Patch,简单的修改了一下spark-thriftserver的代码,来解决该问题。
我的环境:
hadoop-2.6.0-cdh5.8.3
apache-hive-2.1.1-bin
spark-2.1.0-bin-hadoop2.6
PS:本文介绍的解决思路同样适用于较低版本的Hive和Spark。
再PS:修改和替换过程中,请注意备份原来的文件。
简单修改Spark源码
对于Spark2.0以上的版本,需要修改两个文件:
第一个scala代码: org.apache.spark.sql.hive.thriftserver.HiveThriftServer2
源码路径位于:spark-2.1.0/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver
....
server.init(executionHive.conf)
server.start()
//add by lxw begin
if (executionHive.conf.getBoolVar(ConfVars.HIVE_SERVER2_SUPPORT_DYNAMIC_SERVICE_DISCOVERY)) {
invoke(classOf[HiveServer2], server, "addServerInstanceToZooKeeper",classOf[HiveConf] -> executionHive.conf)
}
//add by lxw end
...
...
server.init(executionHive.conf)
server.start()
//add by lxw begin
if (executionHive.conf.getBoolVar(ConfVars.HIVE_SERVER2_SUPPORT_DYNAMIC_SERVICE_DISCOVERY)) {
invoke(classOf[HiveServer2], server, "addServerInstanceToZooKeeper",classOf[HiveConf] -> executionHive.conf)
}
//add by lxw end
即,在两处server启动的地方,添加向ZK注册的动作。
第二个Java代码:org.apache.hive.service.server.HiveServer2
源码路径位于:spark-2.1.0/sql/hive-thriftserver/src/main/java/org/apache/hive/service/server
此文件修改的比较简单粗暴,直接从github上拷贝Hive1.2.1的该类源码,然后需要修改几个对象和方法的权限:
public static class ServerOptionsProcessor public ServerOptionsProcessor(String serverName) public ServerOptionsProcessorResponse parse(String[] argv)
你也可以下载我修改后的(点此下载HiveServer2.java)
编译Spark
使用修改后的源码,编译Spark:
export MAVEN_OPTS="-Xmx4g -XX:ReservedCodeCacheSize=1024m -XX:MaxPermSize=256m" mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -Phive -Phive-thriftserver -Dscala-2.11 -DskipTests clean package
这里编译时候,你可以略过一些不必要的子模块。
编译完后,将spark-2.1.0/sql/hive-thriftserver/target/spark-hive-thriftserver_2.11-2.1.0.jar 拷贝到$SPARK_HOME/jars目录,覆盖原来该jar包。
配置SparkThriftServer HA
该配置和《HiveServer2的高可用-HA配置》中介绍的完全一样,只需要在hive-site.xml中配置即可,请参考该文。
启动多个SparkThriftServer实例
我这里准备启动两个实例。启动命令均为:
cd $SPARK_HOME/sbin ./start-thriftserver.sh \ --master yarn \ --conf spark.driver.memory=3G \ --executor-memory 1G \ --num-executors 10 \ --hiveconf hive.server2.thrift.port=10003
第一个启动后:

在ZK中查看:
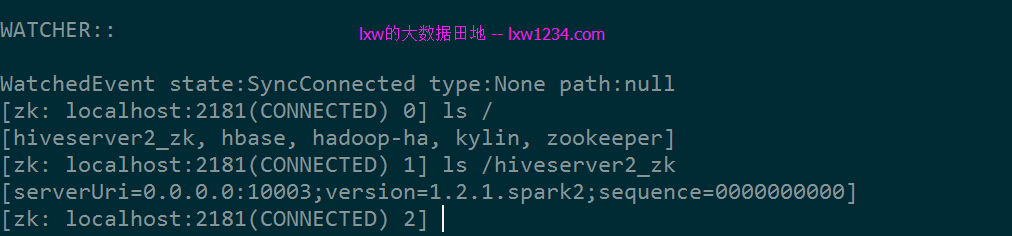
第二个启动后:

可以看到,两个实例均已注册到ZK。
连接SparkThriftServer
还是请参考HiveServer2 HA的博文,beeline连接命令为:
!connect jdbc:hive2://slave001.hdtc.cloud:2181,slave002.hdtc.cloud:2181,slave003.hdtc.cloud:2181/liuxiaowen;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk liuxiaowen liuxiaowen@password

我分别从不同的节点,建立了三个连接:
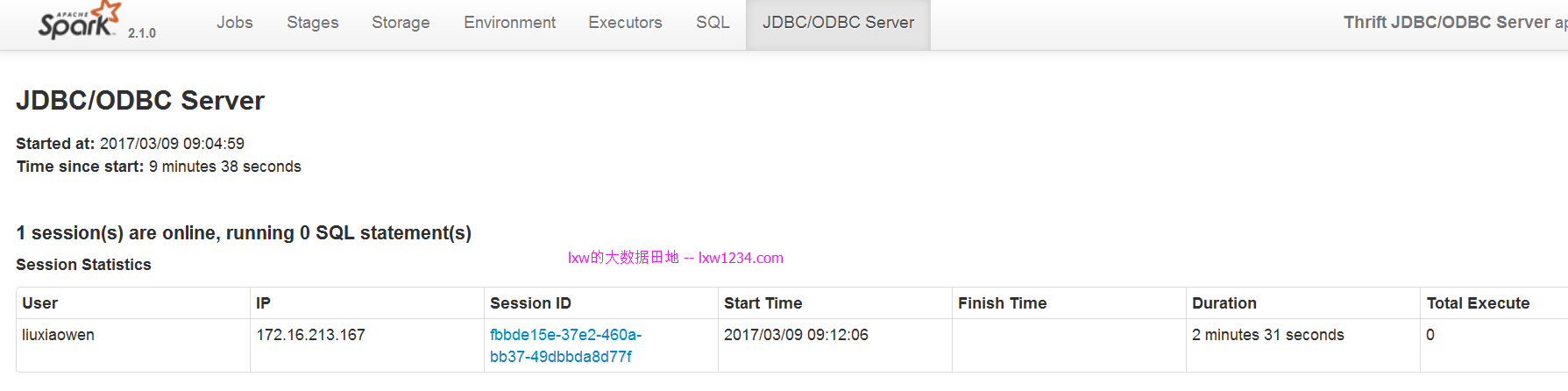

可以看到,实例1中连接了1个会话,实例2中连接了2个,算是实现了负载均衡和HA了。
以上,希望能对大家在实际使用中有所帮助。
相关阅读:
《Yarn公平调度器Fair Scheduler根据用户组分配资源池》
《Spark动态资源分配-Dynamic Resource Allocation》
《SparkThrfitServer多用户资源竞争与分配问题》
如果觉得本博客对您有帮助,请 赞助作者 。


