关键字:elasticsearch、olap
一直想找一个用于大数据平台实时OLAP(甚至是实时计算)的框架,之前调研的Druid(druid.io)太过复杂,整个Druid由5、6个服务组成,而且加载数据也不太方便,性能一般,亦或是我还不太会用它。后来发现使用ElasticSearch就可以满足海量数据实时OLAP的需求。
ElasticSearch相信大家都很熟悉了,它在搜索领域已经有了举足轻重的地位,而且也支持越来越多的聚合统计功能,还和YARN、Hadoop、Hive、Spark、Pig、Flume等大数据框架兼容的越来越好,比如:可以将ElasticSearch跑在YARN上,还可以在Hive中建立外部表映射到ElasticSearch的Index中,直接在Hive中执行INSERT语句,将数据加载进ElasticSearch。
所谓OLAP,其实就是从事实表中统计任意组合维度的指标,也就是过滤、分组、聚合,其中,聚合除了一般的SUM、COUNT、AVG、MAX、MIN等,还有一个重要的COUNT(DISTINCT),看上去这些操作在SQL中是非常简单的统计,但在海量数据、低延迟的要求下,并不是那么容易做的。
ElasticSearch本来就是做实时搜索的,过滤自然不是问题,现在也支持各种聚合以及Pipeline aggregations(相当于SQL子查询的功能),而且ElasticSearch的安装部署也非常简单,一个节点只有一个服务进程,关于安装配置可参考:http://lxw1234.com/archives/2015/12/582.htm
本文以两个业务场景的例子,看一下ElasticSearch是如何满足我们的需求的。
例子1:网站流量报告
在我们的报表平台有这样一张报表,用于查看每个网站每天的流量指标:
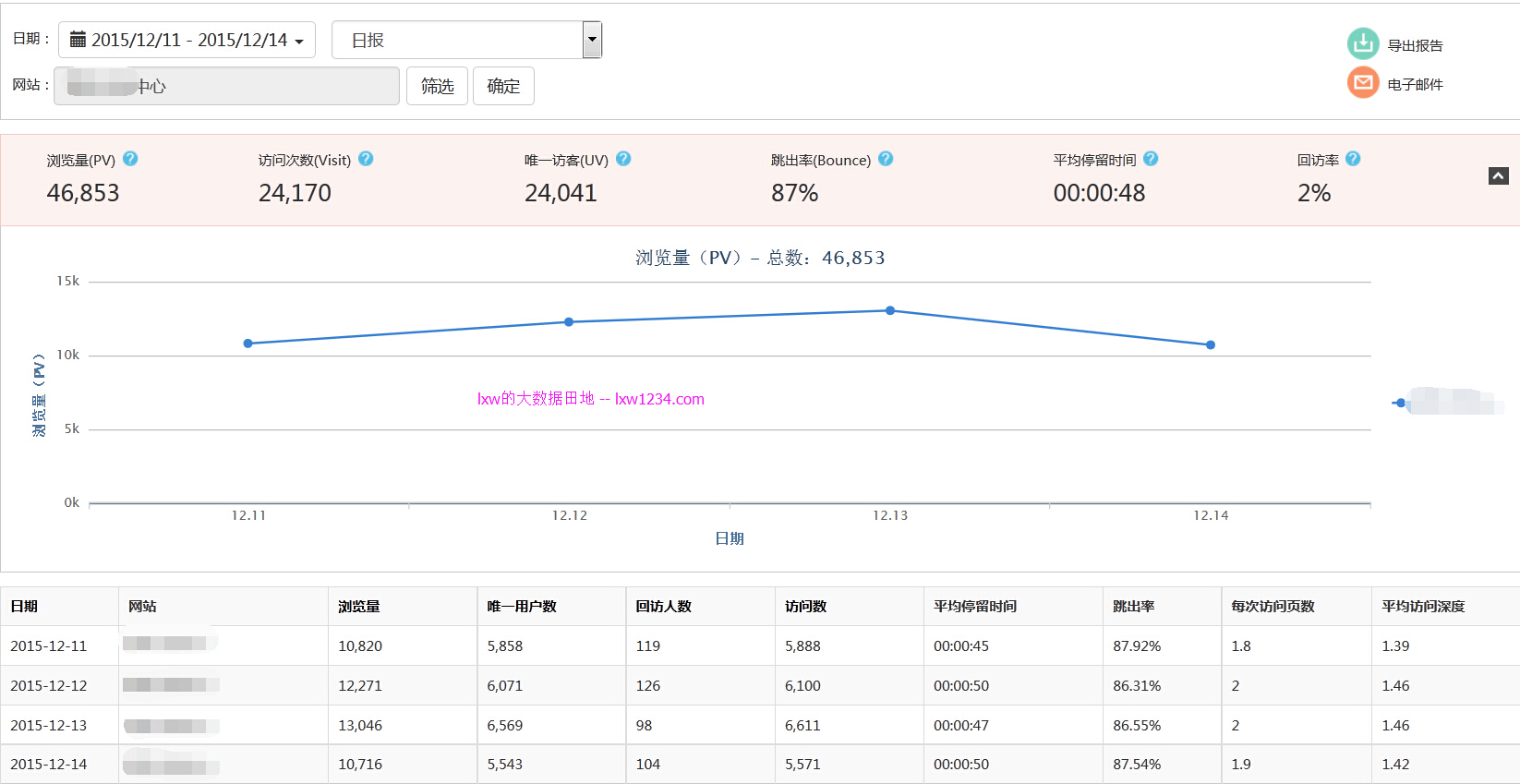
其中,维度有:天、小时、网站,指标有:PV、UV、访问次数、跳出率、平均停留时间、回访率等。另外,还有一张报表是地域报告,维度多了省份和城市,指标一样。目前的做法是将可选的维度组合及对应的指标先在Hive中分析好,再将结果同步至MySQL,供报表展现。
真正意义上的OLAP做法,我是这样做的:在Hive分析好一张最细粒度为visit_id(session_id)的事实表,字段及数据如下:

然后将这张事实表的数据加载到ElasticSearch中的logs2/sitelog1211中。查看数据:
curl -XGET 'http://localhost:9200/logs2/sitelog1211/_search?pretty'
{
"took" : 1015,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 3356328,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logs2",
"_type" : "sitelog1211",
"_id" : "AVGkoWowd8ibEMoyOhve",
"_score" : 1.0,
"_source":{"cookieid" : "8F97E07300BC7655F6945A","siteid" : "633","visit_id" : "feaa25e6-3208-4801-b7ed-6fa45f11ff42","pv" : 2,"is_return_cookie" : 0,
"is_bounce_visit" : 0,"visit_stay_times" : 34,"visit_view_page_cnt" : 2, "region" : "浙江","city" : "绍兴"}
},
……
该天事实表中总记录数为3356328。
接着使用下面的查询,完成了上图中网站ID为1127,日期为2015-12-11的流量报告:
curl -XGET 'http://localhost:9200/logs2/sitelog1211/_search?search_type=count&q=siteid:1127&pretty' -d '
{
"size": 0,
"aggs" : {
"pv" : {"sum" : { "field" : "pv" } },
"uv" : {"cardinality" : {"field" : "cookieid" ,"precision_threshold": 40000}},
"return_uv" : {
"filter" : {"term" : {"is_return_cookie" : 1}},
"aggs" : {
"total_return_uv" : {"cardinality" : {"field" : "cookieid" ,"precision_threshold": 40000}}
}
},
"visits" : {"cardinality" : {"field" : "visit_id" ,"precision_threshold": 40000}},
"total_stay_times" : {"sum" : { "field" : "visit_stay_times" }},
"bounce_visits" : {
"filter" : {"term" : {"is_bounce_visit" : 1}},
"aggs" : {
"total_bounce_visits" : {"cardinality" : {"field" : "visit_id" ,"precision_threshold": 40000}}
}
}
}
}'
基本上1~2秒就可以返回结果:
{
"took" : 1887,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 5888,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"uv" : {
"value" : 5859
},
"visits" : {
"value" : 5889
},
"return_uv" : {
"doc_count" : 122,
"total_return_uv" : {
"value" : 119
}
},
"bounce_visits" : {
"doc_count" : 5177,
"total_bounce_visits" : {
"value" : 5177
}
},
"pv" : {
"value" : 10820.0
},
"total_stay_times" : {
"value" : 262810.0
}
}
}
接着是地域报告中维度为省份的指标统计,查询语句为:
curl -XGET 'http://localhost:9200/logs2/sitelog1211/_search?search_type=count&q=siteid:1127&pretty' -d '
{
"size": 0,
"aggs" : {
"area_count" : {
"terms" : {"field" : "region","order" : { "pv" : "desc" }},
"aggs" : {
"pv" : {"sum" : { "field" : "pv" } },
"uv" : {"cardinality" : {"field" : "cookieid" ,"precision_threshold": 40000}},
"return_uv" : {
"filter" : {"term" : {"is_return_cookie" : 1}},
"aggs" : {
"total_return_uv" : {"cardinality" : {"field" : "cookieid" ,"precision_threshold": 40000}}
}
},
"visits" : {"cardinality" : {"field" : "visit_id" ,"precision_threshold": 40000}},
"total_stay_times" : {"sum" : { "field" : "visit_stay_times" }},
"bounce_visits" : {
"filter" : {"term" : {"is_bounce_visit" : 1}},
"aggs" : {
"total_bounce_visits" : {"cardinality" : {"field" : "visit_id" ,"precision_threshold": 40000}}
}
}
}
}
}
}'
因为要根据省份分组,比之前的查询慢一点,但也是秒级返回:
{
"took" : 4349,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 5888,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"area_count" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2456,
"buckets" : [ {
"key" : "北京",
"doc_count" : 573,
"uv" : {
"value" : 568
},
"visits" : {
"value" : 573
},
"return_uv" : {
"doc_count" : 9,
"total_return_uv" : {
"value" : 8
}
},
"bounce_visits" : {
"doc_count" : 499,
"total_bounce_visits" : {
"value" : 499
}
},
"pv" : {
"value" : 986.0
},
"total_stay_times" : {
"value" : 24849.0
}
}, {
"key" : "山东",
"doc_count" : 368,
"uv" : {
"value" : 366
},
"visits" : {
"value" : 368
},
"return_uv" : {
"doc_count" : 9,
"total_return_uv" : {
"value" : 9
}
},
"bounce_visits" : {
"doc_count" : 288,
"total_bounce_visits" : {
"value" : 288
}
},
"pv" : {
"value" : 956.0
},
"total_stay_times" : {
"value" : 30266.0
}
},
……
这里需要说明一下,在ElasticSearch中,对于去重计数(COUNT DISTINCT)是基于计数估计(Cardinality),因此如果去重记录数比较大(超过40000),便可能会有误差,误差范围是0~2%。
例子2:用户标签的搜索统计
有一张数据表,存储了每个用户ID对应的标签,同样加载到ElasticSearch中,数据格式如下:
curl -XGET 'http://localhost:9200/lxw1234/user_tags/_search?&pretty'
{
"took" : 220,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 820165,
"max_score" : 1.0,
"hits" : [ {
"_index" : "lxw1234",
"_type" : "user_tags",
"_id" : "222222222222222",
"_score" : 1.0,
"_source":{"sex" : "女性","age" : "27到30岁","income" : "5000到10000","edu" : "本科",
"appcategory" : "娱乐类|1.0","interest" : "","onlinetime" : "9:00~12:00|1.0","os" : "IOS|1.0",
"hobby" : "游戏|28.57,房产|8.57,服饰鞋帽箱包|28.57,互联网/电子产品|5.71,家居|8.57,餐饮美食|5.71,体育运动|14.29","region" : "河南省"}
}
......
每个用户都有性别、年龄、收入、教育程度、兴趣、地域等标签,其中使用_id来存储用户ID,也是主键。
查询1:SELECT count(1) FROM user_tags WHERE sex = ‘女性’ AND appcategory LIKE ‘%游戏类%';
curl -XGET 'http://localhost:9200/lxw1234/user_tags/_count?pretty' -d '
{
"filter" : {
"and" : [
{"term" : {"sex" : "女性"}},
{"match_phrase" : {"appcategory" : "游戏类"}}
]
}
}'
返回结果:
{
"count" : 106977,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
}
}
查询2:先筛选,再分组统计:
SELECT edu,COUNT(1) AS cnt FROM user_tags WHERE sex = '女性' AND appcategory LIKE '%游戏类%' GROUP BY edu ORDER BY cnt DESC limit 10;
查询语句:
curl -XGET 'http://localhost:9200/lxw1234/user_tags/_search?search_type=count&pretty' -d '
{
"filter" : {
"and" : [
{"term" : {"sex" : "女性"}},
{"match_phrase" : {"appcategory" : "游戏类"}}
]
},
"aggs" : {
"edu_count" : {
"terms" : {
"field" : "edu",
"size" : 10
}
}
}
}'
返回结果:
{
"took" : 479,
"timed_out" : false,
"_shards" : {
"total" : 10,
"successful" : 10,
"failed" : 0
},
"hits" : {
"total" : 106977,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"edu_count" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ {
"key" : "本科",
"doc_count" : 802670
}, {
"key" : "硕士研究生",
"doc_count" : 16032
}, {
"key" : "专科",
"doc_count" : 1433
}, {
"key" : "博士研究生",
"doc_count" : 25
}, {
"key" : "初中及以下",
"doc_count" : 4
}, {
"key" : "中专/高中",
"doc_count" : 1
} ]
}
}
}
从目前的调研结果来看,ElasticSearch没有让人失望,部署简单,数据加载方便,聚合功能完备,查询速度快,目前完全可以满足我们的实时搜索、统计和OLAP需求,甚至可以作为NOSQL来使用,接下来再做更深入的测试。
另外,还有一个开源的SQL for ElasticSearch的框架Crate(crate.io),是在ElasticSearch之上封装了SQL接口,使得查询统计更加方便,不过SQL支持的功能有限,使用的ElasticSearch版本较低,后面试用一下再看。
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
