之前,我们的某一个业务用于实时日志收集处理的架构大概是这样的:
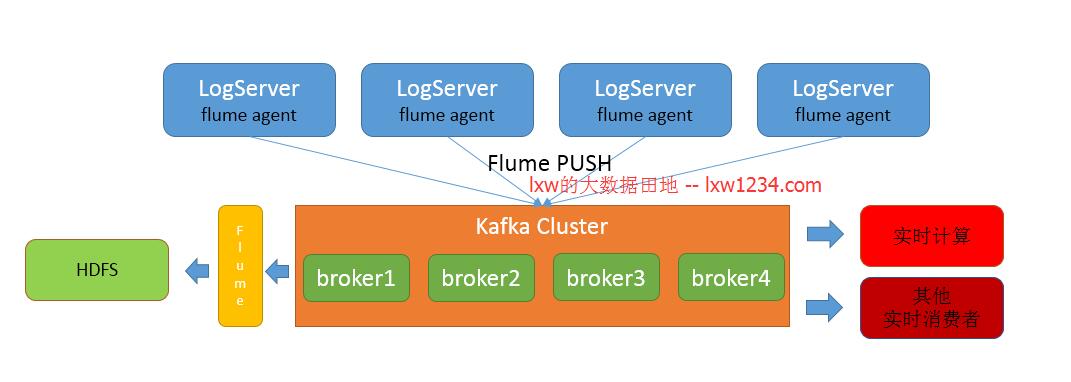
在日志的产生端(LogServer服务器),都部署了FlumeAgent,实时监控产生的日志,然后发送至Kafka。经过观察,每一个FlumeAgent都占用了较大的系统资源(至少会占用一颗CPU 50%以上的资源)。而另外一个业务,LogServer压力大,CPU资源尤其紧张,如果要实时收集分析日志,那么就需要一个更轻量级、占用资源更少的日志收集框架,于是我试用了一下Filebeat。
Filebeat是一个开源的文本日志收集器,采用go语言开发,它重构了logstash采集器源码,安装在日志产生服务器上来监视日志目录或者特定的日志文件,并把他们发送到logstash、elasticsearch以及kafka上。Filebeat是代替logstash-forwarder的数据采集方案,原因是logstash运行在jvm上,对服务器的资源消耗比较大(Flume也是如此)。正因为Filebeat如此轻量级,因此不要奢望它能在日志收集过程中做更多清洗和转换的工作,它只负责一件事,就是高效可靠的传输日志数据,至于清洗和转换,可以在后续的过程中进行。
Filebeat官网地址为:https://www.elastic.co/guide/en/beats/filebeat/current/index.html 你可以在该地址中下载Filebeat和查看文档。
Filebeat安装配置
Filebeat的安装和配置非常简单。
下载filebeat-5.6.3-linux-x86_64.tar.gz,并解压。
进入filebeat-5.6.3-linux-x86_64目录,编辑配置文件filebeat.yml
配置input,监控日志文件:
filebeat.prospectors: - input_type: log paths: - /data/dmp/openresty/logs/dmp_intf_*.log
配置output到Kafka
#—————————– Kafka output ——————————–
output.kafka: hosts: ["datadev1:9092"] topic: lxw1234 required_acks: 1
PS:假设你的Kafka已经安装配置好,并建了Topic。
更多的配置选项,请参考官方文档。
Filebeat启动
在filebeat-5.6.3-linux-x86_64目录下,执行命令:
./filebeat -e -c filebeat.yml 来启动Filebeat。
启动后,Filebeat开始监控input配置中的日志文件,并将消息发送至Kafka。
你可以在Kafka中启动Consumer来查看:
./kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic lxw1234 –from-beginning
Filebeat的消息格式
原始日志中,日志格式如下:
2017-11-09T15:18:05+08:00|~|127.0.0.1|~|-|~|hy_xyz|~|200|~|0.002
Filebeat会将消息封装成一个JSON串,除了包含原始日志,还包含了其他信息。
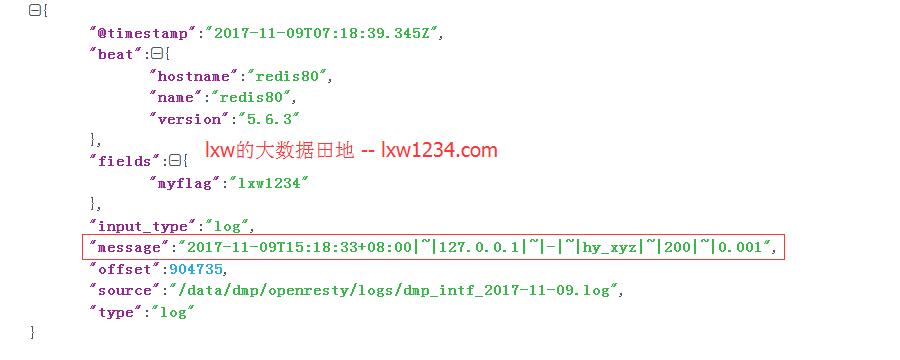
@timestamp:消息发送时间
beat:Filebeat运行主机和版本信息
fields:用户自定义的一些变量和值,非常有用,类似于Flume的静态拦截器
input_type:input类型
message:原始日志内容
offset:此条消息在原始日志文件中的offset
source:日志文件
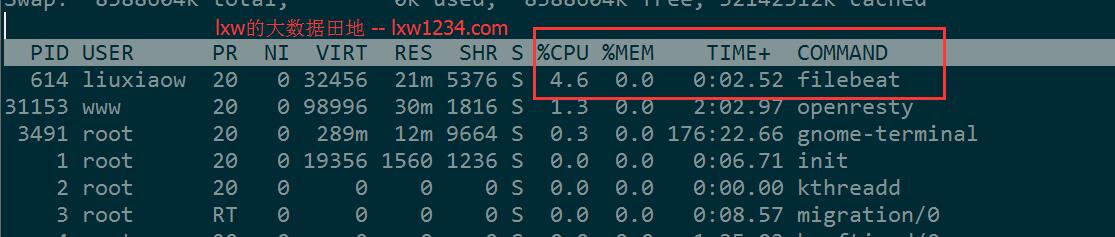
另外, Filebeat对CPU的占用情况:
经过初步试用,以下方面的问题还有待继续测试:
- 数据可靠性:是否存在日志数据丢失、重复发送情况;
- 能否对Filebeat的消息格式进行定制,去掉一些冗余无用的项。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 日志实时收集之FileBeat+Kafka
