Apache Storm是一个分布式的、可靠的、容错的实时数据流处理框架。它与Spark Streaming的最大区别在于它是逐个处理流式数据事件,而Spark Streaming是微批次处理,因此,它比Spark Streaming更实时。
一、Apache Storm的核心概念
- Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
- Worker:工作进程,每个工作进程中都有多个Task。
- Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
- Topology:计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
- Stream:数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
- Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout 能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout 可以发送多个数据流。
- Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
- Stream grouping:为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
- Reliability:可靠性。Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
二、Apache Storm的集群架构图
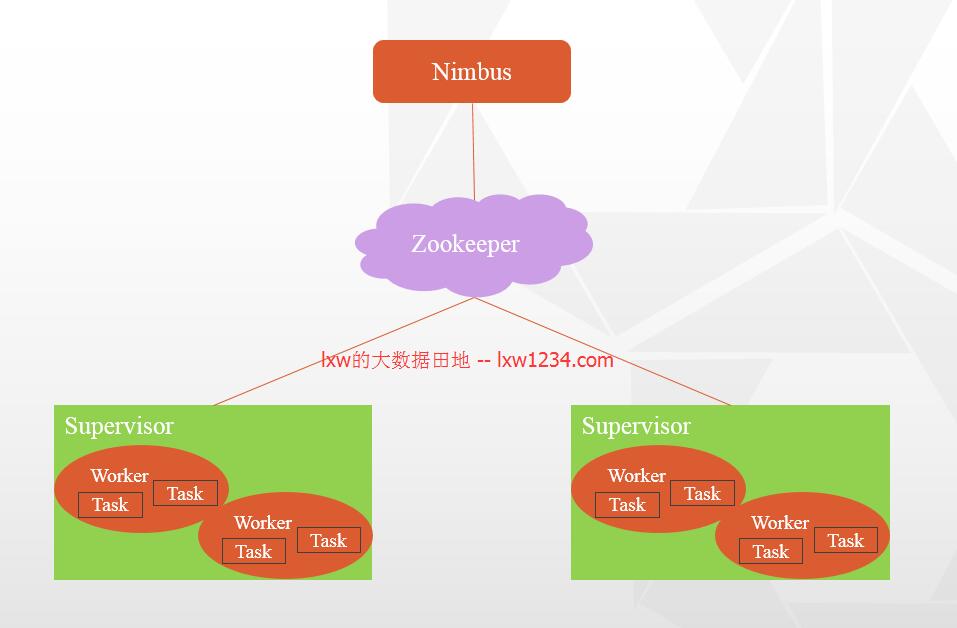
Zookeeper对于Storm集群来说至关重要,它负责Nimbus和Supervisor之间的通信。Nimbus从Zk中监控各个Supervisor的节点状态,通过ZK将任务分发下去。Supervisor会定时从Zk
中获取Topology、任务分配信息以及汇报心跳等等。
三、Apache Storm拓扑图
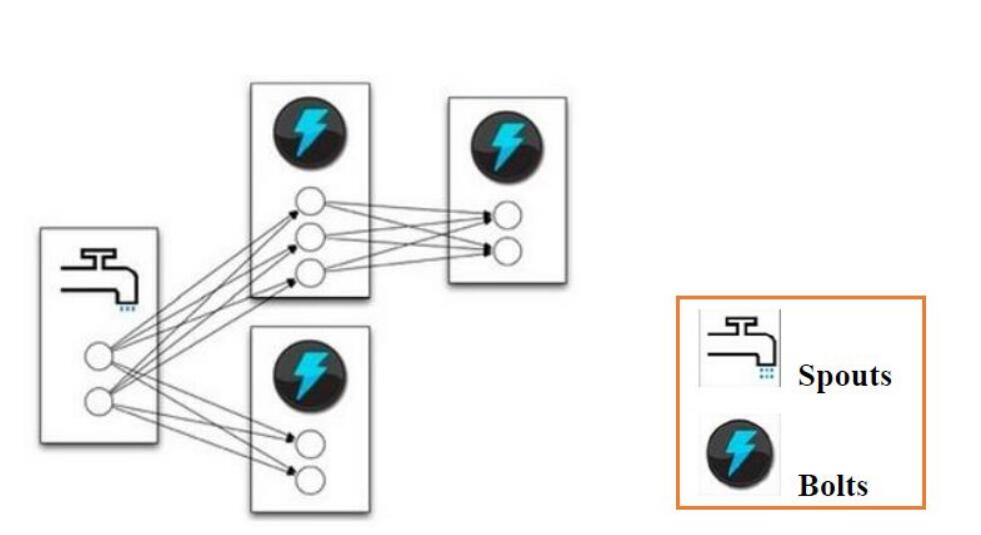
一个拓扑中可以有多个Spout和多个Bolt进行协作完成。
四、Apache Storm集群安装部署
4.1 软件环境
三台机器datadev1(Nimbus)、datadev2(Supervisor)、datadev3(Supervisor)
上面安装JDK1.7+、Python2.6.6、Zookeeper3.4.6、Apache Storm1.1.1
Storm安装目录位于/opt/storm/current
4.2 配置Storm
vi /etc/profile
export STORM_HOME=/opt/storm/current
export PATH=$STORM_HOME/bin:$PATH
cd $STORM_HOME/conf
vi storm.yaml
## Storm 关联的 ZooKeeper 集群的地址列表
storm.zookeeper.servers:
- "datadev1"
- "datadev2"
- "datadev3"
## Nimbus 和 Supervisor 后台进程都需要一个用于存放一些状态数据(比如 jar 包、配置文件等等)的目录
storm.local.dir: "/home/data/storm"
##用于配置主控节点的地址,可以配置多个。从Storm1.0开始,支持Nimbus的HA。
nimbus.seeds: ["datadev1"]
##配置每个 Supervisor 机器能够运行的工作进程(worker)数。每个 worker 都需要一个单独的端口来接收消息,
##这个配置项就定义了 worker 可以使用的端口列表。如果你在这里定义了 5 个端口,那么 Storm 就会在该机器上分配最多 5 个worker。
##如果定义 3 个端口,那 Storm 至多只会运行三个 worker。
supervisor.slots.ports:
- 6700
- 6701
- 6702
以上配置好后,将配置文件分发至其他节点。
4.3 启动Storm集群
在datadev1节点上启动Nimbus和UI:
cd $STORM_HOME/bin
nohup storm ui >/dev/null 2>&1 &
nohup storm nimbus >/dev/null 2>&1 &
在datadev2和datadev3节点上启动Supervisor:
nohup storm supervisor >/dev/null 2>&1 &
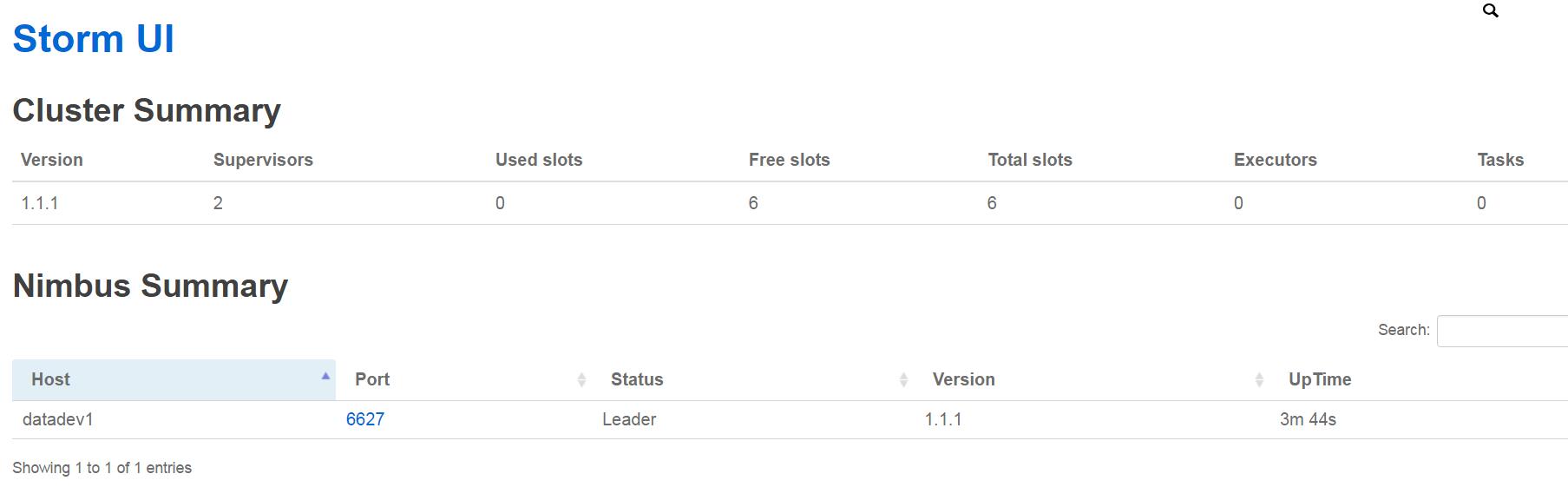
4.4 Storm UI
默认启动在8080端口,使用浏览器访问http://datadev1:8080

后续将继续介绍Storm的使用。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Apache Storm简介及安装部署
