本文转自Apache Kylin公众号apachekylin.
Superset 是一个数据探索和可视化平台,设计用来提供直观的,可视化的,交互式的分析体验。
Superset 提供了两种分析数据源的方式:
1. 用户可以以单表形式直接查询多种数据源,包括 Presto、Hive、Impala、SparkSQL、MySQL、Postgres、Oracle、Redshift、SQL Server、Druid 等。本文后续内容也会详细介绍Superset如何支持Kylin数据源。
2. 一个 SQL 的 IDE 供高级分析师使用 SQL 查询定义所需要分析的数据集,这种方法使用户在一个查询中实现用 Superset 查询数据源的多表,并立即对查询进行可视化分析。
Superset 的前世今生
Superset 起源于 2015 年初黑客马拉松项目,曾经使用过 Caravel 和 Panoramix 作为项目名。现在主要维护小组是 Airbnb 数据科学组,代码托管在 Github。作为 Apache 软件基金会孵化项目,Superset 目标是要做成数据可视化平台。
Superset 对于数据源端通过一个成熟的 OR-Mapping 方案对接了几乎市面上所有数据库产品,数据的分析和建模再使用 Pandas 统一加工序列化后由前端渲染展示. 进而前端渲染出众多富有表现力的可视化图表,这些可视化技术包括但不限于: D3,react stack,mapbox,deck.gl。
笔者在使用 Superset 过程中也感觉到一些不足,例如无法通过权限隔离不同用户可访问的数据源,数据查询暂时不支持下钻操作,多数据源不容易做交互查询等。但是瑕不掩瑜,Superset 依然是现在这个星球上最好的开源 BI 平台。
Apache Kylin 与 Superset 集成
交互式分析是 Apache Kylin 与 Superset 共同的产品目标,使用 Kylin 作为 Superset 查询,数据经过 Kylin Cube 的预计算处理,在 Superset 前端进行可视化分析想必是快到飞起,真可谓是强强联合。
Kyligence 数据科学小组开源了 kylinpy 项目完成了 Kylin 与 Superset 数据源的集成。现在我们就来手把手教读者实现 Kylin 和 Superset 的集成,并实现交互式的可视化分析。
准备工作
1. 安装 Apache Kylin
请参考 Apache Kylin installation guide:http://kylin.apache.org/docs23/
2. Apache Kylin 提供了样例 Cube,方便大家学习使用。Kylin 启动成功后,可以在 Kylin 安装路径下运行以下命令生成样例数据 Cube:
./${KYLIN_HOME}/bin/sample.sh
运行后,使用默认的 Kylin 账号 ADMIN / KYLIN 登陆界面,在 System 页面点击 Reload Metadata 即可看到样例项目 Learn_kylin。
选择样例 Cube “Kylin_sales_cube”,点击 Action -> Build。选择日期不要晚于 2014-01-01 来进行全量构建。
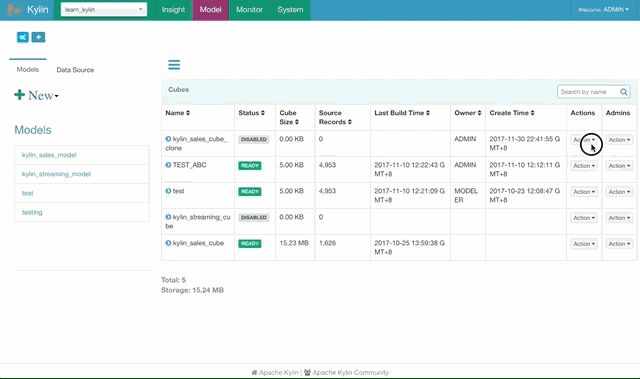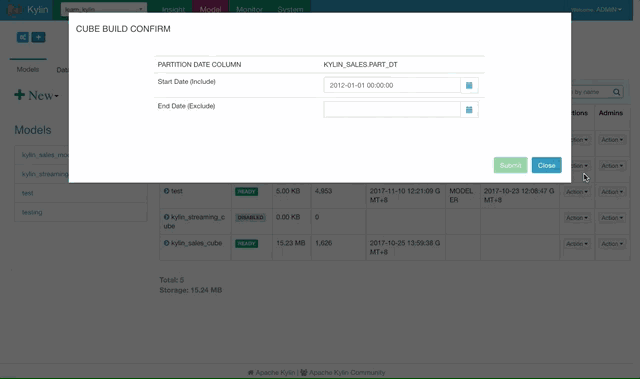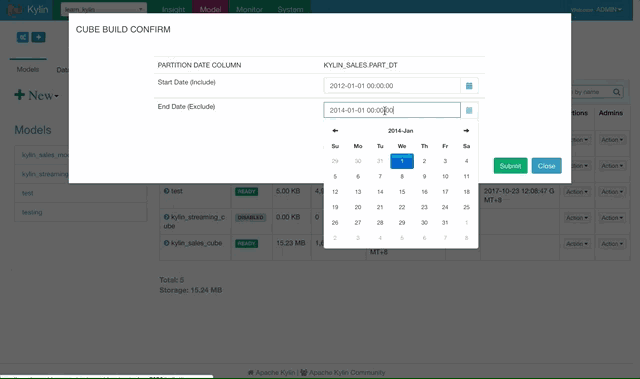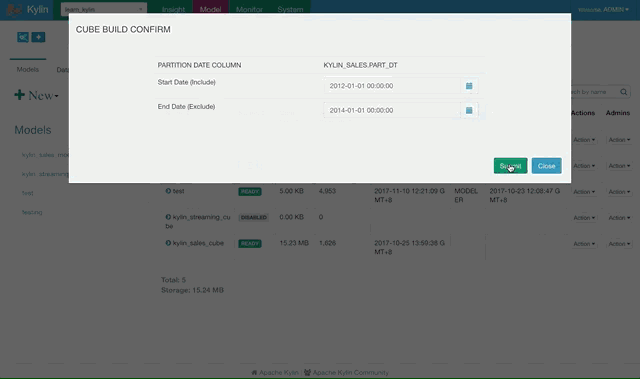
点击前往 Monitor 页面查看 Cube 构建的进程,知道100%完成,Cube 就可以进行查询了。
前往 Insight 页面执行一个查询验证 Cube 能够返回结果。
select part_dt,
sum(price) as total_selled,
count(distinct seller_id) as sellers
from kylin_sales
group by part_dt
order by part_dt
查询会击中新构建的 Kylin_sales_cube。
3. 下面我们安装 Superset,并初始化。
强烈建议使用虚拟环境来安装所有的依赖包(virtualenv/virtualenvwrapper)
通过 PyPi 仓库安装 superset
pip install superset
创建初始超级用户: admin/admin
fabmanager create-admin –app superset –username admin –password admin –firstname admin –lastname admin –email admin@fab.org
使用默认 sqllite metadata,位于 $HOME/.superset/superset.db,并且根据 migrate 创建表结构
superset db upgrade
初始化 role 等
superset init
执行如上4条命令便可以在 POSIX 操作系统上部署 Superset,如想加载 Superset提供的例子数据,可以再执行
superset load_examples
4. 安装 kylinpy
pip install kylinpy
5. 安装验证,如果一切顺利,Superset daemon应该可以跑起来了
-d 选项可以打开 debug 模式
superset runserver -d
Starting server with command:
gunicorn -w 2 –timeout 60 -b 0.0.0.0:8088 –limit-request-line 0 –limit-request-field_size 0 superset:app
[2018-01-03 15:54:03 +0800] [73673] [INFO] Starting gunicorn 19.7.1
[2018-01-03 15:54:03 +0800] [73673] [INFO] Listening at: http://0.0.0.0:8088 (73673)
[2018-01-03 15:54:03 +0800] [73673] [INFO] Using worker: sync
[2018-01-03 15:54:03 +0800] [73676] [INFO] Booting worker with pid: 73676
[2018-01-03 15:54:03 +0800] [73679] [INFO] Booting worker with pid: 73679
….
建立连接
现在所有的准备工作已经完毕,我们来试试在 Superset 中创建一个 Apache Kylin 数据源。
1. 浏览器打开 http://localhost:8088 帐号密码是刚才 fabmanager 创建的 admin/admin。

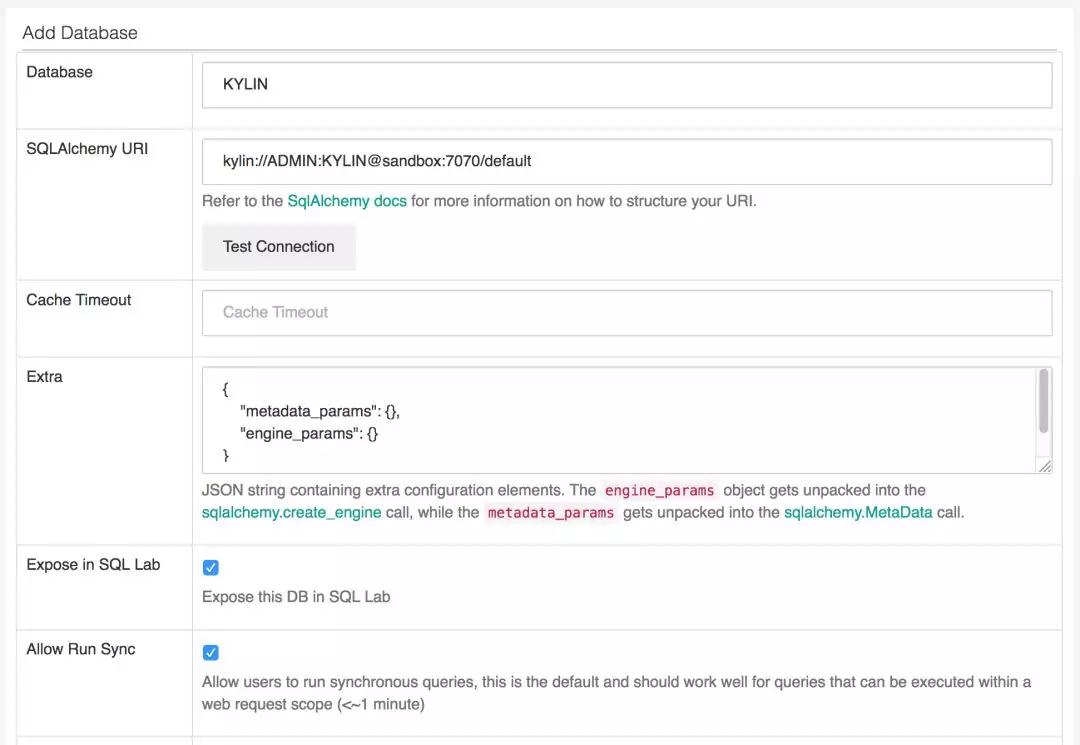
点击 Source —> Datasource,如下配置,注意如下几点:
- SQLAlchemy URI 格式为:
kylin://<username>:<password>@<hostname>:<port>/<project name>
- 勾选 Expose in SQL Lab 后这个数据源便可以在 SQL Lab 中展示出来。
- 点击 Test Connection 可以测试链接是否成功。
创建 Kylin 数据源
测试连接
查询 Kylin 表单
连接成功后页面最下会展示这个 Kylin 项目内所有的表。
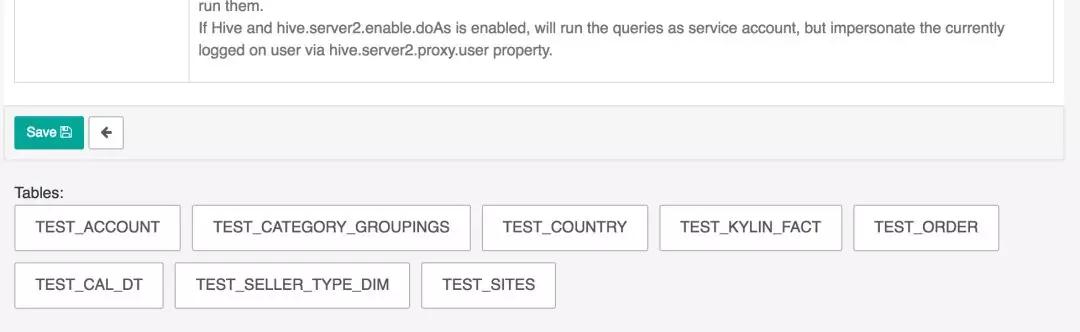
1. 点击 Source —> Tables,添加 Table,此处需要手动输入需要添加的表名。
 2. 在所有列表中选定相应的表,就可以开始查询之旅啦。
2. 在所有列表中选定相应的表,就可以开始查询之旅啦。
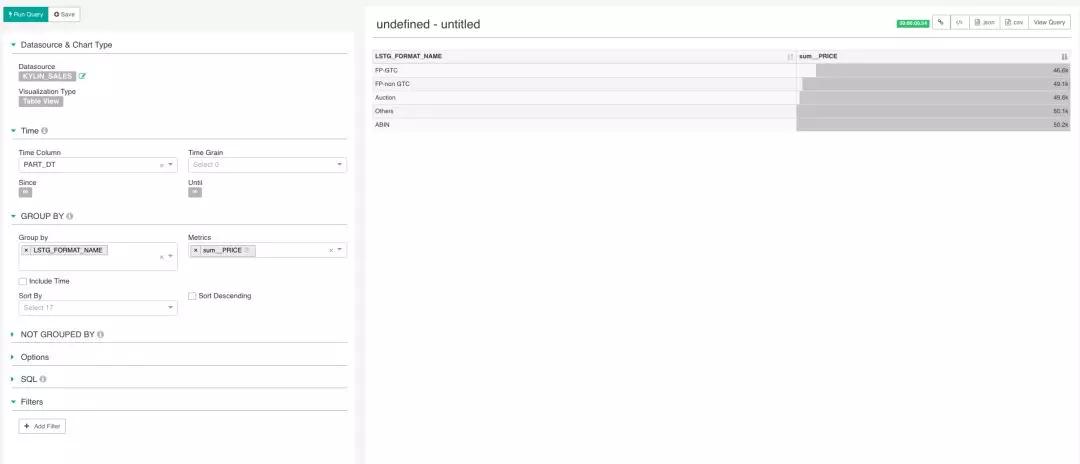
使用 SQL Lab 查询 Apache Kylin 多表
熟悉 Kylin 的读者都知道,Kylin Cube 通常都是以多表关联建模为基础生成的,因此分析 Kylin Cube 的数据时,使用多表进行查询对于 Kylin 来说是非常常见的场景。在使用 Superset 分析 Kylin 数据时,我们可以使用 Superset 中的 SQL Lab 功能来查询多表,并对其进行可视化分析。
在这里我们以一个可以击中 Kylin 中的 sample cube ‘kylin_sales_cube’ 的查询为例。

查询返回后点击可视化按键即可针对当前查询进行可视化分析。
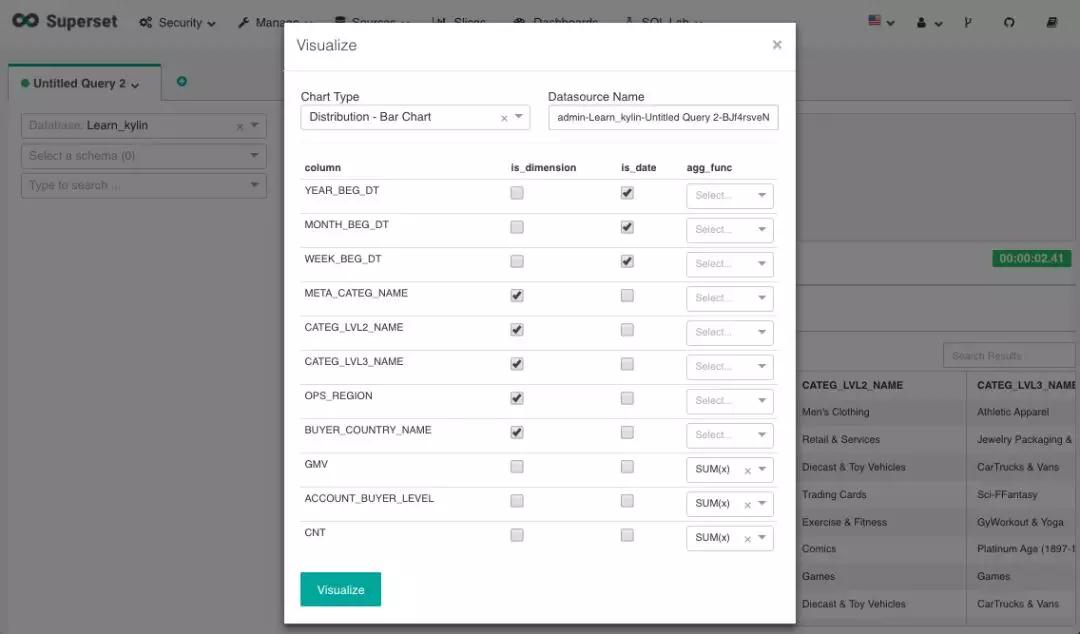
你可以复制下面的完整查询来体验 SQL Lab 查询 Kylin Cube 的功能。
select YEAR_BEG_DT,
MONTH_BEG_DT,
WEEK_BEG_DT,
META_CATEG_NAME,
CATEG_LVL2_NAME,
CATEG_LVL3_NAME,
OPS_REGION,
NAME as BUYER_COUNTRY_NAME,
sum(PRICE) as GMV,
sum(ACCOUNT_BUYER_LEVEL) ACCOUNT_BUYER_LEVEL,
count(*) as CNT
from KYLIN_SALES
join KYLIN_CAL_DT
on CAL_DT=PART_DT
join KYLIN_CATEGORY_GROUPINGS
on SITE_ID=LSTG_SITE_ID
and KYLIN_CATEGORY_GROUPINGS.LEAF_CATEG_ID=KYLIN_SALES.LEAF_CATEG_ID
join KYLIN_ACCOUNT
on ACCOUNT_ID=BUYER_ID
join KYLIN_COUNTRY
on ACCOUNT_COUNTRY=COUNTRY
group by YEAR_BEG_DT,
MONTH_BEG_DT,
WEEK_BEG_DT,
META_CATEG_NAME,
CATEG_LVL2_NAME,
CATEG_LVL3_NAME,
OPS_REGION,
NAME
使用 Superset 的多种功能查询 Apache Kylin
根据很多 Apache Kylin 用户在对接可视化及报表分析前端时,所提出的一些常见需求,我们对Superset 的相应功能也做了一些测试,可以说企业对于报表分析及可视化展现所需要的绝大部分功能,Superset 都已经可以提供了。
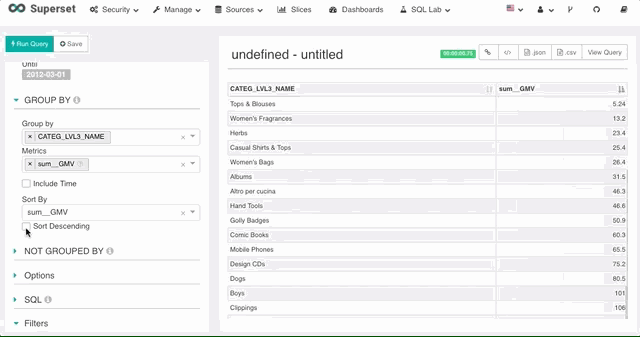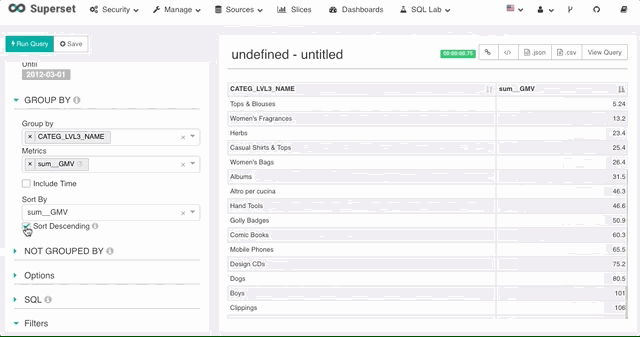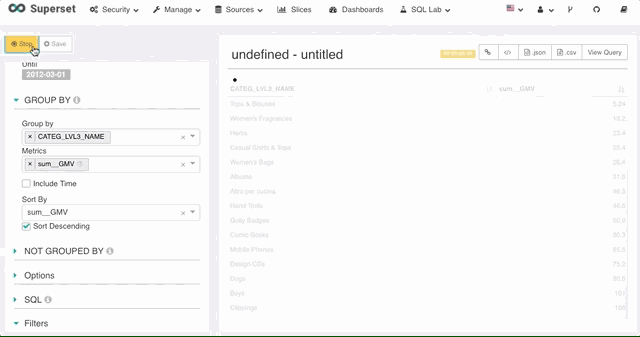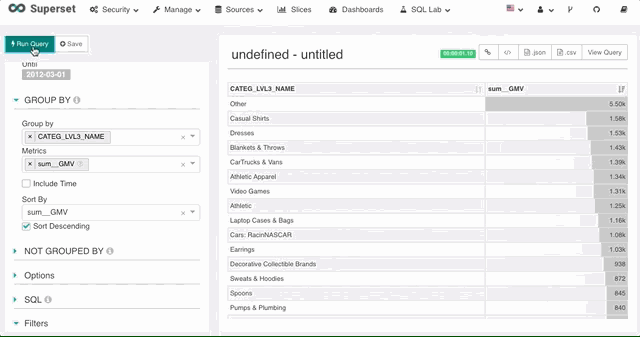
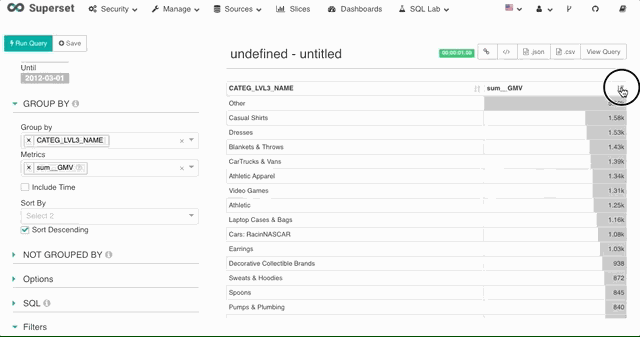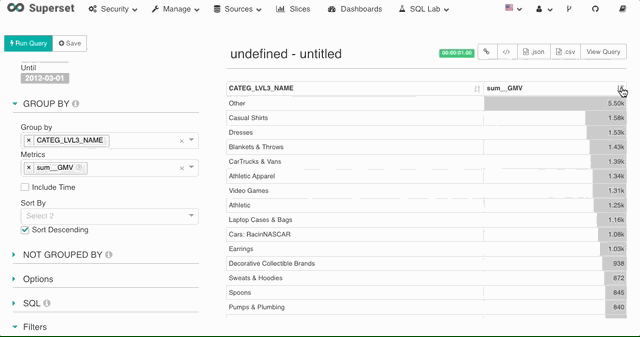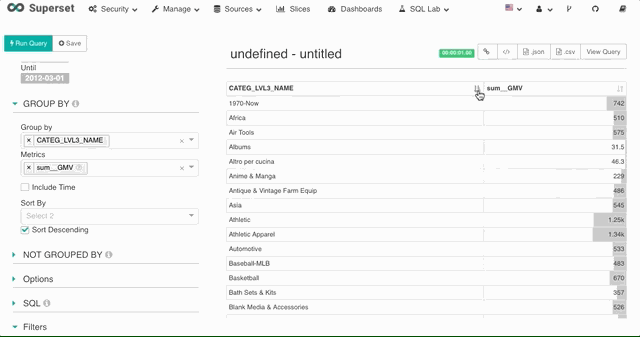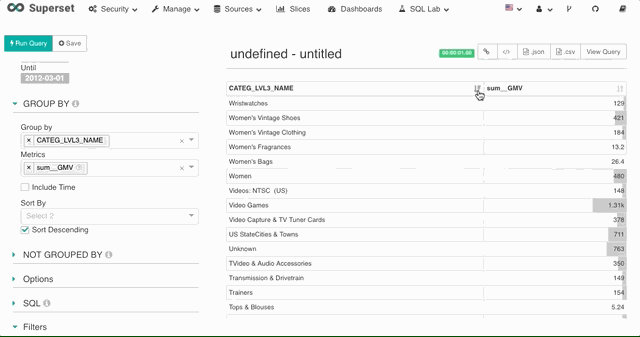
排序
Superset 支持使用任意数据源上定义的度量进行排序,不论这个度量是否在图表上。
过滤功能
在 Superset 中有多种过滤功能都可以使用在对 Kylin 的查询中。
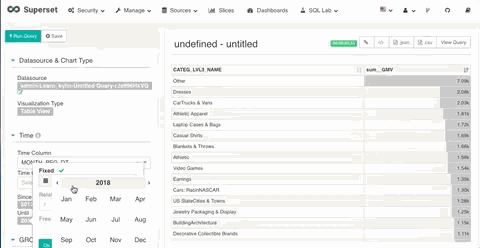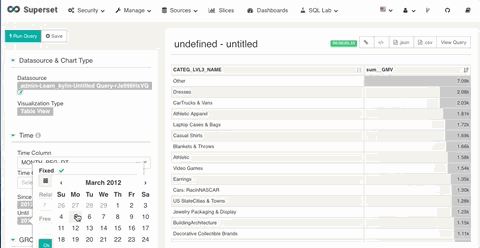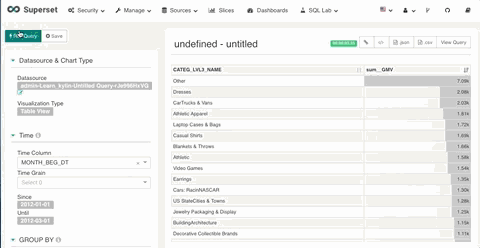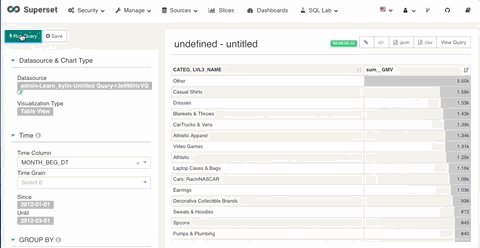
1. 日期过滤
在 Superset 中你可以对定义为时间列的维度进行日期和时间的过滤。
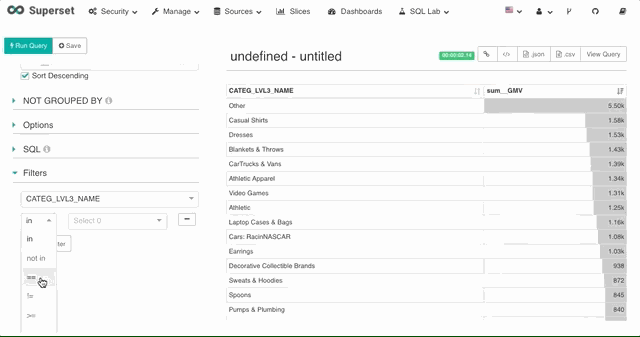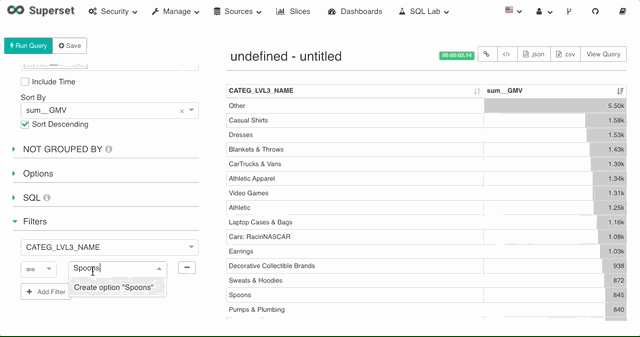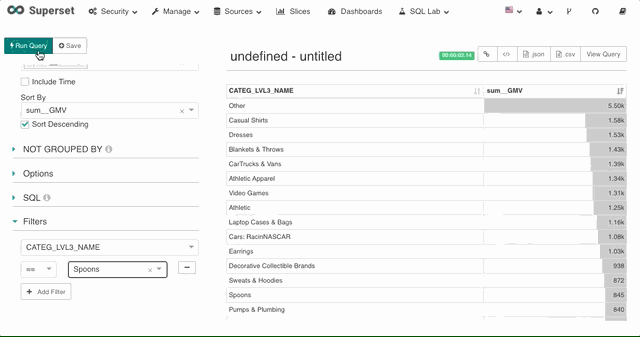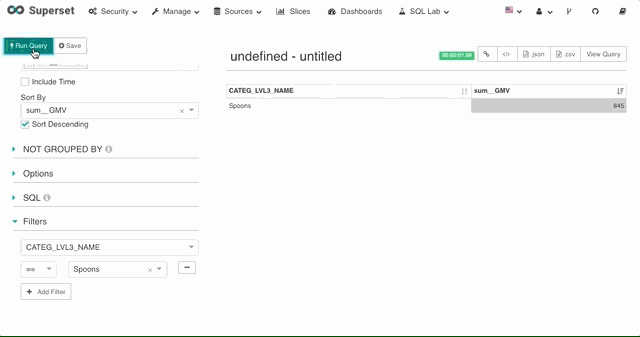
 2. 维度过滤
2. 维度过滤
对于其他非时间维度,Superset 也提供了维度的筛选器,支持 SQL 中的 in,not in,等于,不等于,大于等于,小于等于,小于,大于,like 等多种过滤方式。
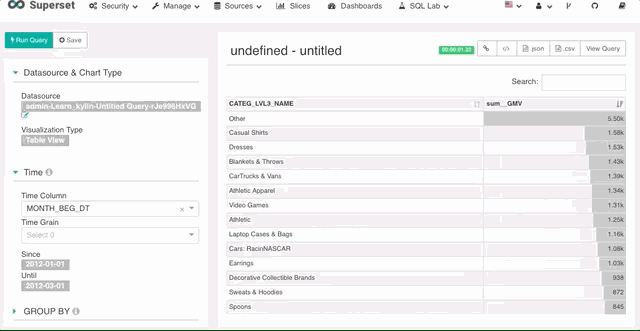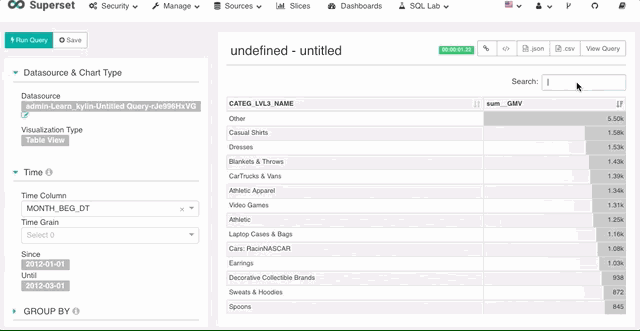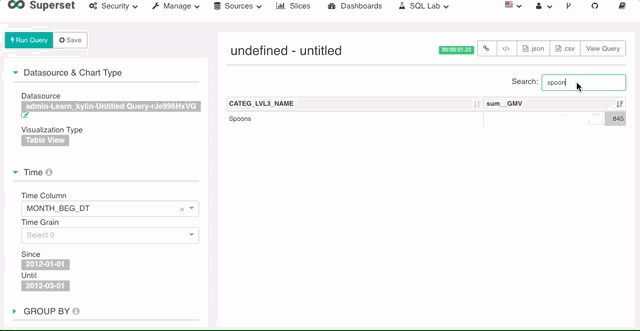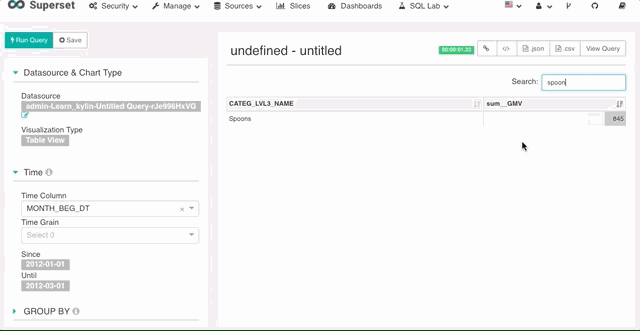
 3. 报表内搜索
3. 报表内搜索
你可以在报表返回后使用搜索框功能对数据进行筛选。
 4. 度量过滤
4. 度量过滤
对于度量 Superset 支持用户直接写入 SQL 的having 表达式。
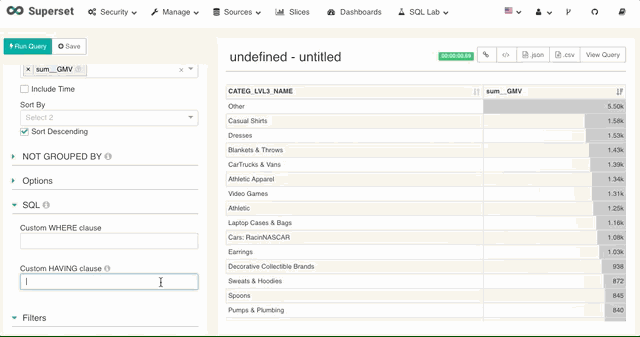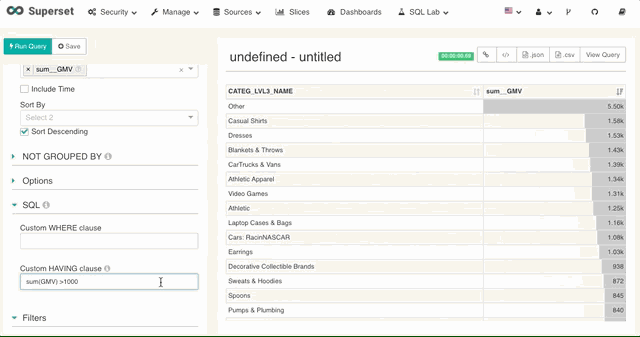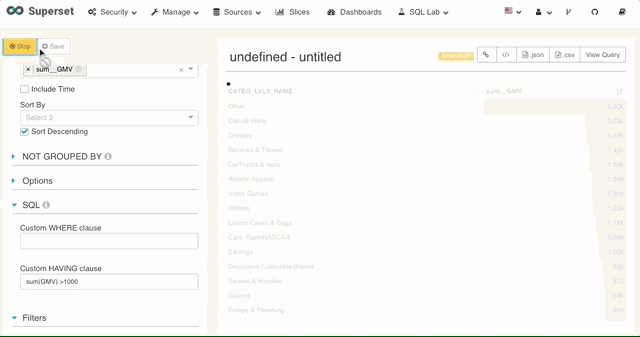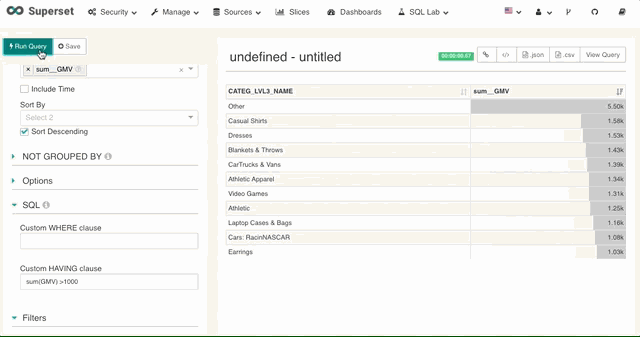 5. 联动过滤
5. 联动过滤
使用 Superset 中提供的过滤框可视化组件,可以实现一个过滤器联动过滤多个可视化图形的效果。
如下图,过滤框组件可以联动控制仪表盘上的所有可视化图形。
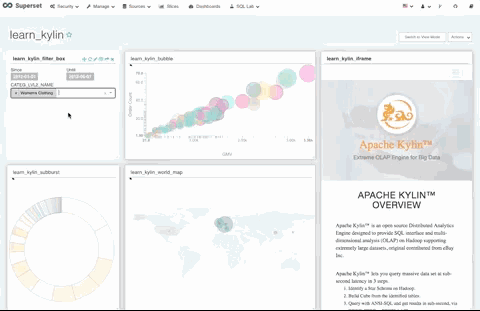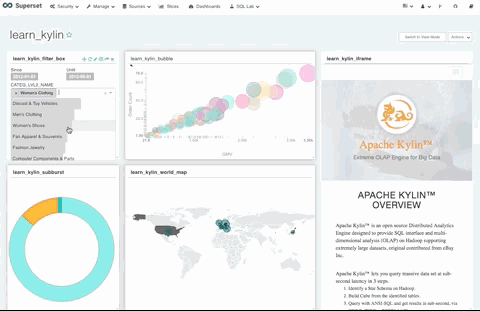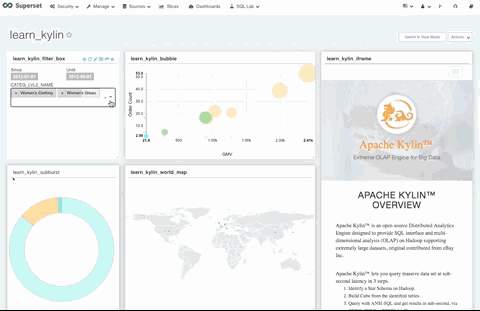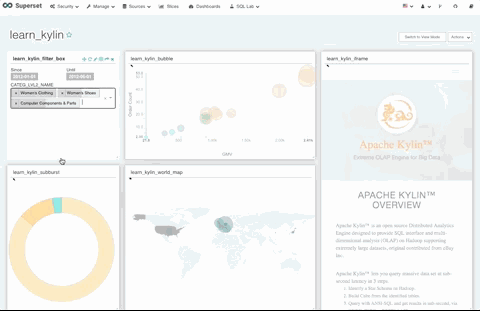 6. Top N
6. Top N
你可以通过对数据进行排序和设置返回行数限制来实现展示 Top 10/Bottom 10 等功能。
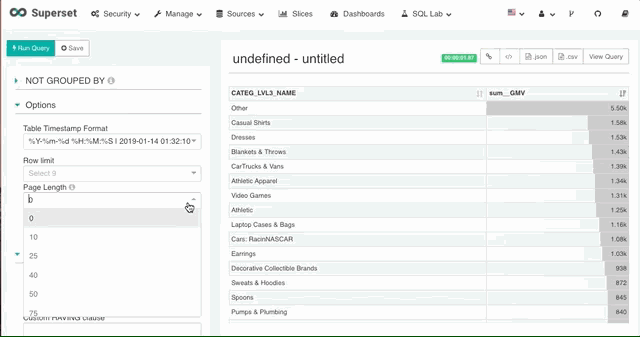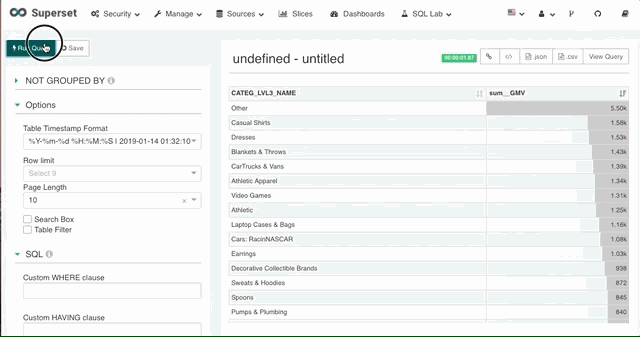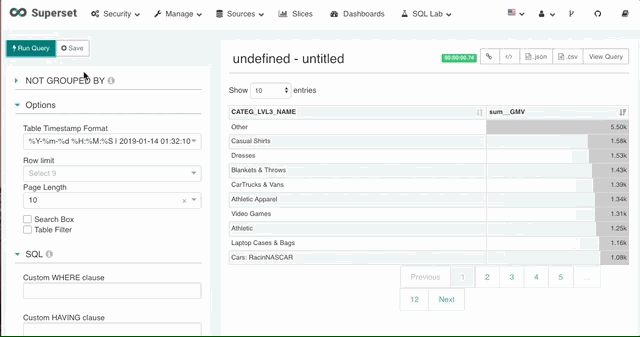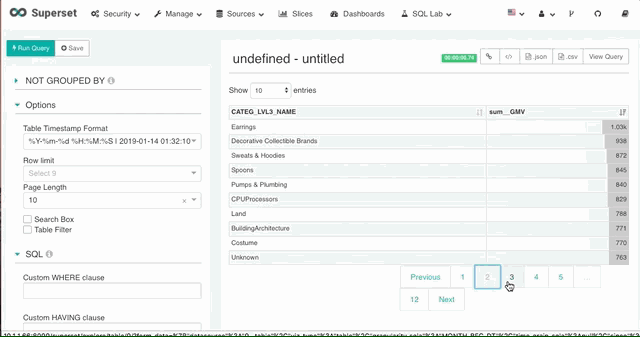
 7. 分页
7. 分页
在返回的数据量较大时,Superset 支持设置每页数据行数实现数据的分页。
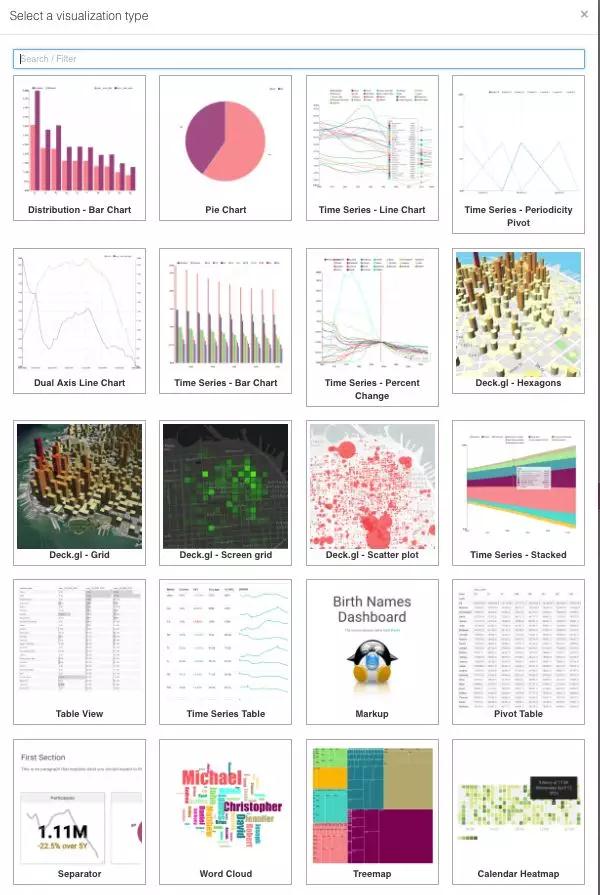
8. 多种可视化
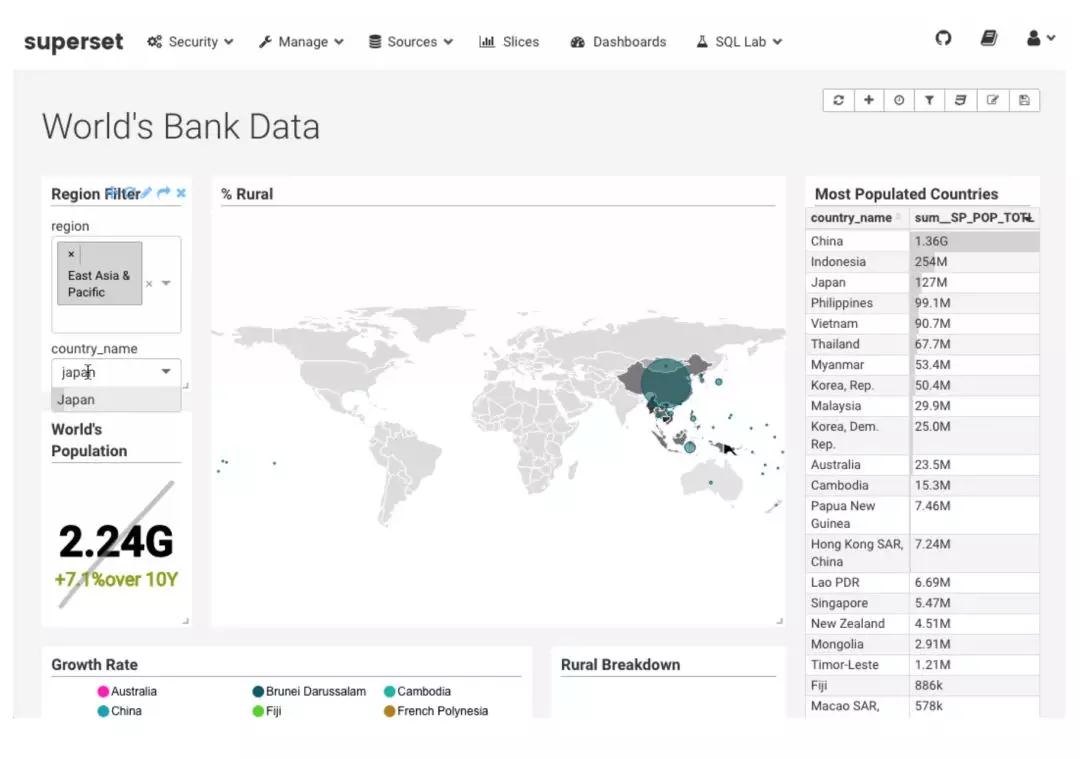
Superset 提供多样的可视化图表选择,这里仅以世界地图和气泡图为例作为展示。
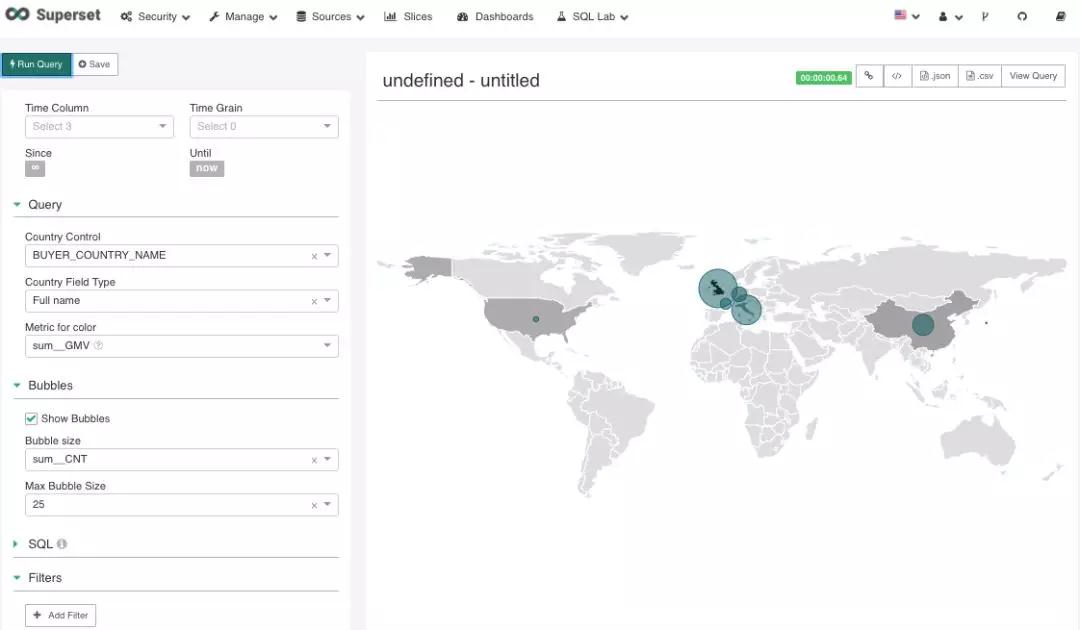
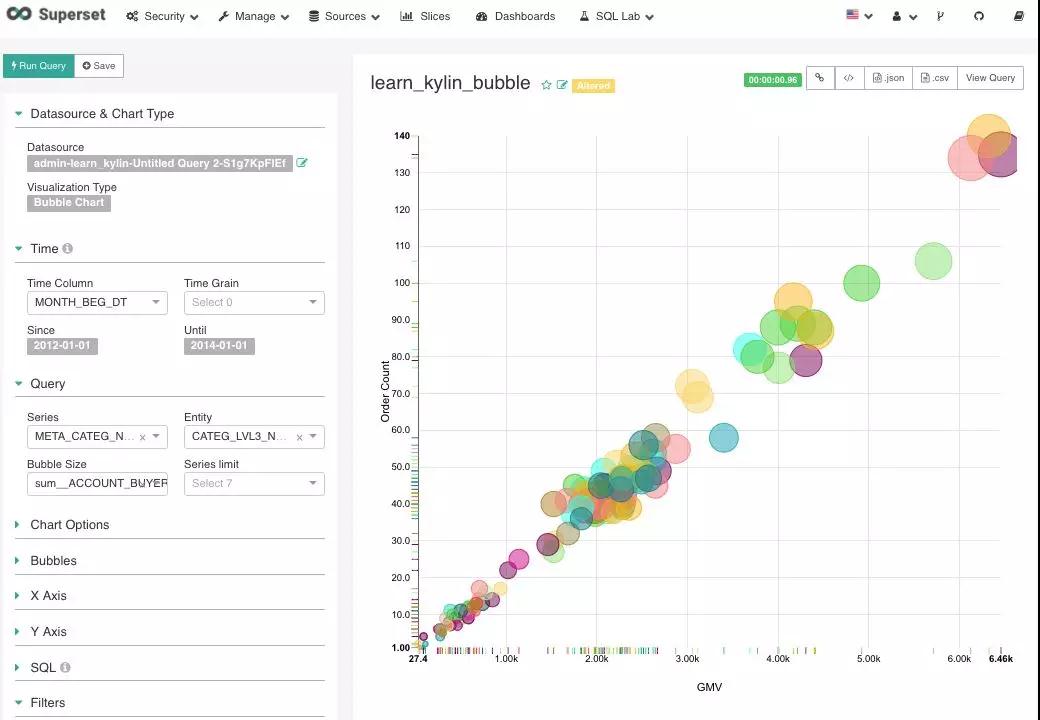
另外 Superset 还支持数据导出 CSV,报表分享,查看报表 SQL 等功能。
Superset 使用了 Flask 的翻译扩展工具 Flask-Babel(http://packages.python.org/Flask-Babel/) ,使用了这个扩展包后,每个对应的语言版本只需要在翻译文件中将对应的 Superset 文字翻译成中文即可,这使得 Superset 社区的中文用户可以很容易的贡献翻译内容。
总结
多个开源项目的结合往往能产生1+1>2的效果,Kylin 专注于 OLAP 计算引擎,Superset 专注于数据可视化展现. 分析师手中的双剑合璧实现交互式分析,让企业使用大数据技术显著提升生产力。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 官方教程:Apache Kylin和Superset集成,使用开源组件,完美打造OLAP系统
