关键字:互联网、大数据、数据仓库、数据平台、架构
导读:
- 整体架构
- 数据采集
- 离线计算
- 实时计算
- 多维分析OLAP
- 机器学习
- Ad-Hoc查询
- 数据可视化
上次写的《大数据环境下互联网行业数据仓库/数据平台的架构之漫谈》一文,已是一年前的事了,经过一年的沉淀与公司业务的发展,大数据平台的架构也有所演进,本文简单介绍了架构更新的部分。
整体架构
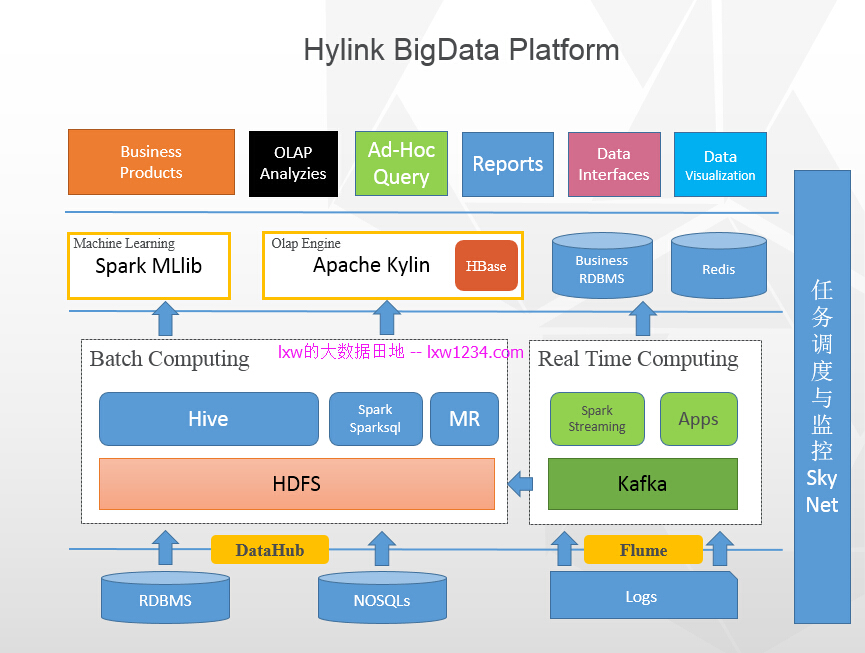
数据采集
对于关系型数据库以及部分NOSQL(Redis、MongoDB)中的数据,仍然使用DataHub按天、按小时,增量抽取到HDFS,映射到Hive表;
对于日志数据,使用Flume从日志收集服务器实时抽取到Kafka,再使用Flume,从Kafka抽取到HDFS,映射到Hive表;
离线计算
离线计算%80以上使用Hive,部分新业务使用SparkSQL,很少一部分老的业务仍然使用MR;
离线计算的结果,根据业务用途不同,分别保存在Hive、Redis以及业务关系型数据库中;
实时计算
实时计算使用Spark Streaming以及部分Java程序消费Kafka中收集的日志数据,实时计算结果大多保存在Redis中;
多维分析OLAP
之前基本采用固定报表、固定计算、临时数据提取等方式来满足业务数据分析的需求,随着业务发展,该模式的成本越来越大,也存在很多问题。
现在使用Kylin作为OLAP引擎,数据开发人员在Hive数据仓库中设计好事实表,维度表,在Kylin中设计好Cube,每天将数据由Hive加载到Kylin,数据分析、产品运营通过Kylin来完成90%以上的数据分析需求,对于一些特别复杂和定制的需求,才会提临时需求给数据开发。
另外,使用Caravel经过简单的二次开发,作为OLAP的前端,用户不用写SQL,即可完成数据多维分析与可视化。
机器学习
目前只使用了Spark MLlib提供的机器学习算法,完成了文本分类的需求。
Ad-Hoc查询
在Hive的基础上,也提供了SparkSQL的方式,主要是给数据开发以及懂SQL的数据分析和运营提供更快的Ad-Hoc查询响应。
数据可视化
基于Caravel做了二次开发,提供近20种数据可视化图表。
底层基于DataHub、Kylin,用户还可以自助数据接入、自助建模、自助分析与可视化。
PS:架构中介绍的所有组件,在我的博客中都能找到相关的文章,请关注我的博客。
如果觉得本博客对您有帮助,请 赞助作者 。

