一站式用户自助数据接入与分析平台,也可以当做一个提供大数据分析服务的云平台,用户可以基于平台数据仓库中已有的事实表和维度表(有访问权限),自助建立分析模型,进行OLAP分析与可视化;也可以将自己的数据接入到平台,在已接入的数据上自助建立分析模型,进行OLAP分析与可视化。对于前者(大多是内部用户)来说,它是一个自助分析平台,而对于后者(大多是外部用户)来说,它是一个大数据分析云服务平台;
整体设计
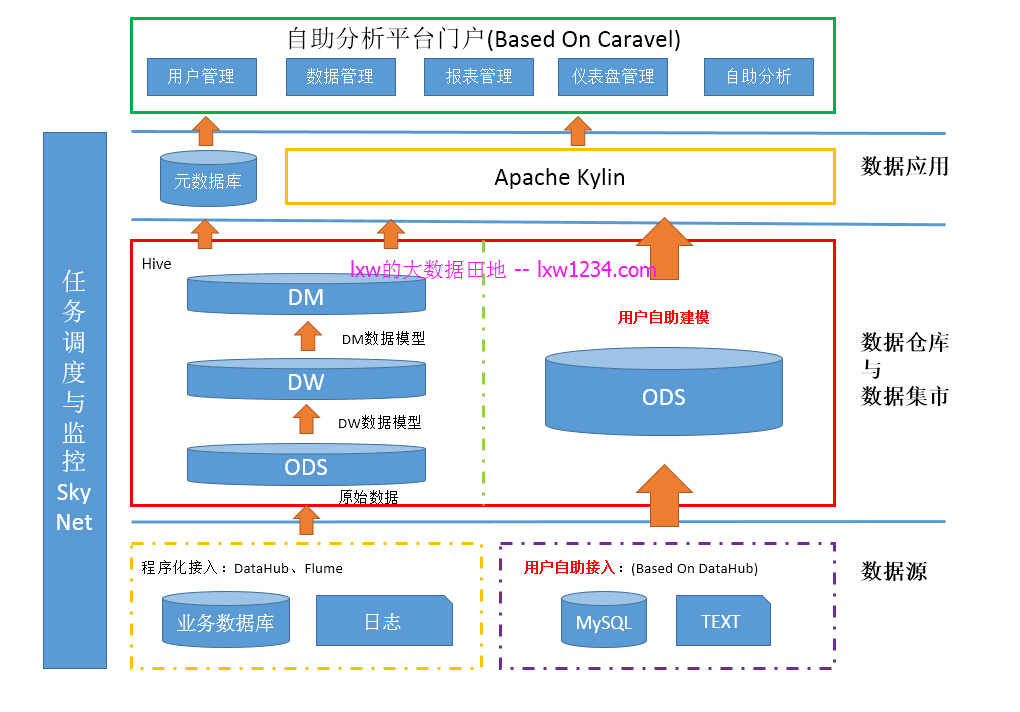
平台使用的组件(关于各组件介绍请参考文章最后的相关阅读):
- 数据仓库存储与计算:Hive/Hadoop/SparkSQL
- OLAP引擎:Apache Kylin
- 前端UI与图表可视化:Caravel(二次开发)
- 任务调度与监控:SkyNet
- 自助数据接入:DataHub(基于DataX二次开发)
外部数据自助接入与分析
即架构图中右侧部分,包含自助接入、自助建模、自助分析三个步骤。
自助接入数据
基于DataHub,用户可以将自己的关系型数据库(MySQL、Oracle、SQLServer等)和本地文本文件接入到平台;
数据库数据接入时候需要填写IP、PORT、数据库、用户名、密码、SCHEMA、表名等,测试连接后,自动获取该表的字段及数据类型,用户可以选择需要接入哪些字段,是否分区,一次性接入还是按天增量接入等;另外,用户也可以通过自定义SQL来作为数据源。
提交之后,后台在调度系统中创建相应的DataHub任务,完成由用户数据库到Hive表的数据交换;在这期间,平台可以通过调用调度系统的API来获取接入任务的状态。
文本数据接入时候需要上传文件,并填写文本中字段分隔符、字段名、字段数据类型等,提交之后,后台将上传的文本文件Load到Hive表中。
自助建模
当数据成功接入到平台(Hive表)之后,用户可以基于自己接入的Hive表来建模,建模包括以下内容:
定义表中那些字段作为维度(GroupBy);
定义表中那些维度字段可以过滤(Filterable);
自己使用SQL表达式新增一个维度字段;
定义表中哪些字段作为指标,以及指标的计算类型(SUM、MAX、MIN、AVG、COUNT、COUNT DISTINCT);
自己使用SQL表达式新增一个指标字段;
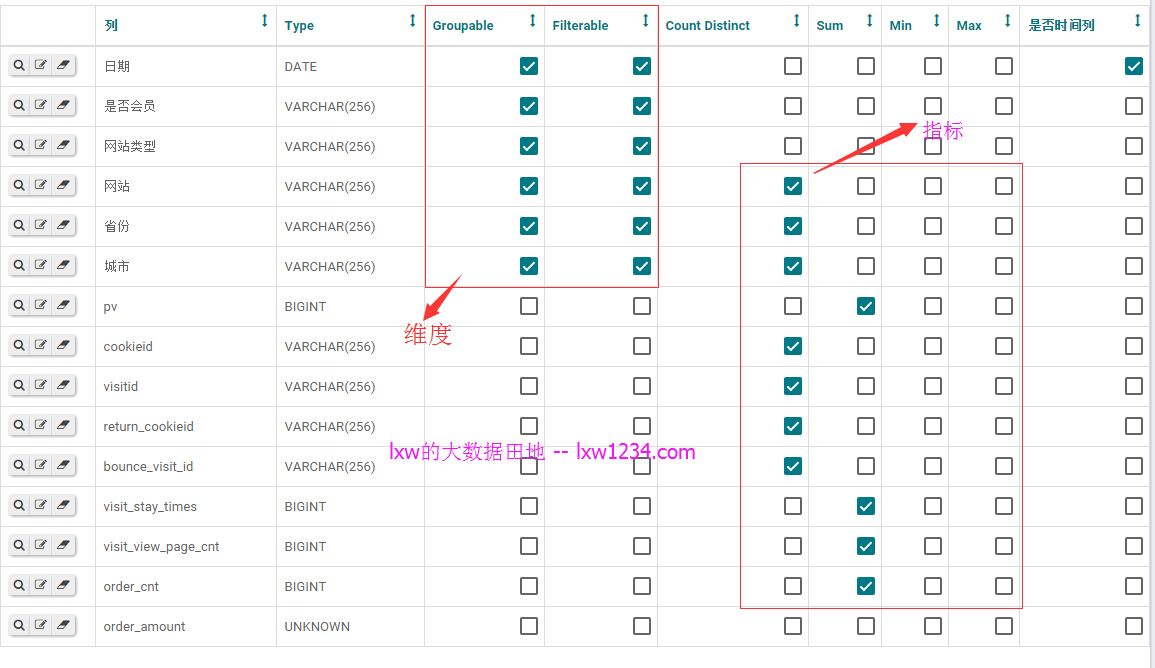
提交建模之后,根据用户的模型,使用Kylin的API,首先Load Hive Table、创建Model、创建Cube,然后在调度系统中创建Build Cube的任务,并提交运行Build Cube,同样平台可以通过调用调度系统的API来获取Build Cube任务的状态。
当Build Cube任务成功结束后,平台将模型信息写入到Caravel的元数据中。
自助分析
建模完成后,用户就可以在平台门户(Caravel)中看到该数据模型;可以基于此模型进行自助分析与可视化、创建数据图表(Slice)、创建仪表盘(DashBoard)等。
内部数据自助分析
内部数据处理流程,即架构图中左侧部分,是一个标准的数据仓库数据处理流程,
从数据源–>ODS–>DW–>DM,按照事先设计的数据模型,增量刷新即可。
为自助分析平台提供的数据源,即包括DW的事实表和维表,也报过DM的汇总表(多为视图形式);用户登陆自助分析平台之后,可以基于有访问权限的事实表或汇总表自助建立模型、自助分析;
自助建模与自助分析的过程与前面外部数据一致,只是少了一步数据接入。
相关阅读
OLAP 引擎 Apache Kylin:分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例
前端UI与图表可视化:Caravel:Caravel–一款开源OLAP+数据可视化分析前端工具,支持Druid和Kylin
任务调度与监控:SkyNet:大数据平台任务调度与监控系统
自助数据接入:DataHub:异构数据源海量数据交换工具-Taobao DataX 下载和使用
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 一站式用户自助数据接入与分析平台

