本文从apachekylin公众号系列文章整理。
随着维度数目的增加,Cuboid 的数量会爆炸式地增长。为了缓解 Cube 的构建压力,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等。”
众所周知,Apache Kylin 的主要工作就是为源数据构建 N 个维度的 Cube,实现聚合的预计算。理论上而言,构建 N 个维度的 Cube 会生成 2N 个 Cuboid, 如图 1 所示,构建一个 4 个维度(A,B,C, D)的 Cube,需要生成 16 个Cuboid。
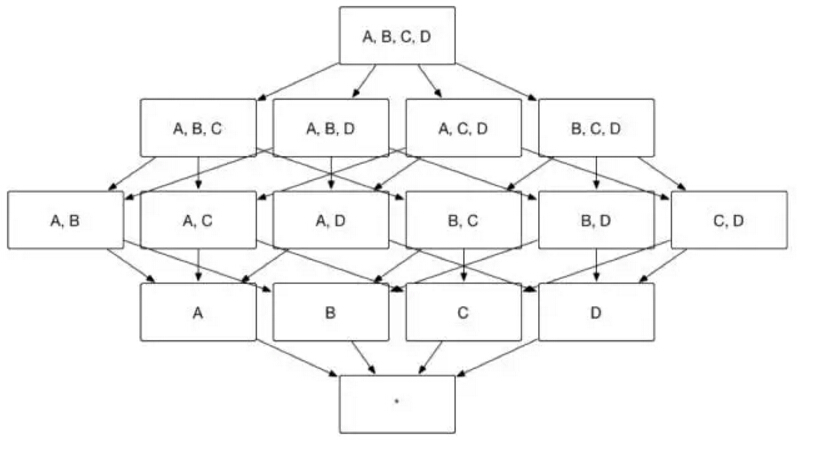
(图1)
随着维度数目的增加 Cuboid 的数量会爆炸式地增长,不仅占用大量的存储空间还会延长 Cube 的构建时间。为了缓解 Cube 的构建压力,减少生成的 Cuboid 数目,Apache Kylin 引入了一系列的高级设置,帮助用户筛选出真正需要的 Cuboid。这些高级设置包括聚合组(Aggregation Group)、联合维度(Joint Dimension)、层级维度(Hierachy Dimension)和必要维度(Mandatory Dimension)等,本系列将深入讲解这些高级设置的含义及其适用的场景。
聚合组(Aggregation Group)
用户根据自己关注的维度组合,可以划分出自己关注的组合大类,这些大类在 Apache Kylin 里面被称为聚合组。例如图 1 中展示的 Cube,如果用户仅仅关注维度 AB 组合和维度 CD 组合,那么该 Cube 则可以被分化成两个聚合组,分别是聚合组 AB 和聚合组 CD。如图 2 所示,生成的 Cuboid 数目从 16 个缩减成了 8 个。
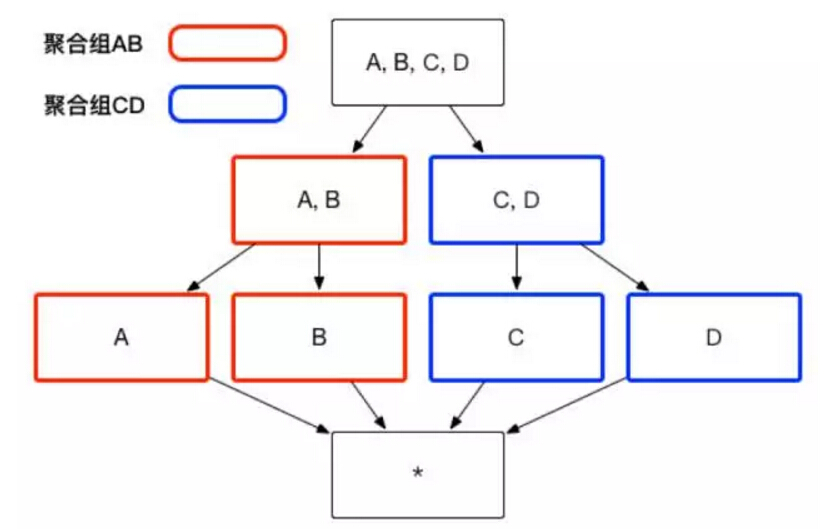
(图2)
用户关心的聚合组之间可能包含相同的维度,例如聚合组 ABC 和聚合组 BCD 都包含维度 B 和维度 C。这些聚合组之间会衍生出相同的 Cuboid,例如聚合组 ABC 会产生 Cuboid BC,聚合组 BCD 也会产生 Cuboid BC。这些 Cuboid不会被重复生成,一份 Cuboid 为这些聚合组所共有,如图 3 所示。

(图3)
有了聚合组用户就可以粗粒度地对 Cuboid 进行筛选,获取自己想要的维度组合。
聚合组应用实例
假设创建一个交易数据的 Cube,它包含了以下一些维度:顾客 ID buyer_id 交易日期 cal_dt、付款的方式 pay_type 和买家所在的城市 city。有时候,分析师需要通过分组聚合 city、cal_dt 和 pay_type 来获知不同消费方式在不同城市的应用情况;有时候,分析师需要通过聚合 city 、cal_dt 和 buyer_id,来查看顾客在不同城市的消费行为。在上述的实例中,推荐建立两个聚合组,包含的维度和方式如图 4 :
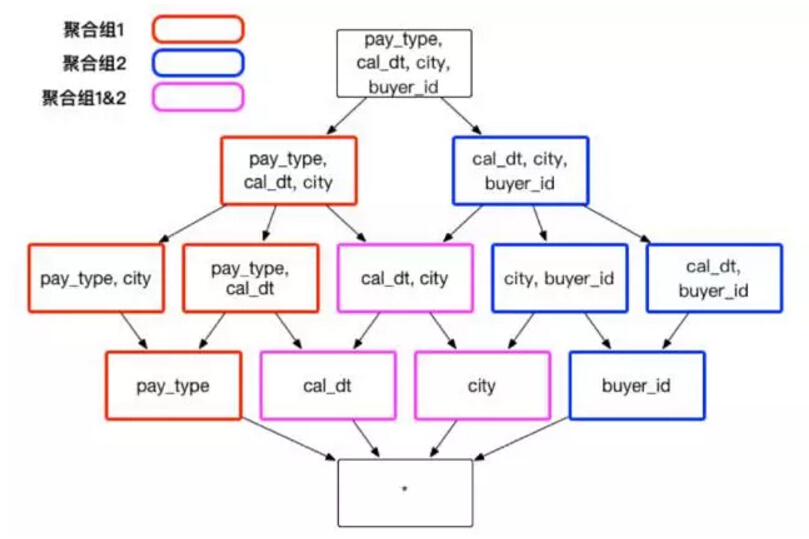
(图4)
聚合组 1: [cal_dt, city, pay_type]
聚合组 2: [cal_dt, city, buyer_id]
在不考虑其他干扰因素的情况下,这样的聚合组将节省不必要的 3 个 Cuboid: [pay_type, buyer_id]、[city, pay_type, buyer_id] 和 [cal_dt, pay_type, buyer_id] 等,节省了存储资源和构建的执行时间。
Case 1:
SELECT cal_dt, city, pay_type, count(*) FROM table GROUP BY cal_dt, city, pay_type 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case2:
SELECT cal_dt, city, buy_id, count(*) FROM table GROUP BY cal_dt, city, buyer_id 则将从 Cuboid [cal_dt, city, pay_type] 中获取数据。
Case3 如果有一条不常用的查询:
SELECT pay_type, buyer_id, count(*) FROM table GROUP BY pay_type, buyer_id 则没有现成的完全匹配的 Cuboid。
此时,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
联合维度(Joint Dimension)
用户有时并不关心维度之间各种细节的组合方式,例如用户的查询语句中仅仅会出现 group by A, B, C,而不会出现 group by A, B 或者 group by C 等等这些细化的维度组合。这一类问题就是联合维度所解决的问题。例如将维度 A、B 和 C 定义为联合维度,Apache Kylin 就仅仅会构建 Cuboid ABC,而 Cuboid AB、BC、A 等等Cuboid 都不会被生成。最终的 Cube 结果如图5所示,Cuboid 数目从 16 减少到 4。
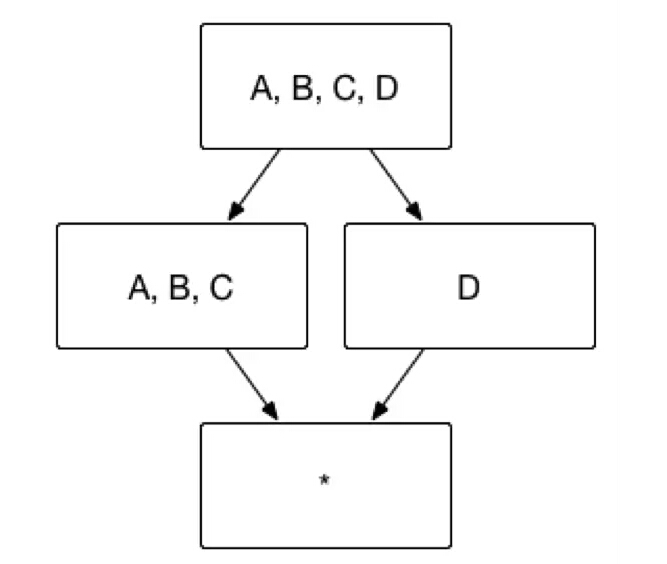
(图5)
联合维度应用实例
假设创建一个交易数据的Cube,它具有很多普通的维度,像是交易日期 cal_dt,交易的城市 city,顾客性别 sex_id 和支付类型 pay_type 等。分析师常用的分析方法为通过按照交易时间、交易地点和顾客性别来聚合,获取不同城市男女顾客间不同的消费偏好,例如同时聚合交易日期 cal_dt、交易的城市 city 和顾客性别 sex_id来分组。在上述的实例中,推荐在已有的聚合组中建立一组联合维度,包含的维度和组合方式如图6:
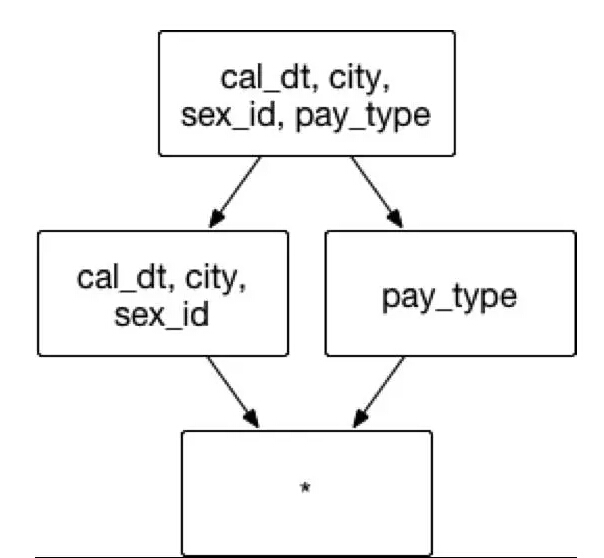
(图6)
聚合组:[cal_dt, city, sex_id,pay_type]
联合维度: [cal_dt, city, sex_id]
Case 1:
SELECT cal_dt, city, sex_id, count(*) FROM table GROUP BY cal_dt, city, sex_id 则它将从Cuboid [cal_dt, city, sex_id]中获取数据
Case2如果有一条不常用的查询:
SELECT cal_dt, city, count(*) FROM table GROUP BY cal_dt, city 则没有现成的完全匹配的 Cuboid,Apache Kylin 会通过在线计算的方式,从现有的 Cuboid 中计算出最终结果。
层级维度(Hierarchy Dimension)
用户选择的维度中常常会出现具有层级关系的维度。例如对于国家(country)、省份(province)和城市(city)这三个维度,从上而下来说国家/省份/城市之间分别是一对多的关系。也就是说,用户对于这三个维度的查询可以归类为以下三类:
- group by country
- group by country, province(等同于group by province)
- group by country, province, city(等同于 group by country, city 或者group by city)
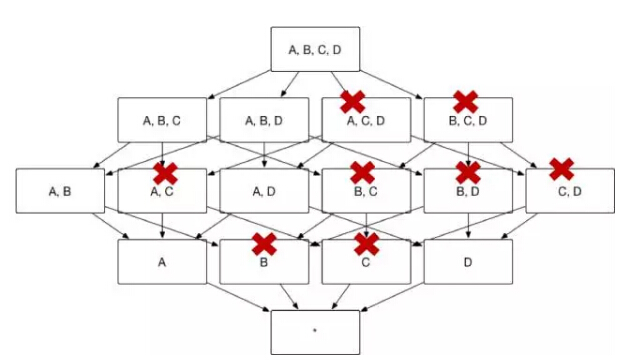
以图7所示的 Cube 为例,假设维度 A 代表国家,维度 B 代表省份,维度 C 代表城市,那么ABC 三个维度可以被设置为层级维度,生成的Cube 如图7所示。

(图7)
例如,Cuboid [A,C,D]=Cuboid[A, B, C, D],Cuboid[B, D]=Cuboid[A, B, D],因而 Cuboid[A, C, D] 和 Cuboid[B, D] 就不必重复存储。
图8展示了 Kylin 按照前文的方法将冗余的Cuboid 剪枝从而形成图 2 的 Cube 结构,Cuboid 数目从 16 减小到 8。
(图8)
层级维度应用实例
假设一个交易数据的 Cube,它具有很多普通的维度,像是交易的城市 city,交易的省 province,交易的国家 country, 和支付类型 pay_type等。分析师可以通过按照交易城市、交易省份、交易国家和支付类型来聚合,获取不同层级的地理位置消费者的支付偏好。在上述的实例中,建议在已有的聚合组中建立一组层级维度(国家country/省province/城市city),包含的维度和组合方式如图9:
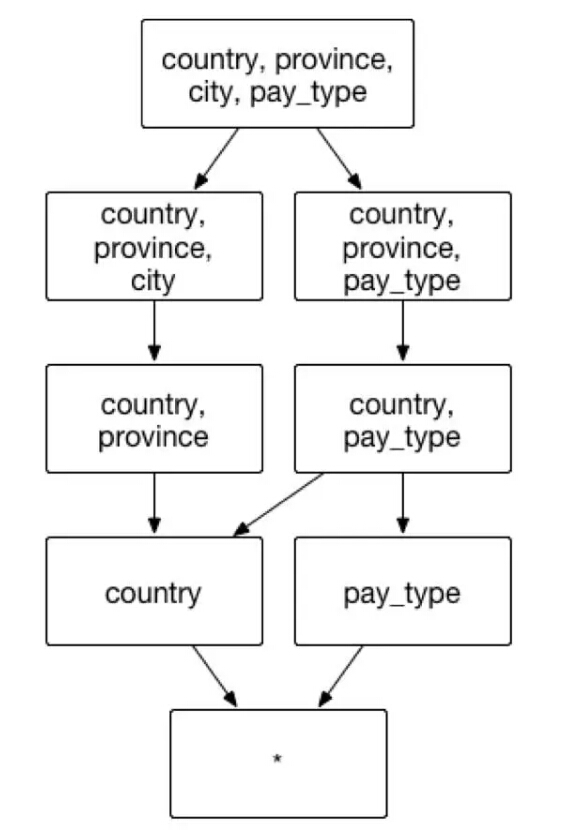
(图9)
聚合组:[country, province, city,pay_type]
层级维度: [country, province, city]
Case 1 当分析师想从城市维度获取消费偏好时:
SELECT city, pay_type, count(*) FROM table GROUP BY city, pay_type 则它将从 Cuboid [country, province, city, pay_type] 中获取数据。
Case 2 当分析师想从省级维度获取消费偏好时:
SELECT province, pay_type, count(*) FROM table GROUP BY province, pay_type 则它将从Cuboid [country, province, pay_type] 中获取数据。
Case 3 当分析师想从国家维度获取消费偏好时:
SELECT country, pay_type, count(*) FROM table GROUP BY country, pay_type 则它将从Cuboid [country, pay_type] 中获取数据。
Case 4 如果分析师想获取不同粒度地理维度的聚合结果时:
无一例外都可以由图 3 中的 cuboid 提供数据 。
例如,SELECT country, city, count(*) FROM table GROUP BY country, city 则它将从 Cuboid [country, province, city] 中获取数据。
必要维度 (Mandatory Dimension)
用户有时会对某一个或几个维度特别感兴趣,所有的查询请求中都存在group by这个维度,那么这个维度就被称为必要维度,只有包含此维度的Cuboid会被生成(如图10)。
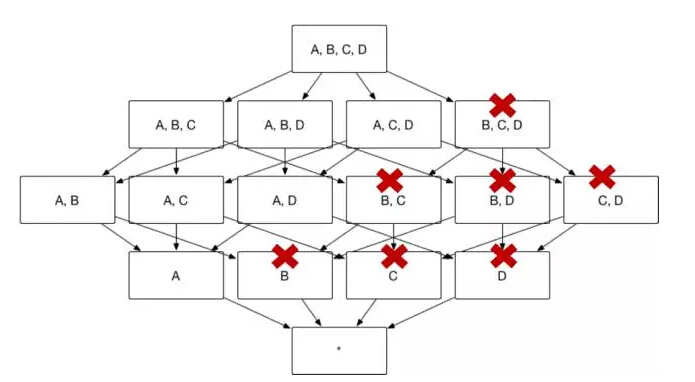
(图10)
以图 1中的Cube为例,假设维度A是必要维度,那么生成的Cube则如图11所示,维度数目从16变为9。
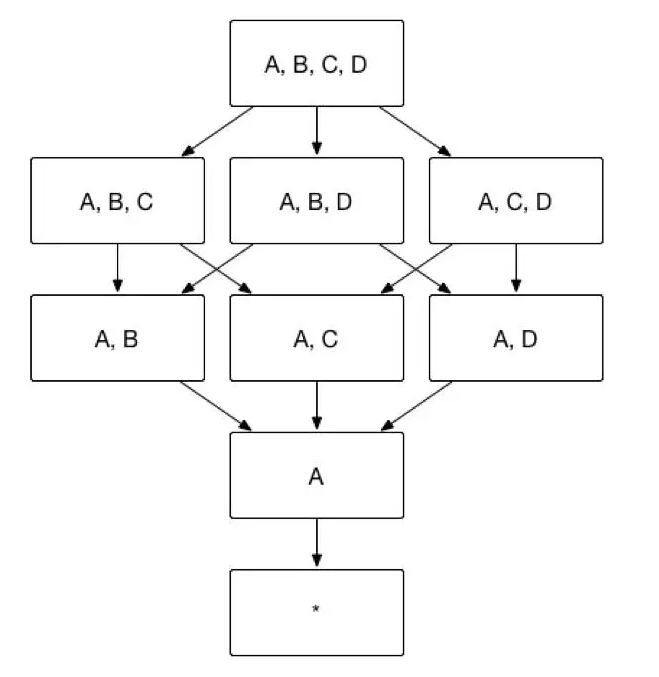
(图11)
必要维度应用实例
假设一个交易数据的Cube,它具有很多普通的维度,像是交易时间order_dt,交易的地点location,交易的商品product和支付类型pay_type等。其中,交易时间就是一个被高频作为分组条件(group by)的维度。 如果将交易时间order_dt设置为必要维度,包含的维度和组合方式如图12:

(图12)
系列总结
根据本系列的原理介绍,在Kylin的高级设置中,用户可以根据查询需求对Cube构建预计算的结果进行优化(剪枝),从而减少占用的存储空间。 而优化得当的Cube可以在占用尽量少的存储空间的同时提供极强的查询性能。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Apache Kylin优化之—Cube的高级设置

