жң¬ж–ҮиҪ¬иҮӘapachekylinе…¬дј—еҸ·гҖӮ
вҖңйҡҸзқҖз»ҙеәҰж•°зӣ®зҡ„еўһеҠ пјҢCuboid зҡ„ж•°йҮҸдјҡзҲҶзӮёејҸең°еўһй•ҝгҖӮдёәдәҶзј“и§Ј Cube зҡ„жһ„е»әеҺӢеҠӣпјҢApache Kylin еј•е…ҘдәҶдёҖзі»еҲ—зҡ„й«ҳзә§и®ҫзҪ®пјҢеё®еҠ©з”ЁжҲ·зӯӣйҖүеҮәзңҹжӯЈйңҖиҰҒзҡ„ CuboidгҖӮиҝҷдәӣй«ҳзә§и®ҫзҪ®еҢ…жӢ¬иҒҡеҗҲз»„пјҲAggregation GroupпјүгҖҒиҒ”еҗҲз»ҙеәҰпјҲJoint DimensionпјүгҖҒеұӮзә§з»ҙеәҰпјҲHierachy Dimensionпјүе’Ңеҝ…иҰҒз»ҙеәҰпјҲMandatory DimensionпјүзӯүгҖӮвҖқ
дј—жүҖе‘ЁзҹҘпјҢApache Kylin зҡ„дё»иҰҒе·ҘдҪңе°ұжҳҜдёәжәҗж•°жҚ®жһ„е»ә N дёӘз»ҙеәҰзҡ„ CubeпјҢе®һзҺ°иҒҡеҗҲзҡ„йў„и®Ўз®—гҖӮзҗҶи®әдёҠиҖҢиЁҖпјҢжһ„е»ә N дёӘз»ҙеәҰзҡ„ Cube дјҡз”ҹжҲҗВ 2NВ дёӘ CuboidпјҢ еҰӮеӣҫ 1 жүҖзӨәпјҢжһ„е»әдёҖдёӘ 4 дёӘз»ҙеәҰпјҲAпјҢBпјҢC, Dпјүзҡ„ CubeпјҢйңҖиҰҒз”ҹжҲҗ 16 дёӘCuboidгҖӮ
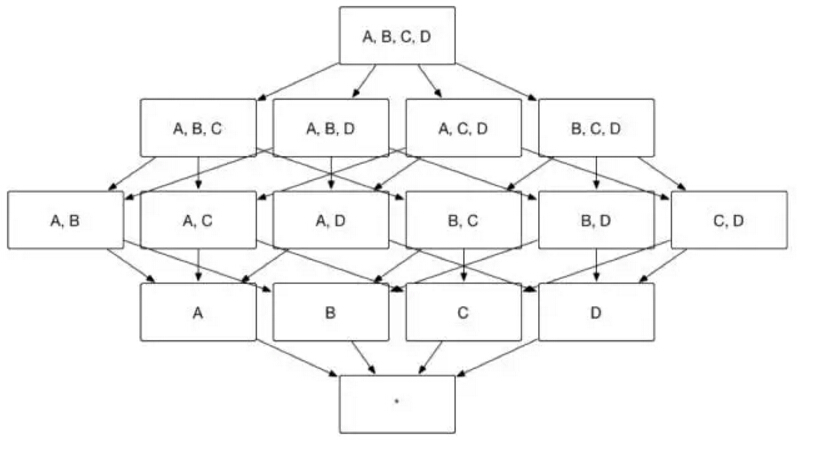
пјҲеӣҫ1пјү
йҡҸзқҖз»ҙеәҰж•°зӣ®зҡ„еўһеҠ Cuboid зҡ„ж•°йҮҸдјҡзҲҶзӮёејҸең°еўһй•ҝпјҢдёҚд»…еҚ з”ЁеӨ§йҮҸзҡ„еӯҳеӮЁз©әй—ҙиҝҳдјҡ延й•ҝ Cube зҡ„жһ„е»әж—¶й—ҙгҖӮдёәдәҶзј“и§Ј Cube зҡ„жһ„е»әеҺӢеҠӣпјҢеҮҸе°‘з”ҹжҲҗзҡ„ Cuboid ж•°зӣ®пјҢApacheВ Kylin еј•е…ҘдәҶдёҖзі»еҲ—зҡ„й«ҳзә§и®ҫзҪ®пјҢеё®еҠ©з”ЁжҲ·зӯӣйҖүеҮәзңҹжӯЈйңҖиҰҒзҡ„ CuboidгҖӮиҝҷдәӣй«ҳзә§и®ҫзҪ®еҢ…жӢ¬иҒҡеҗҲз»„пјҲAggregation GroupпјүгҖҒиҒ”еҗҲз»ҙеәҰпјҲJoint DimensionпјүгҖҒеұӮзә§з»ҙеәҰпјҲHierachy Dimensionпјүе’Ңеҝ…иҰҒз»ҙеәҰпјҲMandatory DimensionпјүзӯүпјҢжң¬зі»еҲ—е°Ҷж·ұе…Ҙи®Іи§Јиҝҷдәӣй«ҳзә§и®ҫзҪ®зҡ„еҗ«д№үеҸҠе…¶йҖӮз”Ёзҡ„еңәжҷҜгҖӮ
жң¬ж–Үе°ҶзқҖйҮҚд»Ӣз»ҚиҒҡеҗҲз»„зҡ„е®һзҺ°еҺҹзҗҶдёҺеә”з”ЁеңәжҷҜе®һдҫӢгҖӮ
иҒҡеҗҲз»„пјҲAggregation Groupпјү
з”ЁжҲ·ж №жҚ®иҮӘе·ұе…іжіЁзҡ„з»ҙеәҰз»„еҗҲпјҢеҸҜд»ҘеҲ’еҲҶеҮәиҮӘе·ұе…іжіЁзҡ„з»„еҗҲеӨ§зұ»пјҢиҝҷдәӣеӨ§зұ»еңЁ Apache Kylin йҮҢйқўиў«з§°дёәиҒҡеҗҲз»„гҖӮдҫӢеҰӮеӣҫ 1 дёӯеұ•зӨәзҡ„ CubeпјҢеҰӮжһңз”ЁжҲ·д»…д»…е…іжіЁз»ҙеәҰ AB з»„еҗҲе’Ңз»ҙеәҰ CD з»„еҗҲпјҢйӮЈд№ҲиҜҘ Cube еҲҷеҸҜд»Ҙиў«еҲҶеҢ–жҲҗдёӨдёӘиҒҡеҗҲз»„пјҢеҲҶеҲ«жҳҜиҒҡеҗҲз»„ AB е’ҢиҒҡеҗҲз»„ CDгҖӮеҰӮеӣҫ 2 жүҖзӨәпјҢз”ҹжҲҗзҡ„ Cuboid ж•°зӣ®д»Һ 16 дёӘзј©еҮҸжҲҗдәҶ 8 дёӘгҖӮ
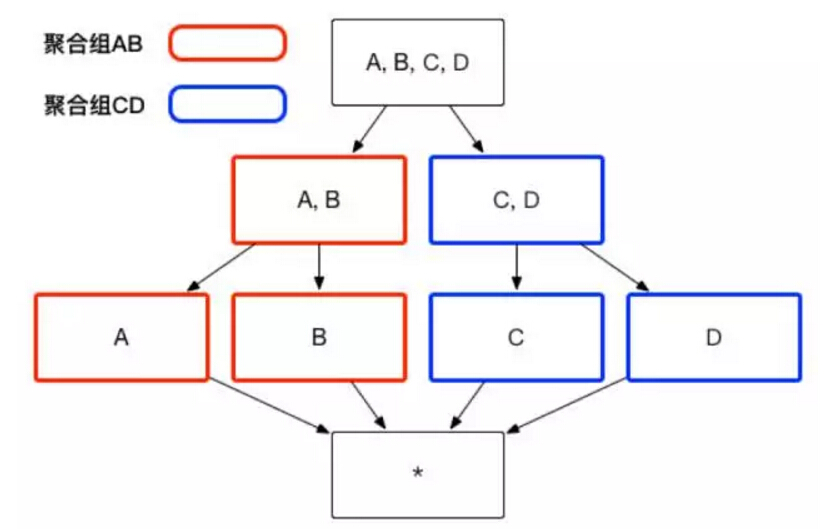
пјҲеӣҫ2пјү
з”ЁжҲ·е…іеҝғзҡ„иҒҡеҗҲз»„д№Ӣй—ҙеҸҜиғҪеҢ…еҗ«зӣёеҗҢзҡ„з»ҙеәҰпјҢдҫӢеҰӮиҒҡеҗҲз»„ ABC е’ҢиҒҡеҗҲз»„ BCD йғҪеҢ…еҗ«з»ҙеәҰ B е’Ңз»ҙеәҰ CгҖӮиҝҷдәӣиҒҡеҗҲз»„д№Ӣй—ҙдјҡиЎҚз”ҹеҮәзӣёеҗҢзҡ„ CuboidпјҢдҫӢеҰӮиҒҡеҗҲз»„ ABC дјҡдә§з”ҹ Cuboid BCпјҢиҒҡеҗҲз»„ BCD д№ҹдјҡдә§з”ҹ Cuboid BCгҖӮиҝҷдәӣ CuboidдёҚдјҡиў«йҮҚеӨҚз”ҹжҲҗпјҢдёҖд»Ҫ Cuboid дёәиҝҷдәӣиҒҡеҗҲз»„жүҖе…ұжңүпјҢеҰӮеӣҫ 3 жүҖзӨәгҖӮ

пјҲеӣҫ3пјү
жңүдәҶиҒҡеҗҲз»„з”ЁжҲ·е°ұеҸҜд»ҘзІ—зІ’еәҰең°еҜ№ Cuboid иҝӣиЎҢзӯӣйҖүпјҢиҺ·еҸ–иҮӘе·ұжғіиҰҒзҡ„з»ҙеәҰз»„еҗҲгҖӮ
еә”з”Ёе®һдҫӢ
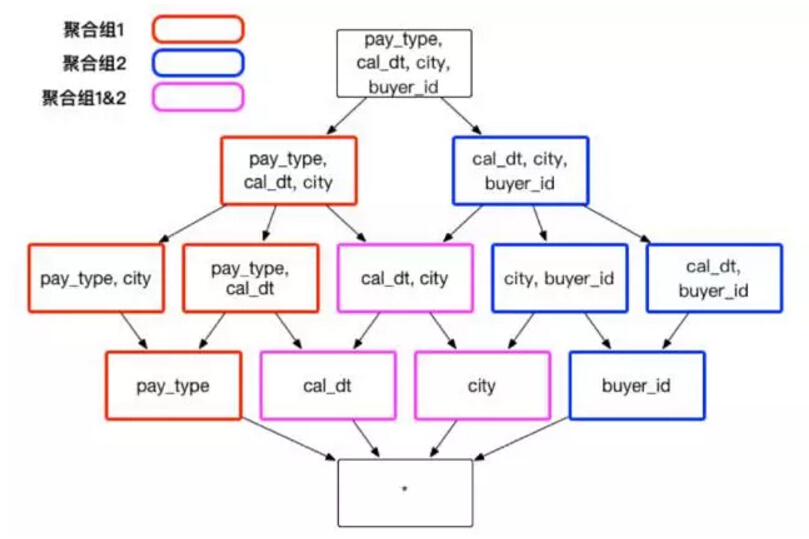
иҒҡеҗҲз»„ 2пјҡВ [cal_dt, city, buyer_id]
еңЁдёҚиҖғиҷ‘е…¶д»–е№Іжү°еӣ зҙ зҡ„жғ…еҶөдёӢпјҢиҝҷж ·зҡ„иҒҡеҗҲз»„е°ҶиҠӮзңҒдёҚеҝ…иҰҒзҡ„ 3 дёӘ Cuboid: [pay_type, buyer_id]гҖҒ[city, pay_type, buyer_id] е’Ң [cal_dt, pay_type, buyer_id] зӯүпјҢиҠӮзңҒдәҶеӯҳеӮЁиө„жәҗе’Ңжһ„е»әзҡ„жү§иЎҢж—¶й—ҙгҖӮ
Case 1:В
SELECT cal_dt, city, pay_type, count(*) FROM table GROUPВ BY cal_dt, city, pay_type еҲҷе°Ҷд»Һ Cuboid [cal_dt, city, pay_type]В дёӯиҺ·еҸ–ж•°жҚ®гҖӮ
Case2:В
SELECT cal_dt, city, buy_id, count(*) FROM table GROUPВ BY cal_dt, city, buyer_idВ еҲҷе°Ҷд»Һ Cuboid [cal_dt, city, pay_type]В дёӯиҺ·еҸ–ж•°жҚ®гҖӮ
Case3В еҰӮжһңжңүдёҖжқЎдёҚеёёз”Ёзҡ„жҹҘиҜў:
SELECT pay_type, buyer_id, count(*) FROM table GROUPВ BY pay_type, buyer_id еҲҷжІЎжңүзҺ°жҲҗзҡ„е®Ңе…ЁеҢ№й…Қзҡ„ CuboidгҖӮ
жӯӨж—¶пјҢApache Kylin дјҡйҖҡиҝҮеңЁзәҝи®Ўз®—зҡ„ж–№ејҸпјҢд»ҺзҺ°жңүзҡ„ Cuboid дёӯи®Ўз®—еҮәжңҖз»Ҳз»“жһңгҖӮ
е°Ҹз»“
Apache Kylin дҪңдёәдёҖз§ҚеӨҡз»ҙеҲҶжһҗе·Ҙе…·пјҢе…¶йҮҮз”Ёйў„и®Ўз®—зҡ„ж–№жі•пјҢеҲ©з”Ёз©әй—ҙжҚўеҸ–ж—¶й—ҙпјҢжҸҗй«ҳжҹҘиҜўж•ҲзҺҮгҖӮжң¬ж–Үд»Ӣз»ҚдәҶ Apache Kylin зҡ„й«ҳзә§и®ҫзҪ®дёӯиҒҡеҗҲз»„зҡ„йғЁеҲҶпјҢиҒҡеҗҲз»„йҖӮз”ЁдәҺеҪ“еҲҶжһҗеёҲзІ—зІ’еәҰең°е…іжіЁжҹҗдәӣз»ҙеәҰеҺ»иҝӣиЎҢеҲҶз»„иҒҡеҗҲзҡ„еңәжҷҜгҖӮ
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » Apache KylinдјҳеҢ––й«ҳзә§и®ҫзҪ®пјҡиҒҡеҗҲз»„пјҲAggregation GroupпјүеҺҹзҗҶи§Јжһҗ

