关键字:Kafka Java API、producer、consumer
前面的文章《Kafka安装配置测试》中安装配置了分布式的Kafka集群,并且使用自带的kafka-console-producer.sh和kafka-console-consumer.sh模拟测试了发送消息和消费消息。
本文使用简单的Java API模拟Kafka的producer和consumer,其中,procuder从一个文本文件中逐行读取内容,然后发送到Kafka,consumer则从Kafka中读取内容并在控制台打印。
Java API Producer
package com.lxw1234.kafka;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class MyProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "172.16.212.17:9091,172.16.212.17:9092,172.16.212.102:9091,172.16.212.102:9092");
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props));
String topic = "lxw1234.com";
File file = new File("E:/track-log.txt");
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) {
producer.send(new KeyedMessage<Integer, String>(topic,line + "---" + tempString));
System.out.println("Success send [" + line + "] message ..");
line++;
}
reader.close();
System.out.println("Total send [" + line + "] messages ..");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {}
}
}
producer.close();
}
}
程序从E:/track-log.txt文件中读取内容,发送至Kafka。
Java API Consumer
package com.lxw1234.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class MyConsumer {
public static void main(String[] args) {
String topic = "lxw1234.com";
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while(it.hasNext())
System.out.println("consume: " + new String(it.next().message()));
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("group.id","group1");
props.put("zookeeper.connect","zk1:2181,zk2:2181,zk3:2181");
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
}
Consumer从Kafka中消费数据,并在控制台中打印消息内容。
运行和结果
先运行Consumer,之后再运行Producer,运行时候将$KAFKA_HOME/lib/下的所有jar包依赖进去。
Producer运行结果如下:
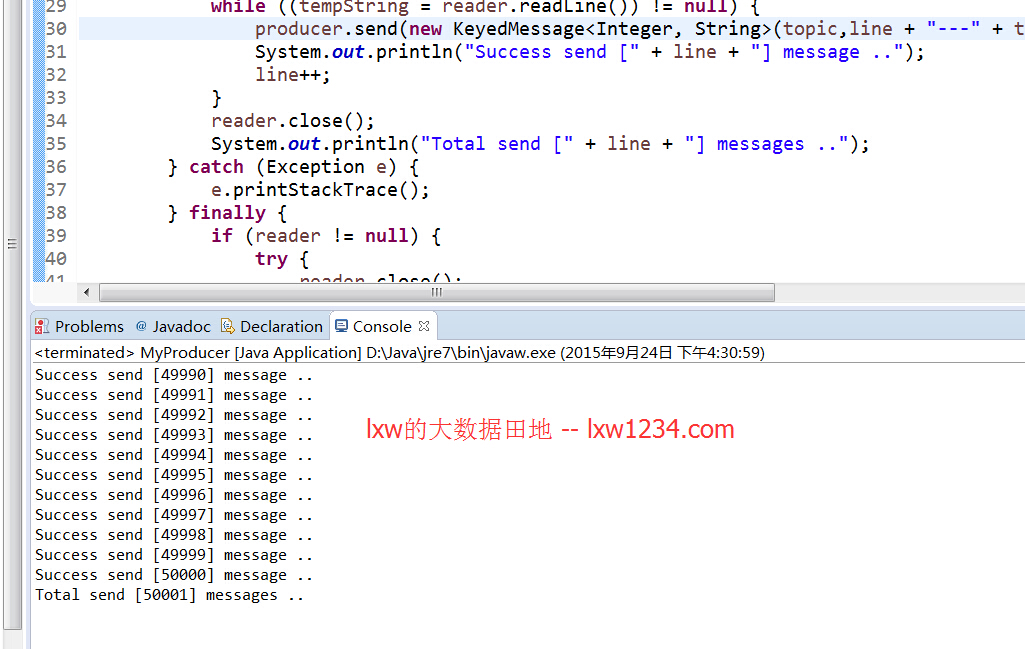
文件中只有50000行记录,因为最后又把行号加了一次,因此最后打印出是50001.
Consumer运行结果如下:
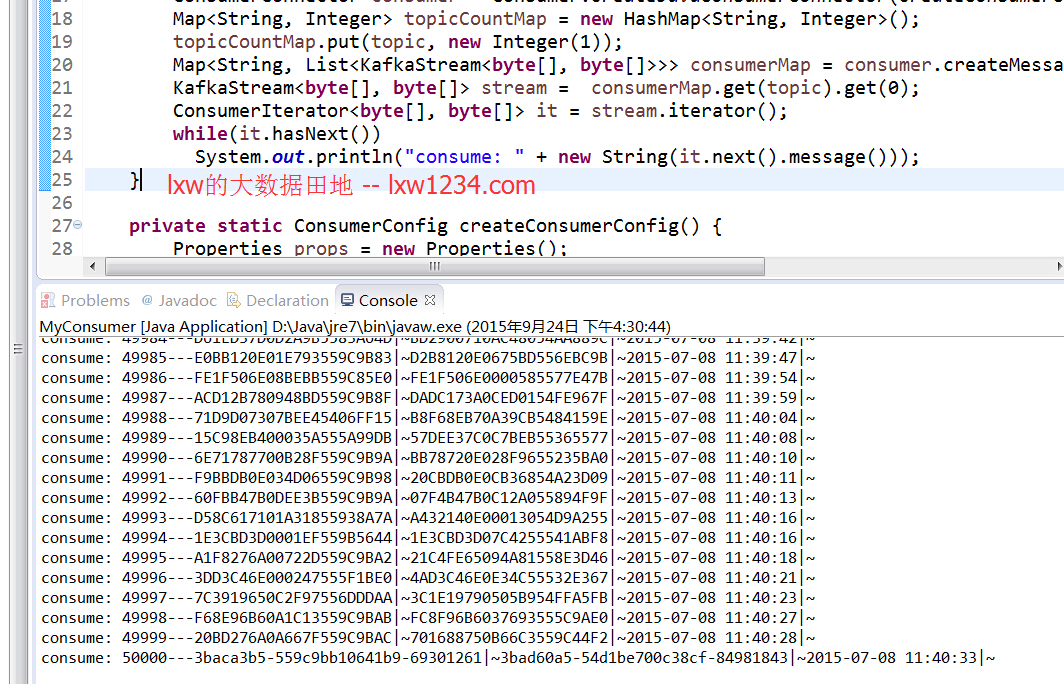
Consumer成功获取了5000条数据。
关于Kafka,还有很多疑问,继续尝试和学习吧,enjoy it!
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。


