关键字:druid.io、druid query
Druid查询是通过HTTP REST方式发送查询请求,查询的描述写在一个JSON文件中,可以处理查询请求的服务包括Broker、Historical和Realtime,这几个服务节点都提供了相同的查询接口,但一般是将查询请求发送至Broker节点,由Broker节点根据查询的数据源来转发至Historical或者RealTime节点。
另外,目前已有很多开源的使用其他语言查询Druid数据的包。具体可参考:http://druid.io/docs/latest/development/libraries.html
本文介绍Druid自带的JSON+HTTP的查询方式,使用的数据源为lxw1234,之前文章中介绍批量数据加载时候加载到Druid中,
可参考《使用HadoopDruidIndexer向Druid集群中加载批量数据-Batch Data Ingestion》。
基本的查询有三类:聚合查询(Aggregation Queries)、元数据查询(Metadata Queries)和搜索查询(Search Queries)。
Druid关于Query的官方文档地址在:http://druid.io/docs/latest/querying/querying.html
执行查询(这里指定的是Broker Node的地址):
curl -X POST 'http://node2:8092/druid/v2/?pretty' -H 'content-type: application/json' -d @query.json
1. 聚合查询(Aggregation Queries)
聚合查询就是指标数据根据一定的规则,在一个或多个维度上进行聚合。
1.1 基于时间序列的聚合查询Timeseries queries
Timeseries查询根据指定的时间区间及时间间隔进行聚合查询,在查询中还可以指定过滤条件,需要聚合的指标列、等。
一个简单的Timeseries查询配置文件如下:
{
"queryType": "timeseries",
"dataSource": "lxw1234",
"intervals": [ "2015-11-15/2015-11-18" ],
"granularity": "day",
"aggregations": [
{"type": "longSum", "fieldName": "count", "name": "total_count"}
]
}
queryType:查询类型,这里是timeseries
dataSource:指定数据源
intervals:查询的时间区间
granularity:聚合的时间间隔
aggregations:聚合的类型、字段及结果显示的名称
使用上面的配置文件执行查询后,结果如下:
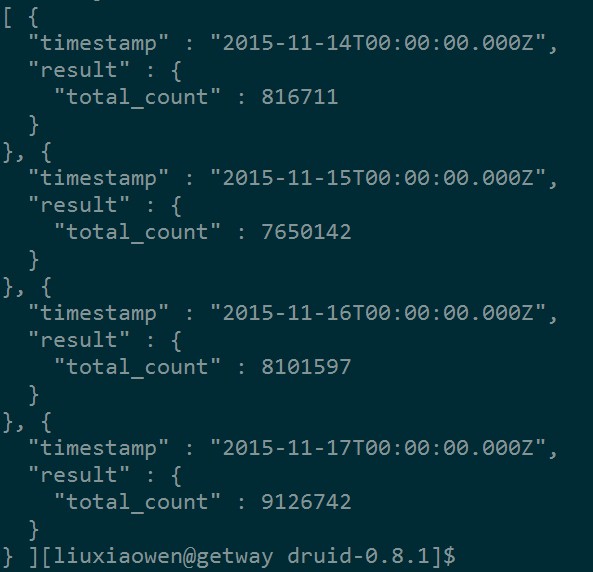
结果已按天汇总,但是存在时间格式的问题。
除了上面几个选项,Timeseries查询中还可以指定的选项有:filter、postAggregations和context;后续将做详细介绍。
Zero-filling:
一般情况下,使用Timeseries查询按天汇总,而某一天没有数据(被过滤掉了),那么在结果中会显示该天的汇总结果为0。比如上面的数据,假设2015-11-15这一天没有符合条件的数据,那么结果会变成:
{
"timestamp" : "2015-11-15T00:00:00.000Z",
"result" : {
"total_count" : 0
}
}
如果不希望这种数据出现在结果中,那么可以使用context选项来去掉它,配置如下:
"context" : {
"skipEmptyBuckets": "true"
}
1.2 TopN聚合查询(TopN queries)
TopN查询大家应该都比较熟悉,就是基于一个维度GroupBy,然后按照汇总后的指标排序,取TopN.在Druid中,TopN查询要比相同实现方式的GroupBy+Ordering效率快。
实现原理上,其实也就是分而治之,比如取Top10,由每个任务节点各自取Top10,然后统一发送至Broker,由Broker从各个节点的Top10中,再汇总出最终的Top10.
一个简单的TopN查询配置文件:
{
"queryType": "topN",
"dataSource": "lxw1234",
"granularity": "day",
"dimension": "cookieid",
"metric": "total_count",
"threshold" : 3,
"aggregations": [
{"type": "longSum", "fieldName": "count", "name": "total_count"}
],
"intervals": ["2015-11-17/2015-11-18"]
}
该查询查出每天pv最多的Top 3 cookieid,查询结果:
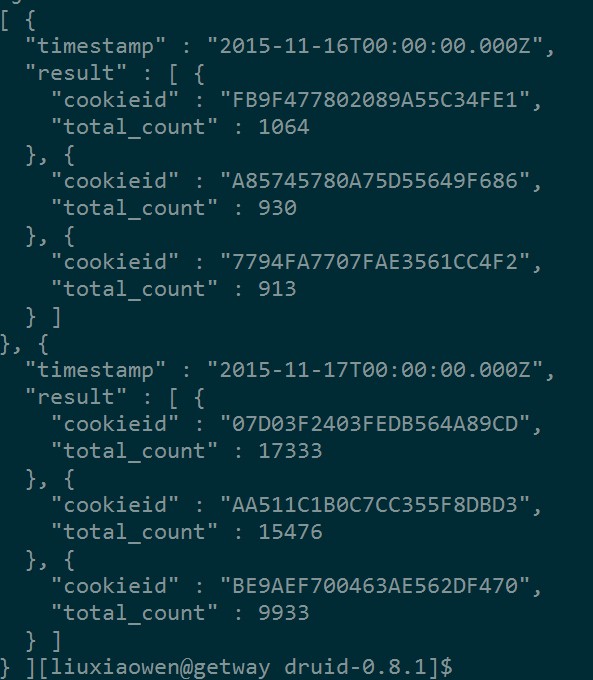
另外,TopN查询中还支持配置其他的选项:filter、postAggregations、context等,后续将做详细介绍。
1.3 GroupBy聚合查询
GroupBy聚合查询就是在多个维度上,将指标聚合。Druid中建议,能用TimeseriesQueries和TopN实现的查询尽量不要用GroupBy,因为GroupBy的性能要差一些。
一个简单的GroupBy查询配置文件如下:
{
"queryType": "groupBy",
"dataSource": "lxw1234",
"granularity": "day",
"dimensions": ["cookieid", "ip"],
"limitSpec": { "type": "default", "limit": 50, "columns": ["cookieid", "ip"] },
"aggregations": [
{ "type": "longSum", "name": "total_pv", "fieldName": "count" }
],
"intervals": ["2015-11-17/2015-11-19"]
}
该查询按照天、cookieid、ip进行GroupBy,汇总pv,并且limit 50条数据。
结果为:
{
"version" : "v1",
"timestamp" : "2015-11-16T00:00:00.000Z",
"event" : {
"total_pv" : 4,
"cookieid" : "001714AF0549BB55405121",
"ip" : "175.20.11.38"
}
}, {
"version" : "v1",
"timestamp" : "2015-11-16T00:00:00.000Z",
"event" : {
"total_pv" : 1,
"cookieid" : "00179C6E02F673564A656C",
"ip" : "110.156.23.0"
}
}, {
"version" : "v1",
"timestamp" : "2015-11-16T00:00:00.000Z",
"event" : {
"total_pv" : 4,
"cookieid" : "0019E379003F70539467A7",
"ip" : "218.4.75.70"
}
}
GroupBy查询还支持的选项有:filter、postAggregations、having、limitSpec、context等,后续将做详细介绍。
2. 元数据查询(Metadata Queries)
2.1 时间范围查询(Time Boundary Queries)
时间范围查询用来查询一个数据源的最小和最大时间点。
{
"queryType" : "timeBoundary",
"dataSource": "lxw1234"
}
查询结果为:
[ {
"timestamp" : "2015-11-15T00:00:00.000+08:00",
"result" : {
"minTime" : "2015-11-15T00:00:00.000+08:00",
"maxTime" : "2015-11-18T23:59:59.000+08:00"
}
} ]
另外,还有个bound选项,用来指定返回最大时间点还是最小时间点,如果不指定,则两个都返回:
{
"queryType" : "timeBoundary",
"dataSource": "lxw1234",
"bound": "maxTime"
}
此时只返回最大时间点:
[ {
"timestamp" : "2015-11-18T23:59:59.000+08:00",
"result" : {
"maxTime" : "2015-11-18T23:59:59.000+08:00"
}
} ]
2.2 Segments元数据查询(Segment Metadata Queries)
Segments元数据查询可以查询到每个Segment的以下信息:
- Segment中所有列的基数(Cardinality),非STRING类型的列为null;
- 每个列的预计大小(Bytes);
- 该Segment的时间跨度;
- 列的类型;
- 该Segment的预估总大小;
- Segment ID;
查询的配置文件:
{
"queryType":"segmentMetadata",
"dataSource":"lxw1234",
"intervals":["2015-11-15/2015-11-19"]
}
查询结果(只取了一个Segment):
{
"id" : "lxw1234_2015-11-17T00:00:00.000+08:00_2015-11-18T00:00:00.000+08:00_2015-11-18T16:53:02.158+08:00_1",
"intervals" : [ "2015-11-17T00:00:00.000+08:00/2015-11-18T00:00:00.000+08:00" ],
"columns" : {
"__time" : {
"type" : "LONG",
"size" : 46837800,
"cardinality" : null,
"errorMessage" : null
},
"cookieid" : {
"type" : "STRING",
"size" : 106261532,
"cardinality" : 1134359,
"errorMessage" : null
},
"count" : {
"type" : "LONG",
"size" : 37470240,
"cardinality" : null,
"errorMessage" : null
},
"ip" : {
"type" : "STRING",
"size" : 63478131,
"cardinality" : 735562,
"errorMessage" : null
}
},
"size" : 272782823
}
另外,还有其他几个选项,toInclude、merge、analysisTypes,比较简单,详见:http://druid.io/docs/latest/querying/segmentmetadataquery.html
2.3 数据源元数据查询(Data Source Metadata Queries)
这个查询只是返回该数据源的最后一次有数据进入的时间。
比如,查询配置文件:
{
"queryType" : "dataSourceMetadata",
"dataSource": "lxw1234"
}
结果为:
[ {
"timestamp" : "2015-11-18T23:59:59.000+08:00",
"result" : {
"maxIngestedEventTime" : "2015-11-18T23:59:59.000+08:00"
}
} ]
3. 搜索查询(Search Queries)
这里的搜索指的是对维度列的值的搜索,基本类似于过滤(Filter)。
下面的配置文件从时间区间在2015-11-17/2015-11-19的数据中,搜索出ip包含”219.146.132.239″的记录:
{
"queryType": "search",
"dataSource": "lxw1234",
"granularity": "day",
"searchDimensions": [
"ip"
],
"query": {
"type": "insensitive_contains",
"value": "219.146.132.239"
},
"sort" : {
"type": "lexicographic"
},
"intervals": [
"2015-11-17/2015-11-19"
]
}
运行结果为:
[ {
"timestamp" : "2015-11-16T00:00:00.000Z",
"result" : [ {
"dimension" : "ip",
"value" : "219.146.132.239"
} ]
}, {
"timestamp" : "2015-11-17T00:00:00.000Z",
"result" : [ {
"dimension" : "ip",
"value" : "219.146.132.239"
} ]
} ]
SearchQuery中可以配置的选项还有:filter、context,后面将做详细介绍。
3.1 query选项
query选项用来定义搜索的规则,目前有两种,一种是上面用到的insensitive_contains(包含)。
另外一种是fragment,即,当维度列的值包含给定数组中所有值的时候,才算匹配,比如:
"query": {
"type": "fragment",
"values": ["219.146","132.239"]
}
意思是当ip同时包含”219.146″和”132.239″时候才算匹配。
注意:这里是values,insensitive_contains是value;
3.2 sort选项
sort选项用来定义结果中该维度列的值按照什么顺序来排序,默认为lexicographic(字典序),另外还有strlen(字符串长度排序)。
4. Select查询
Select查询很简单,就是根据配置的规则来获取列,支持分页。
一个简单的Select查询配置文件如下:
{
"queryType": "select",
"dataSource": "lxw1234",
"dimensions":[],
"metrics":[],
"granularity": "all",
"intervals": [
"2015-11-17/2015-11-18"
],
"pagingSpec":{"pagingIdentifiers": {}, "threshold":10}
}
该查询从数据源lxw1234中查询时间段内所有的字段,每10条一个分页,结果为(只截取部分):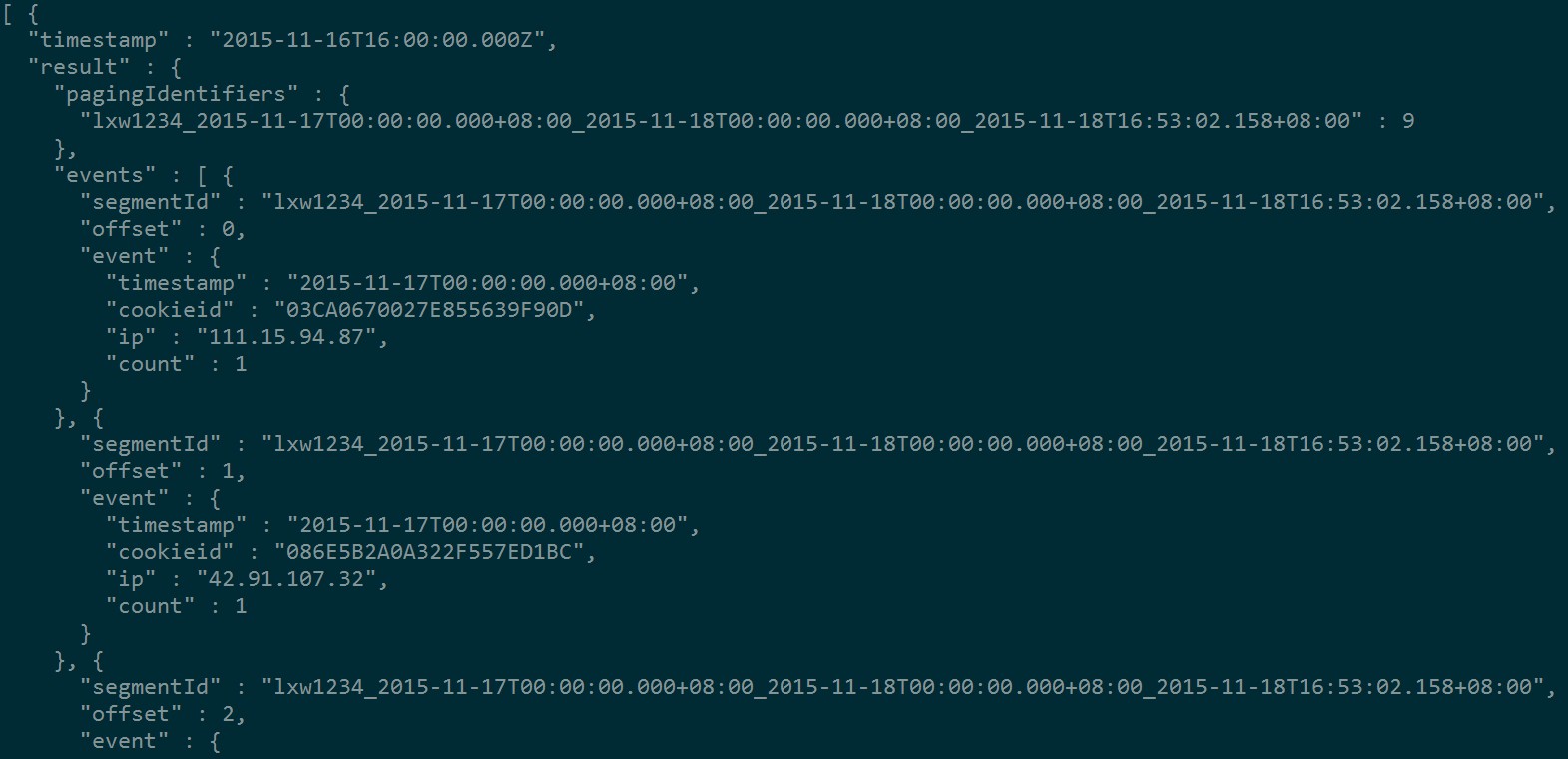
其中,threshold指定了每页的记录数,offset显示了该条记录在segment中的索引号,
"pagingIdentifiers" : {
"lxw1234_2015-11-17T00:00:00.000+08:00_2015-11-18T00:00:00.000+08:00_2015-11-18T16:53:02.158+08:00" : 9
},
记录了分页标记,前面是segment ID,后面是本页最大的offset;
如果将查询配置文件中的pagingIdentifiers改成:
"pagingSpec":{
"pagingIdentifiers": {"lxw1234_2015-11-17T00:00:00.000+08:00_2015-11-18T00:00:00.000+08:00_2015-11-18T16:53:02.158+08:00" : 10},
"threshold":10
}
再看执行结果:
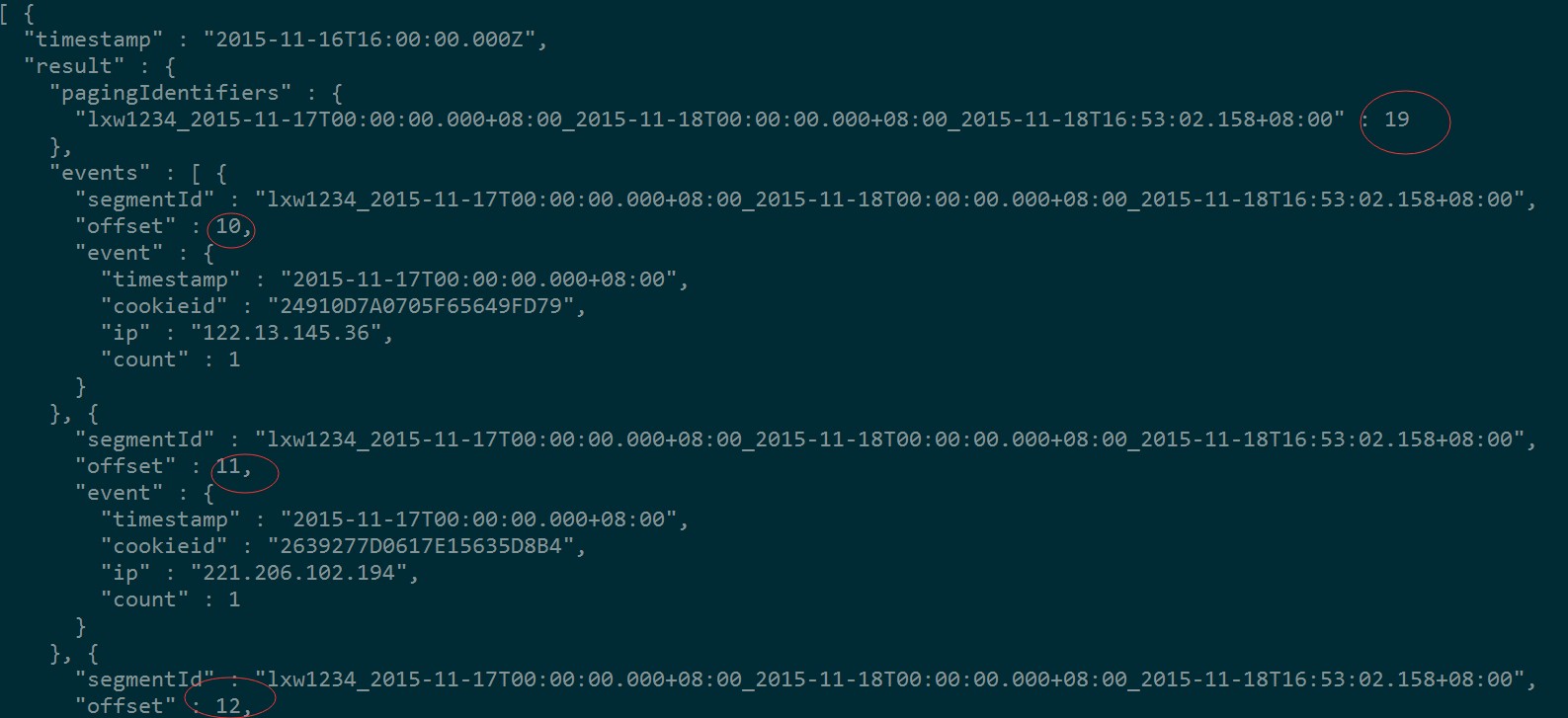
很明显,这样显示的已经是”第二页”的数据了。
另外,SelectQuery中也支持filter、context选项,后续将做介绍。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 查询Druid中的数据
