Kettle是一款国外开源的ETL以及简单的调度工具。
官网:http://www.pentaho.com/product/data-integration
之前Kettle在传统数据仓库中用的比较多,现在也集成了很多大数据相关的组件,比如:HDFS、MapReduce、HBase、Hive、Sqoop等。
这两天试验了一下,在此做一记录。
我使用的Kettle版本为最新的pdi-ce-7.0.0.0-25.zip,特别注意,该版本对jdk的要求比较高,之前系统上的jdk-8u65竟然也不行,后来用了最新的jdk-8u121才正常。
完成了一个简单的ETL过程:
从Oracle中抽取数据->写入HDFS->Load进Hive表。
因为我们的Linux服务器都没有图形化界面,并且我本机不能访问hadoop集群节点的内网ip(只能通过网关机访问),因此,需要进行下面的部署:

在Hadoop网关机(Linux)上启动Kettle远程服务,作为子服务器;
在我的机器(windows)上启动Kettle,作为主服务器,进行作业开发,执行时候,提交到子服务器进行远程执行。
配置Kettle远程服务
下载Kettle:
https://nchc.dl.sourceforge.net/project/pentaho/Data%20Integration/7.0/pdi-ce-7.0.0.0-25.zip
解压之后,编辑data-integration/plugins/pentaho-big-data-plugin/plugin.properties文件:
设置hadoop版本(我使用的cdh5.8):active.hadoop.configuration=cdh58
进入data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/cdh58目录:
将hadoop的配置文件core-site.xml、mapred-site.xml、yarn-site.xml复制过来。
在Kettle远程服务器上(Linux):
进入data-integration目录,设置远程服务连接密码:
sh encr.sh -carte yourpassword
结果会输出加密后的密码:OBF:1hvy1i271vny1zej1zer1vn41hzj1hrk
编辑密码文件:vi ./pwd/kettle.pwd
cluster: OBF:1hvy1i271vny1zej1zer1vn41hzj1hrk
其中,cluster为默认的用户名。
然后启动远程服务:
nohup ./carte.sh localhost 9888 >> carte.log &
端口号9888可以自己定义。
本地Kettle主服务器开发任务
本地windows解压Kettle之后,执行Spoon.bat启动Kettle。
执行SpoonConsole.bat打开图形界面。
文件->新建->转换:

在该转换中,需要配置2个DB链接(Oracle和HiveServer2),配置Hadoop集群(HDFS),配置子服务器(远程执行服务器)。
DB的配置很简单,略过。
新建子服务器:

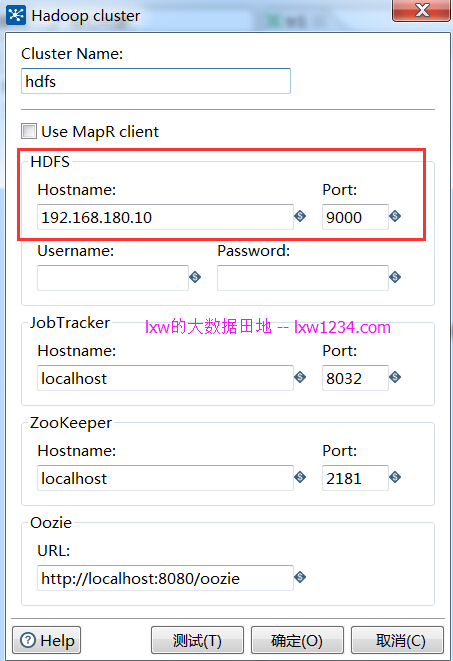
新建Hadoop集群:注意,如果不使用MapReduce和ZK,那么只需要配置HDFS即可,Hostname为主NameNode的IP.
远程执行任务
开发完后,在执行的选项中,选择远程执行:
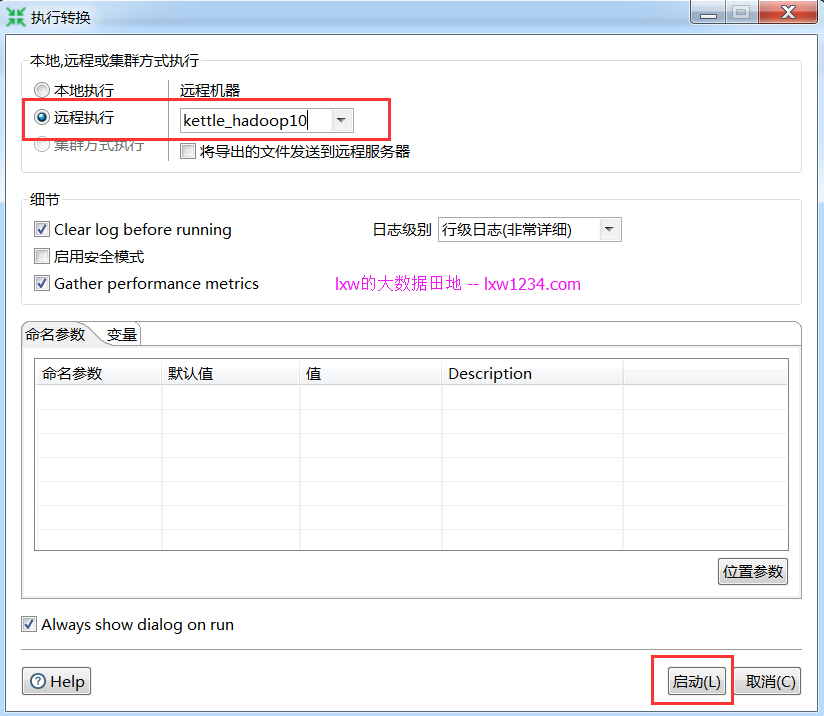
本地Kettle会连接到远程Kettle子服务器,将该作业配置信息发送给子服务器进行执行。
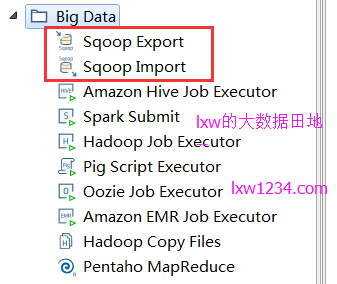
除了上述方法完成DBàHive的数据导入,Kettle也集成了Sqoop,应该也可以完成,后续再进行尝试:
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 开源ETL工具Kettle初试–远程执行任务

