本文转载自公众号 DBAplus社群 , 作者:谢麟炯
谢麟炯,唯品会大数据平台高级技术架构经理,主要负责大数据自助多维分析平台,离线数据开发平台及分析引擎团队的开发和管理工作,加入唯品会以来还曾负责流量基础数据的采集和数据仓库建设以及移动流量分析等数据产品的工作。
海量数据实时OLAP场景的困境
大数据
首先来看一下我们在最初几年遇到的问题。第一就是大数据,听起来好像蛮无聊的,但大数据到底是指什么呢?最主要的问题就是数据大,唯品会在这几年快速发展,用户流量数据从刚开始的几百万、几千万发展到现在的几个亿,呈现了100倍以上的增长。
对我们而言,所谓的大数据就是数据量的快速膨胀,带来的问题最主要的就是传统RDBMS无法满足存储的需求,继而是计算的需求,我们的挑战便是如何克服这个问题。
慢查询
第二个问题是慢查询,有两个方面:一是OLAP查询的速度变慢;二是ETL数据处理效率降低。
分析下这两个问题:首先,用户使用OLAP分析系统时会有这样的预期,当我点击查询按钮时希望所有的数据能够秒出,而不是我抽身去泡个茶,回来一看数据才跑了10%,这是无法接受的。由于数据量大,我们也可以选择预先计算好,当用户查询时直接从计算结果中找到对应的值返回,那么查询就是秒出的。数据量大对预计算而言也有同样的问题,就是ETL的性能也下降了,本来准备这个数据可能只需40分钟或一个小时,现在数据量翻了一百倍,需要三个小时,这时候数据分析师上班时就会抱怨数据没有准备好,得等到中午分析之类的,会听到来自同事不断的抱怨。
长迭代
数据量变大带来的第三个毛病,就是开发周期变长。两个角度:第一,新业务上线,用户会说我能不能在这个新的角度上线前,看看历史数据,要看一年的,这时就要刷数据了。刷数据这件事情大家知道,每次刷头都很大,花的时间很长。旧业务也一样,加新的指标,没有历史趋势也不行,也要刷数据,开发就不断地刷数据。因为数据量大,刷数据的时间非常长,数据验证也需要花很多的时间,慢慢的,开发周期变慢,业务很急躁,觉得不就是加个字段吗,怎么这么慢。这样一来,数据的迭代长,周期变慢,都让业务部门对大数据业务提出很多的质疑,我们需要改进来解决这些问题。
业务部门的想法是,不管你是什么业务,不管现在用的是什么方法,他们只关心三点:第一,提的需求要很快满足;第二,数据要很快准备好;第三,数据准备好之后,当我来做分析时数据能够很快地返回。业务要的是快快快,但现在的能力是慢慢慢,为此,我们急需解决业务部门的需求和现状之间的冲突。
唯品会大数据实时OLAP升级过程
第0阶段
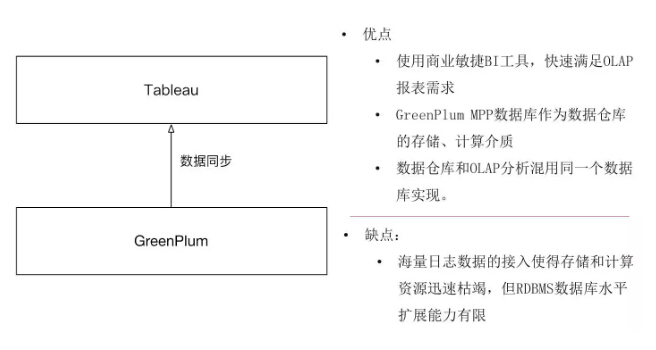
这是我们的初始状态,架构比较简单。底层的计算、存储和OLAP分析用MDB的数据仓库解决的,上层用Tableau的BI工具,开发速度比较快,同时有数据可视化效果,业务部分非常认可。GreenPlum是MPP的方案,它的高并发查询非常适合我们这种OLAP的查询,性能非常好。所以我们在这个阶段,把GreenPlum作为数据仓库和OLAP混用的实现。
这样一个架构其实是一个通用的架构,像Tableau可以轻易被替换, GreenPlum也可以替换成Oracle之类的,这样一个常用的工具、一个架构,其实满足了部分的需求,但也有个问题,就是像GreenPlum这样的RDBMS数据库,在面对海量的数据写入时存储和计算的资源快速地枯竭了, GreenPlum的水平扩展有限,所以同样碰到了大数据的问题。
第1阶段
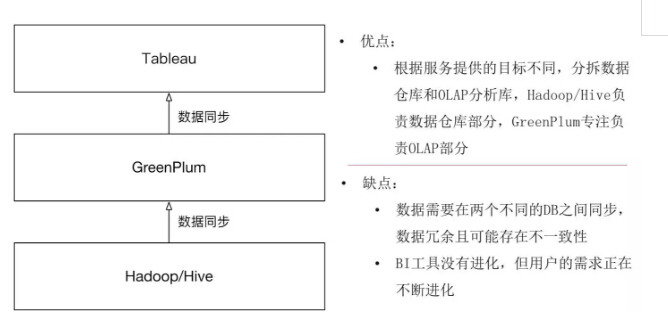
所以很快我们就进入了第一阶段。这个阶段,我们引入了Hadoop/Hive,所有的计算结果做预计算之后,会同步到GreenPlum里面,接下去一样,用GreenPlum去做分析。OLAP讲聚合讲的Ad-hoc,继续由GreenPlum承载,数据仓库讲明细数据讲Batch,就交给专为批量而生的Hive来做,这样就能把OLAP和数据仓库这两个场景用两个不一样技术栈分开。这样一个技术方案解决了数据量大的问题,ETL批量就不会说跑不动或者数据没法存储。
但问题是增加了新的同步机制,需要在两个不同的DB之间同步数据。同步数据最显而易见的问题就是除了数据冗余外,如果数据不同步怎么办?比如ETL开发在Hadoop上更新,但没有同步到GreenPlum上,用户会发现数据还是错误的。第二,对用户来说,当他去做OLAP分析时,Tabluea是更适合做报表的工具,随着我们业务的扩展和数据驱动不断的深入,业务不管分析师还是商务、运营、市场,他们会越来越多地想组合不同的指标和维度去观察自己的数据,找自己运营的分析点。传统的Tabluea报表已经不能满足他们。
我们需要一个新的BI解决方案
对我们来说数据不同步还可以解决,毕竟是偶然发生的,处理一下就可以了。但是BI工具有很大的问题,不能满足业务已经进化的需求。所以我们需要一个新的BI解决方案:
- 首先它要足够灵活,不能发布之后用户什么都不能做,只能看,我们希望它的维度和指标可以快速整合。
- 第二,门槛要低,我们不可能希望业务像BI工程师学习它的开发是怎么做的,所以它要入门非常简单。其次,要能够用语言描述自己的需求,而不是用SQL,让商务这种感性思维的人学SQL简直是不可能的,所以要能用语言描述他们自己想要什么。
- 第三就是开发周期短,业务想看什么,所有的数据都需要提需求,需求分析,排期实施,提变更又要排期实施,这时候虽然说业务发展不是一天一变,但很多业务试错的时间非常快,数据开发出来黄花菜都凉了。所以希望有一个新的BI方案解决这三个问题。
我们看了一下市面上的商业工具并不适合,并且这样灵活的方案需要我们有更强的掌控性,于是我们就开始走向了自研的道路。
第2阶段
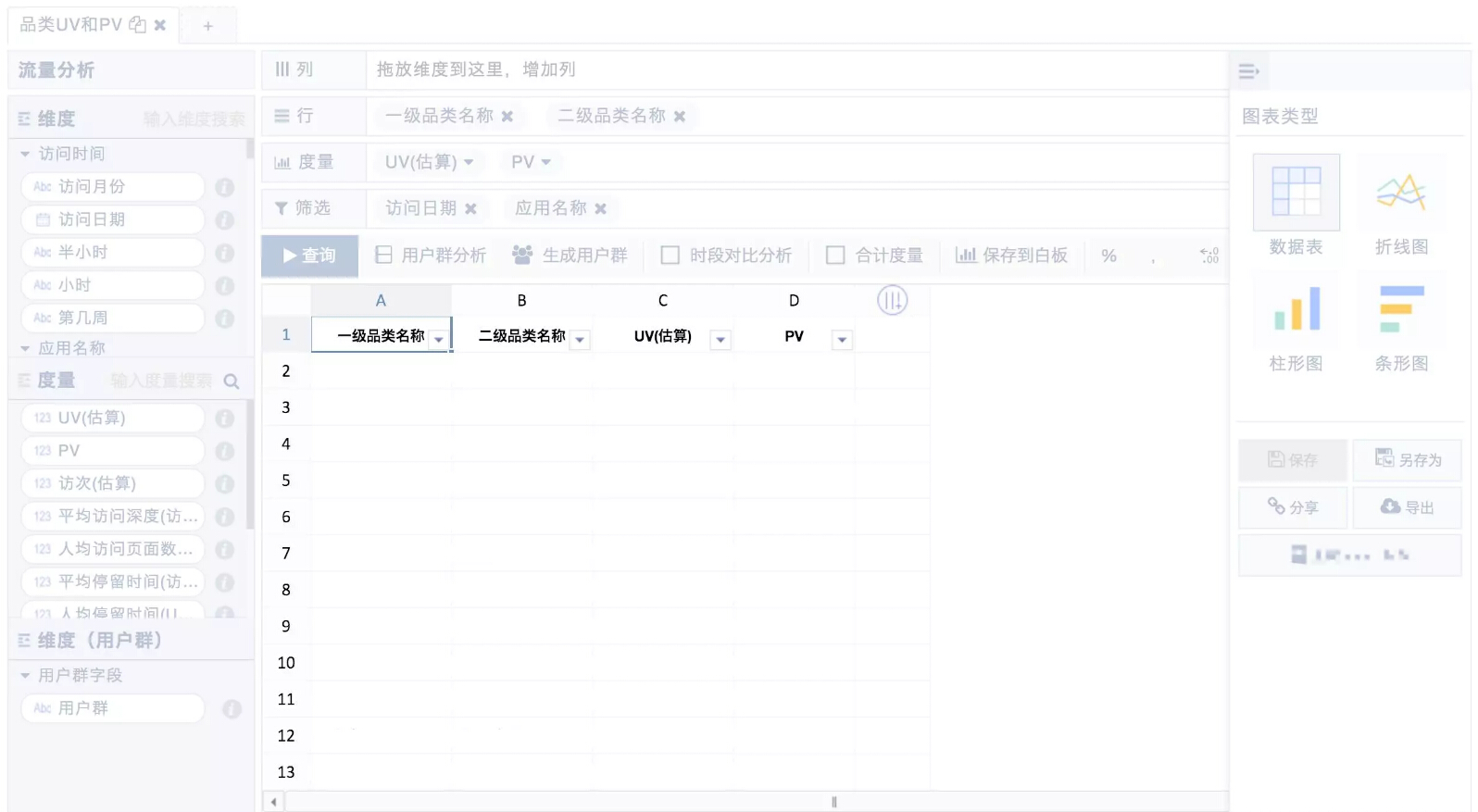
我们进入了OLAP分析的第二个阶段,这时前端开发了一个产品叫自助分析平台,这个平台上用户可以通过拖拉拽把左边的维度指标自己组合拖到上面,组成自己想看的结果。结果查询出来后可以用表格也可以图形进行展示,包括折线、柱状、条形图,这里面所有的分析结果都是可保存、可分享、可下载的。
利用这样的工具可以帮助分析师或者业务人员更好地自由的组合刚才我们所说的一切,并且灵活性、门槛低的问题其实也都迎刃而解了。而且像这样拖拉拽是非常容易学习的,只要去学习怎么把业务逻辑转化成一个数据的逻辑描述,搞懂要怎么转化成什么形式,行里面显示什么,列显示什么,度量是什么就可以了,虽然有一点的学习曲线,但比起学习完整的BI工具,门槛降低了很多。
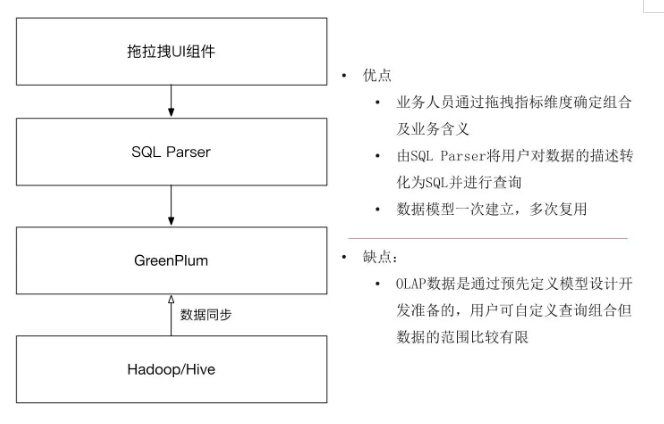
前端是这样的产品,后端也要跟着它一起变。首先前端是一个拖拉拽的UI组件,这个组件意味着用传统的选择SQL,直接形成报表的方式已经不可行了,因为所有的一切不管是维度指标都是用户自己组合的,所以我们需要一个SQL Parser帮助用户把它的数据的描述转化成SQL,还要进行性能的调优,保证以一个比较高的性能反馈数据。
所以我们就开发了一个SQL Parser用来承接组件生成的数据结构,同时用SQL Parser直接去OLAP数据。还是通过预计算的方式,把我们需要的指标维度算好同步到SQL Parser。这样的模型一旦建立,可以多次复用。
但我们知道这个计算方案有几个明显的缺点:第一,所有的数据必须经过计算,计算范围之外的不能组合;第二,还是有数据同步的问题,第三是什么?其实预计算的时候大家会经常发现我们认为这些组合是有效的,用户可能不会查,但不去查这次计算就浪费掉了。是不是有更好的办法去解决这种现状?
我们需要一个新的OLAP计算引擎
从这个角度来看GreenPlum已经不能满足我们了,就算预先计算好也不能满足,需要一个新的OLAP计算引擎。这个新的引擎需要满足三个条件:
- 没有预计算的模型。因为预计算的缺点是没有传统意义上的数据汇总层,直接从DW层明细数据上的直接计算。而且我们所有的业务场景化,只要DW层有这个数据就不用再开发了,直接拿来用就可以了。之前我们讲到数据先汇总,有些缓慢变化是需要刷数据的,这个头很疼,也要解决。
- 速度要足够快。数据平均10秒返回,看上去挺慢的,不是秒出,为什么当时定这样的目标?因为刚才讲到之前的开发方式业务要排期等,这个周期非常长,如果现在通过一个可以随意组合的方式去满足它90%以上的需求,其实它在真正做的时候对性能的要求并没有那么严苛。我们也不希望这边查询的时候因为等待数据把自己分析的思路或者日程打乱了,10秒可能是比较合适的。然后,因为我们的数据仓库DW层用维度建模,所以这个OLAP引擎必须支持Join。
- 最后是支持横向扩展,计算能力可通过计算节点扩容获得提高,同时没有DB同步的问题。这里面东西还是挺多的,怎么解决这个问题呢?我们把需求分解了一下。

首先查询速度要快,我们需要一个SQL内在的高并发。其次用纯内存计算代替内存+硬盘的计算,内存+硬盘的计算讲的就是Hive,Hive一个SQL启动一下,包括实际计算过程都是很慢的。第二个是数据模型,刚才讲到数据仓库才是维度建模的,必须支持Join,像外面比较流行的Druid或者ES的方案其实不适用了。第三个就是数据不需要同步,意味着需要数据存在HDFS上,计算引擎要能够感知到Hive的Metadata。第四个是通过扩容提高计算能力,如果想做到完全没有服务降级的扩容,一个计算引擎没有状态是最好的,同时计算的节点互相无依赖。最后一点是方案成熟稳定,因为这是在尝试新的OLAP方案,如果这个OLAP方案不稳定,直接影响到了用户体验,我们希望线上出问题时我们不至于手忙脚乱到没办法快速解决。
Presto:Facebook贡献的开源MPP OLAP引擎
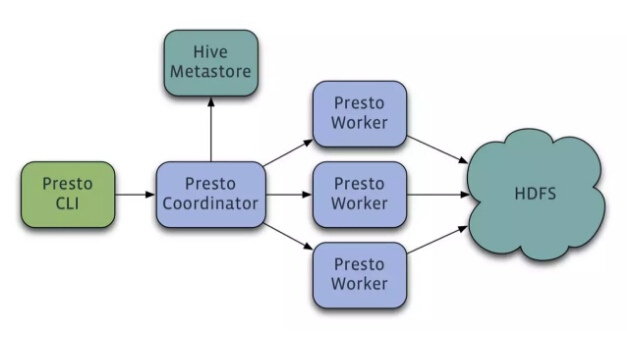
这时候Presto进入我们的视野,它是Facebook贡献的开源MPP OLAP引擎。这是一个红酒的名字,因为开发组所有的人都喜欢喝这个牌子的红酒,所以把它命名为这个名字。作为MPP引擎,它的处理方式是把所有的数据Scan出来,通过Hash的方法把数据变成更小的块,让不同的节点并发,处理完结果后快速地返回给用户。我们看到它的逻辑架构也是这样,发起一个SQL,然后找这些数据在哪些HDFS节点上,然后分配后做具体的处理,最后再把数据返回。
为什么是Presto
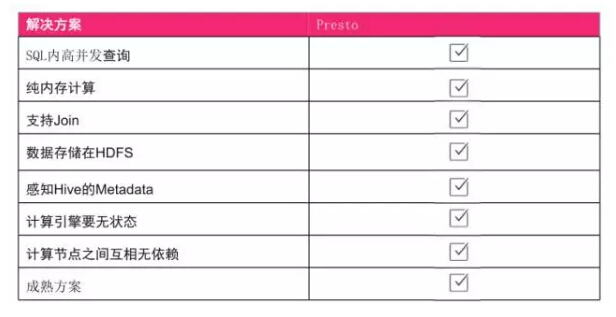
从原理上来看,高并发查询因为是MPP引擎的支持。纯内存计算,它是纯内存的,跟硬盘没有任何交互。第三,因为它是一个SQL引擎,所以支持Join。另外数据没有存储,数据直接存储在HDFS上。计算引擎没有状态,计算节点互相无依赖都是满足的。另外它也是一个成熟方案,Facebook本身也是大厂,国外有谷歌在用,国内京东也有自己的版本,所以这个东西其实还是满足我们需求的。
Presto性能测试
我们在用之前做了POC。我们做了一个尝试,把在我们平台上常用的SQL(不用TPCH的原因是我们平台的SQL更适合我们的场景),在GP和Presto两个计算引擎上,用相同的机器配置和节点数同时做了一次基准性能测试,可以看到结果是非常令人欢喜的。
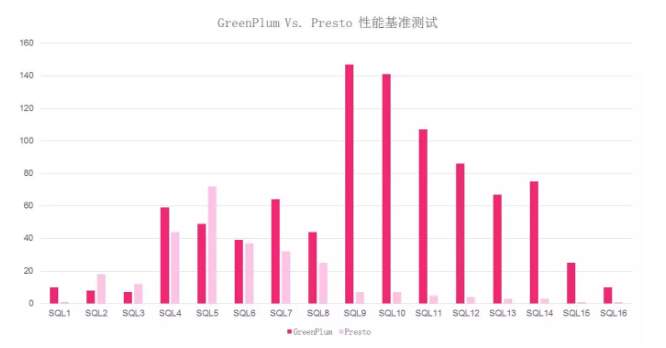
整体而言相同节点的Presto比GreenPlum的性能提升70%,而且SQL9到SQL16都从100多秒下降到10秒,可见它的提升是非常明显的。
当我们做完性能测试时,我们一个专门做引擎开发的同学叫了起来,说就你了,用Presto替代GreenPlum。
第3阶段
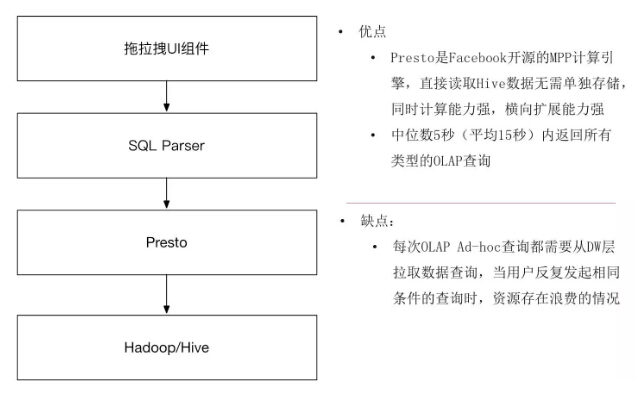
在Presto引进来之后,我们发现整个数据架构变得非常顺畅,上层用拖拉拽的UI组件生成传给SQL到Parser,然后传给Presto执行。不管是流量数据,还是埋点,还是曝光数据返回非常快,同时我们也把场景扩展到包括订单、销售之类的事务型分析上。用了之后中位数返回时间5秒钟,平均返回时间15秒,基本上这段时间可以返回所有的OLAP查询。因为用了DW数据,维度更丰富,大多数的需求问题被解决。
用了Presto之后用户的第一反应是为什么会这么快,到底用了什么黑科技。但是运行了一段时间后我们观察了用户的行为是什么样的,到底在查询什么样的SQL,什么维度和指标的组合,希望还能再做一些优化。
最快的计算方法是不计算
在这个时候我们突然发现,即使是用户自由组合的指标也会发现不同业务在相同业务场景下会去查完全相同的数据组合。比如很多用户会查同一渠道的销售流量转化,现在的方案会有什么问题呢?完全相同的查询也需要到上面真正执行一遍,实际上如果完全相同的可以直接返回结果不用计算了。所以我们就在想怎么解决这个问题?实际这里有一个所谓的理论——就是最快的计算就是不计算,怎么做呢?如果我们能够模仿Oracle的BGA,把计算结果存储下来,用户查询相同时可以把数据取出来给用户直接返回就好了。
于是这里就讲到了缓存复用。第一个阶段完全相同的直接返回,第二个阶段更进一步,相对来说更复杂一些,如果说提出一个新的SQL,结果是上一个的,我们也不结算,从上一个结果里面直接做二次处理,把缓存的数据拿出来反馈给用户。除了这个亮点之外,其实缓存很重要的就是生命周期管理,非常复杂,因为数据不断地更新,缓存如果不更新可能查出来的数据不对,在数据库会说这是脏读或者幻影读,我们希望缓存的生命周期可以自己管理,不希望是通过超时来管理缓存,我们更希望缓存可以管理自己的生命周期,跟源数据同步生命周期,这样缓存使用效率会是最好的。
Redis:成熟的缓存方案
说到缓存要提到Redis,这是很多生产系统上大量使用的,它也非常适合OLAP。
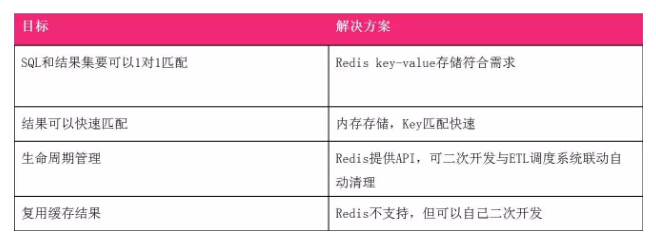
首先我们想要的是SQL跟结果一对一匹配,它是非常符合这个需求的。其次我们希望缓存更快的返回,Redis是纯内存的存储,返回速度非常快,一般是毫秒级。第三个生命周期管理,它提供API,我们做二次开发,跟我们ETL调度系统打通,处理更新时就可以通知什么样的数据可以被用到。而缓存复用是不支持的,我们可以自己来做。
第3.5阶段
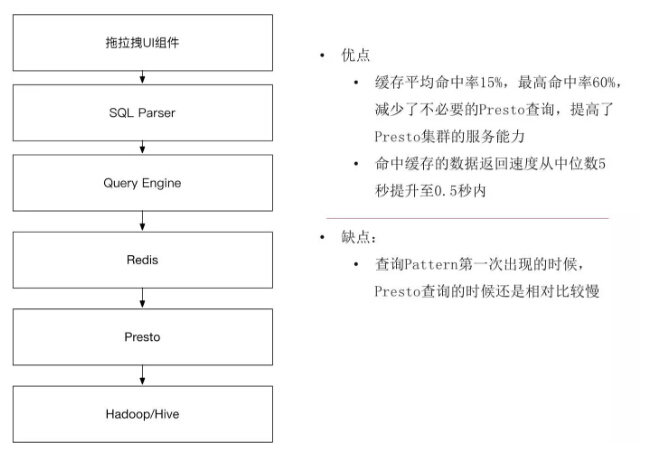
于是这时就把Redis的方案引入进来。
引入Redis之后带来一个新的挑战,我们不是只有一个计算引擎,我们暂时先把Redis称为一个计算引擎,因为数据可能在Redis,也可能需要通过Presto去把数据读出来,这时我们在刚才生成SQL之后还加入了新的一个组件,Query Engine的目的就是在不同的引擎之间做路由,找到最快返回数据的匹配。比如说我们一个SQL发下来,它会先去找Redis,看在Redis找有没有这个SQL缓存的记录,有就直接返回给用户,没有再到Presto上面查询。上线了之后,我们观察了结果,结果也是非常不错的,发现平均的缓存命中率达到15%,意味着这15%的查询都是秒出。
因为我们有不同的主题,流量主题、销售、收藏、客户,类似不同的主题,用户查询的组合不一样,特殊的场景下,命中率达到60%,这样除去缓存的返回速度非常快之外,缓存也有好处,就是释放了Presto的计算能力,原先需要跑一次的查询便不需要了。释放出来的内存和CPU就可以给其它的查询提供计算能力了。
空间换时间:OLAP分析的另一条途径
缓存的方案实施之后,看上去很不错了,这时候我们又引起了另一次思考,缓存现在是在做第二次查询的提速,但我们想让第一次的速度也可以更快一些。说到第一次的查询,我们要走回老路了,我们说空间换时间,是提升第一次查询一个最显而易见的办法。
空间换时间,如果说OLAP ad-hoc查询从事先计算好的结果里查询,那是不是返回速度也会很快?其次,空间换时间要支持维度建模,它也要支持Join。最后希望数据管理简单一些,之前讲到为什么淘汰了GreenPlum,是因为数据同步复杂,数据的预计算不好控制,所以希望数据管理可以更简单一些。预计算的过程和结果的同步不需要二次开发,最好由OLAP计算引擎自己管理。同时之前讲到我们会有一个预先设计存在过度设计的问题,这个问题怎么解决?我们目前的场景是有Presto来兜底的,如果没有命中CUBE,那兜底的好处就是说我们还可以用Presto来承载计算,这让设计预计算查询的时候它的选择余地会更多。它不需要完全根据用户的需求或者业务需求把所有的设计在里面,只要挑自己合适的就可以,对于那些没有命中的SQL,虽然慢了一点,但给我们带来的好处就是管理的成本大大降低了。
Kylin:eBay贡献的开源MOLAP引擎
Kylin是由eBay开源的一个引擎,Kylin把数据读出来做计算,结算的结果会被存在HBase里,通过HBase做Ad-hoc的功能。HBase的好处是有索引的,所以做Ad-hoc的性能非常好。
为什么是Kylin
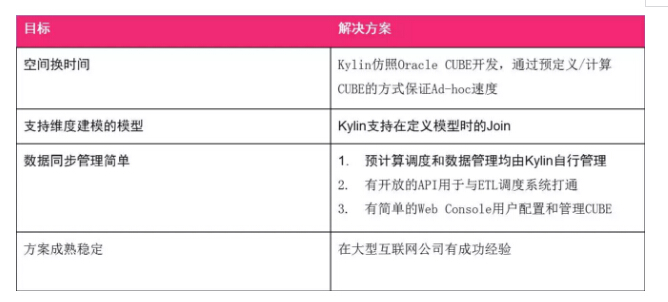
首先空间换时间,我们在刚开始引入Kylin时跟Kylin开发聊过,他们借鉴了Oracle CUBE的概念,对传统数据库开发的人来说很容易理解概念和使用。支持维度建模自然支持也Join。预计算的过程是由Kylin自己管理的,也开放了API,与调度系统打通做数据刷新。另外Kylin是在eBay上很大的、美团也是投入了很大的精力的有成功经验的产品,所以很容易地引进来了。
第4阶段
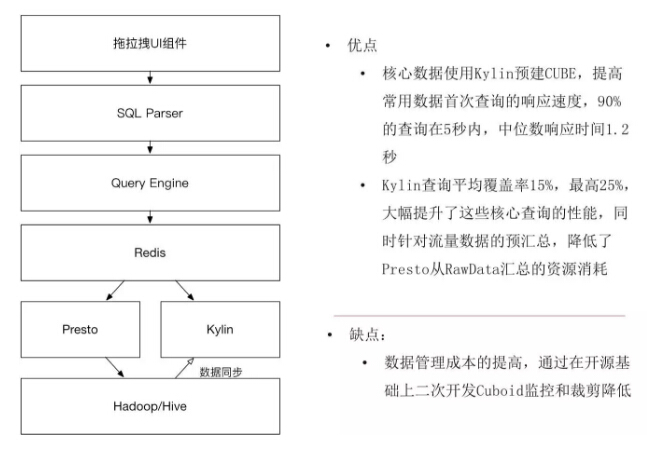
于是,我们进入了唯品会OLAP分析架构的第四阶段:Hybird:Presto的ROLAP和Kylin的MOLAP结合发挥各自优势,Redis缓存进一步提升效率。
查询在Query Engine根据Redis-> Kylin再到Presto的优先级进行路由探查,在找到第一个可命中的路径之后,转向对应的引擎进行计算并给用户返回结果。Kylin的引入主要用于提升核心指标的OLAP分析的首次响应速度。这个状态可以看到Kylin的查询覆盖率平均15%,最高25%,大幅提升核心数据的查询。同时流量几十亿、几百亿的数据从Kylin走也大大地减轻了Presto。虽然说这样的架构看起来挺复杂的,但这样的一个架构出来之后,基本上满足了90%的OLAP分析了。
OLAP分析的技术进化是一个迷宫而不是金字塔
经过这么长一段时间的演进和一些摸索之后,我们觉得OLAP分析的技术是它的进化是一个迷宫,不是一个金字塔。过去说升级,像金字塔往上攀登,但实际上在刚才的过程大家发现实际上它更是像走迷宫,每个转角其实是都碰到了问题,在这个转角,在当时的情况下找最佳的方案。
不是做了大数据之后放弃了计算,也不是做了大数据不再考虑数据同步的问题。其实可以发现很多传统数据仓库或者RBDMS的索引、CUBE之类的概念慢慢重新回到了大数据的视野里面。对我们而言,我们认为更多的时候,我们在做一些大数据的新技术演进时更多的是用更优秀的技术来做落地和实现,而不是去拒绝过去的一些大家感觉好像比较陈旧的的逻辑或概念。所以说对每个人来说,适合自己业务的场景方案才是最好的方案。
唯品会在开源计算引擎上所做的改进
接下来讲一下我们在开源计算引擎上做的改进。Presto和Kylin的角度不一样,所以我们在优化的方向上也不同。Presto主要注重提升查询性能,减少计算量,提升实时性。Kylin最主要优化维表查找,提高CUBE的利用率。
Presto上的改进
在提升查询性能上:
新增Hint语法,首先做的也是最重要的改动是在Presto中增加了一个Hint的语法,可以在SQL Join级别动态设置策略,通过编译时让让join在replica和distribute两者之间设置,提高Join效率;
监控告警JOIN数据倾斜,通过减少数据倾斜提高执行效率;
增加多集群LOAD BALANCE,可平衡不同集群间计算量;
经过改造,Presto的查询实时性大幅提升。
在减少计算量上:
新增Kylin Connector,通过CUBE探嗅自动匹配SQL子查询中可以命中Kylin CUBE的部分,从Kylin提取数据后做进一步的计算,降低查询计算量;
经过改造,Presto升级为Hybird OLAP引擎,同时支持ROLAP和MOLAP两种模式。
在提高实时性上:
重写Kafka Connector,支持热更新Kafka中Topic、Message 和表/列的映射定义;
支持Kafka按offset读取数据,支持PB格式,提高Kafka数据源的读取效率;
经过改造,Presto不仅是离线OLAP引擎,准实时数据处理的能力也得到提高。
Kylin上的改进
在优化维表查找上:
通过引入Presto解决Kylin亿级维表实时Lookup OOM的问题,通过Presto查询替换了原有复杂的维表映射值查找机制;
经过改造,唯品会版的Kylin相比开源版本极大的扩展了对业务场景的支持程度.
在提升CUBE利用率上:
开发CUBE Advisor,通过统计分析总结合适的维度和指标组合辅助开发选择判断新建CUBE的策略,减少冗余和经验判断上的误差;
提供CUBE命中率监控,形成CUBE新建、使用到总结升级的闭环;
经此改造,CUBE命中率大幅提高,减少了资源的浪费提升了响应速度,经过这样的改造,开发不再只是根据自己的经验或者盲目建立,而是有数据可依。
OLAP方案升级方向
最后我们讲一下OLAP升级方向。
对于Presto,我们将探索如何用RowID级别的索引的存储格式替换现有RowGroup级别索引的ORC File,在数据Scan级别尽可能精确的获取所需的数据,减少数据量,同时提高OLAP查询的并发度,应对大量用户并发OLAP分析场景。
对于Kylin,我们会尝试Streaming Cubing,使得Kylin OLAP分析从离线数据向实时数据迁移,以及探索Lamda Cubing,实现实时离线CUBE无缝融合。
最后,尝试探索下一代的方案,需要有更强的实时离线融合,与更强的原始数据和汇总的数据的融合,以及更强的数据处理能力,短期来讲没有更好的方案,希望跟大家一起讨论。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 唯品会海量实时OLAP分析技术升级之路

