Hive是支持索引的,但基本没用过,只做了下试验。
为什么大家都不用,肯定有它的弊端。
Hive索引机制:
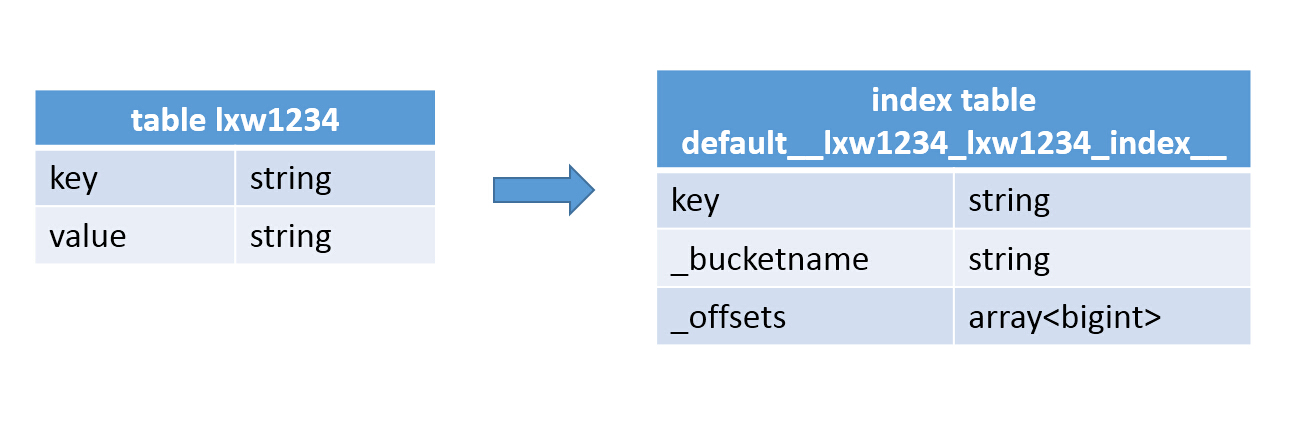
在指定列上建立索引,会产生一张索引表(Hive的一张物理表),里面的字段包括,索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量;
在执行索引字段查询时候,首先额外生成一个MR job,根据对索引列的过滤条件,从索引表中过滤出索引列的值对应的hdfs文件路径及偏移量,输出到hdfs上的一个文件中,然后根据这些文件中的hdfs路径和偏移量,筛选原始input文件,生成新的split,作为整个job的split,这样就达到不用全表扫描的目的。
Hive索引建立过程:
创建索引:
create index lxw1234_index on table lxw1234(key) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;
之后在Hive中会创建一张索引表,也是物理表:
Hive index Hive索引
其中,索引表中key字段,就是原表中key字段的值,_bucketname 字段,代表数据文件对应的HDFS文件路径,_offsets 代表该key值在文件中的偏移量,有可能有多个偏移量,因此,该字段类型为数组。
其实,索引表就相当于一个在原表索引列上的一个汇总表。
生成索引数据
alter index lxw1234_index on lxw1234 rebuild;
用一个MR任务,以table lxw1234的数据作为input,将索引字段key中的每一个值及其对应的HDFS文件和偏移量输出到索引表中。
自动使用索引
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; SET hive.optimize.index.filter=true; SET hive.optimize.index.filter.compact.minsize=0;
查询时候索引如何起效:
select * from lxw1234 where key = '13400000144_1387531071_460606566970889';
- 首先用一个job,从索引表中过滤出key = ‘13400000144_1387531071_460606566970889’的记录,将其对应的HDFS文件路径及偏移量输出到HDFS临时文件中
- 接下来的job中以临时文件为input,根据里面的HDFS文件路径及偏移量,生成新的split,作为查询job的map任务input
- 不使用索引时候,如下图所示:

Hive index Hive索引
- table lxw1234的每一个split都会用一个map task去扫描,但其实只有split2中有我们想要的结果数据,map task1和map task3造成了资源浪费。
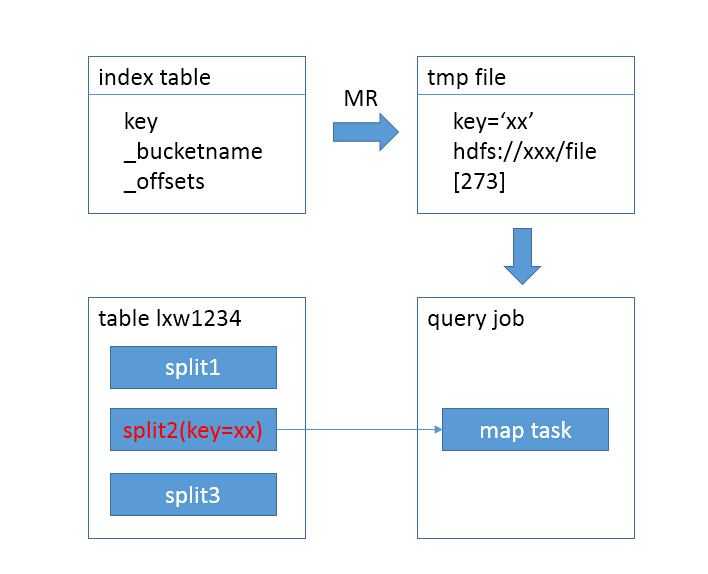
- 使用索引后,如下图所示:
Hive index Hive索引
- 查询提交后,先用一个MR,扫描索引表,从索引表中找出key=’xx’的记录,获取到HDFS文件名和偏移量;
- 接下来,直接定位到该文件中的偏移量,用一个map task即可完成查询,其最终目的就是为了减少查询时候的input size
手动使用索引
- 其实就是手动完成从索引表中过滤数据的部分,将过滤出来的数据load 到HDFS临时文件,供查询任务使用
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; Insert overwrite directory "/tmp/lxw1234_index_data" select `_bucketname`, `_offsets` from default__lxw1234_lxw1234_index__ where key = '13400000144_1387531071_460606566970889'; ##指定索引数据文件 SET hive.index.compact.file=/tmp/ll1_index_data; SET hive.optimize.index.filter=false; SET hive.input.format=org.apache.hadoop.hive.ql.index.compact.HiveCompactIndexInputFormat; select * from lxw1234 where key = '13400000144_1387531071_460606566970889';
从以上过程可以看出,Hive索引的使用过程比较繁琐:
- 每次查询时候都要先用一个job扫描索引表,如果索引列的值非常稀疏,那么索引表本身也会非常大;
- 索引表不会自动rebuild,如果表有数据新增或删除,那么必须手动rebuild索引表数据;
如果觉得本博客对您有帮助,请 赞助作者 。

