在实际业务场景下,经常会遇到在Hive、MapReduce、Spark中需要生成唯一的数值型ID。
一般常用的做法有:
- MapReduce中使用1个Reduce来生成;
- Hive中使用row_number分析函数来生成,其实也是1个Reduce;
- 借助HBase或Redis或Zookeeper等其它框架的计数器来生成;
数据量不大的情况下,可以直接使用1和2方法来生成,但如果数据量巨大,1个Reduce处理起来就非常慢。
在数据量非常大的情况下,如果你仅仅需要唯一的数值型ID,注意:不是需要”连续的唯一的数值型ID”,那么可以考虑采用本文中介绍的方法,否则,请使用第3种方法来完成。
Spark中生成这样的非连续唯一数值型ID,非常简单,直接使用zipWithUniqueId()即可。
关于zipWithUniqueId,可参考:http://lxw1234.com/archives/2015/07/352.htm
参考zipWithUniqueId()的方法,在MapReduce和Hive中,实现如下:
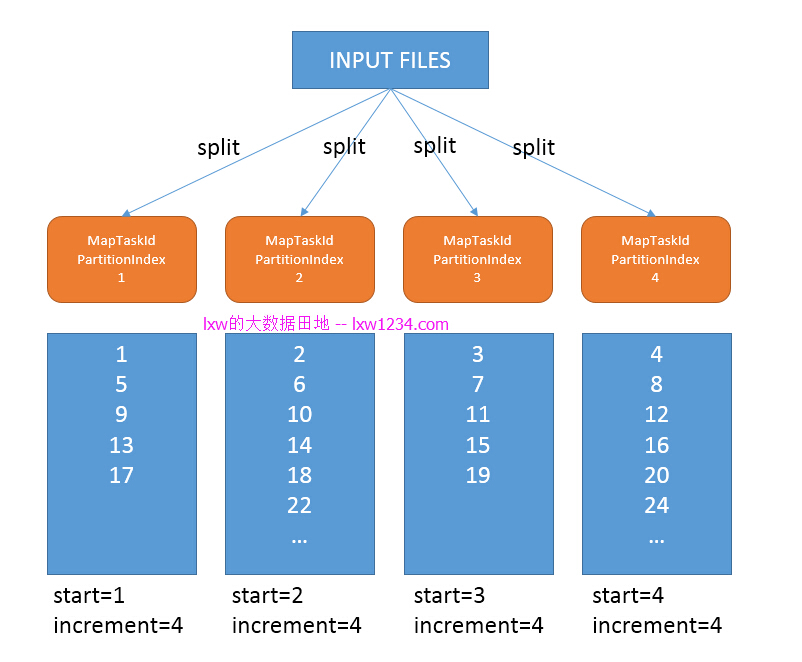
在Spark中,zipWithUniqueId是通过使用分区Index作为每个分区ID的开始值,在每个分区内,ID增长的步长为该RDD的分区数,那么在MapReduce和Hive中,也可以照此思路实现,Spark中的分区数,即为MapReduce中的Map数,Spark分区的Index,即为Map Task的ID。Map数,可以通过JobConf的getNumMapTasks(),而Map Task ID,可以通过参数mapred.task.id获取,格式如:attempt_1478926768563_0537_m_000004_0,截取m_000004_0中的4,再加1,作为该Map Task的ID起始值。注意:这两个只均需要在Job运行时才能获取。另外,从图中也可以看出,每个分区/Map Task中的数据量不是绝对一致的,因此,生成的ID不是连续的。
下面的UDF可以在Hive中直接使用:
package com.lxw1234.hive.udf;
import org.apache.hadoop.hive.ql.exec.MapredContext;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.LongWritable;
@UDFType(deterministic = false, stateful = true)
public class RowSeq2 extends GenericUDF {
private static LongWritable result = new LongWritable();
private static final char SEPARATOR = '_';
private static final String ATTEMPT = "attempt";
private long initID = 0l;
private int increment = 0;
@Override
public void configure(MapredContext context) {
increment = context.getJobConf().getNumMapTasks();
if(increment == 0) {
throw new IllegalArgumentException("mapred.map.tasks is zero");
}
initID = getInitId(context.getJobConf().get("mapred.task.id"),increment);
if(initID == 0l) {
throw new IllegalArgumentException("mapred.task.id");
}
System.out.println("initID : " + initID + " increment : " + increment);
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments)
throws UDFArgumentException {
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
result.set(getValue());
increment(increment);
return result;
}
@Override
public String getDisplayString(String[] children) {
return "RowSeq-func()";
}
private synchronized void increment(int incr) {
initID += incr;
}
private synchronized long getValue() {
return initID;
}
//attempt_1478926768563_0537_m_000004_0 // return 0+1
private long getInitId (String taskAttemptIDstr,int numTasks)
throws IllegalArgumentException {
try {
String[] parts = taskAttemptIDstr.split(Character.toString(SEPARATOR));
if(parts.length == 6) {
if(parts[0].equals(ATTEMPT)) {
if(!parts[3].equals("m") && !parts[3].equals("r")) {
throw new Exception();
}
long result = Long.parseLong(parts[4]);
if(result >= numTasks) { //if taskid >= numtasks
throw new Exception("TaskAttemptId string : " + taskAttemptIDstr
+ " parse ID [" + result + "] >= numTasks[" + numTasks + "] ..");
}
return result + 1;
}
}
} catch (Exception e) {}
throw new IllegalArgumentException("TaskAttemptId string : " + taskAttemptIDstr
+ " is not properly formed");
}
}
有一张去重后的用户id(字符串类型)表,需要位每个用户id生成一个唯一的数值型seq:
ADD jar file:///tmp/udf.jar; CREATE temporary function seq2 as 'com.lxw1234.hive.udf.RowSeq2'; hive>> desc lxw_all_ids; OK id string Time taken: 0.074 seconds, Fetched: 1 row(s) hive> select * from lxw_all_ids limit 5; OK 01779E7A06ABF5565A4982_cookie 031E2D2408C29556420255_cookie 03371ADA0B6E405806FFCD_cookie 0517C4B701BC1256BFF6EC_cookie 05F12ADE0E880455931C1A_cookie Time taken: 0.215 seconds, Fetched: 5 row(s) hive> select count(1) from lxw_all_ids; 253402337 hive> create table lxw_all_ids2 as select id,seq2() as seq from lxw_all_ids; … Hadoop job information for Stage-1: number of mappers: 27; number of reducers: 0 …
该Job使用了27个Map Task,没有使用Reduce,那么将会产生27个结果文件。
再看结果表中的数据:
hive> select * from lxw_all_ids2 limit 10; OK 766CA2770527B257D332AA_cookie 1 5A0492DB0000C557A81383_cookie 28 8C06A5770F176E58301EEF_cookie 55 6498F47B0BCAFE5842B83A_cookie 82 6DA33CB709A23758428A44_cookie 109 B766347B0D27925842AC2D_cookie 136 5794357B050C99584251AC_cookie 163 81D67A7B011BEA5842776C_cookie 190 9D2F8EB40AEA525792347D_cookie 217 BD21077B09F9E25844D2C1_cookie 244 hive> select count(1),count(distinct seq) from lxw_all_ids2; 253402337 253402337
limit 10只从第一个结果文件,即MapTaskId为0的结果文件中拿了10条,这个Map中,start=1,increment=27,因此生成的ID如上所示。
count(1),count(distinct seq)的值相同,说明seq没有重复值,你可以试试max(seq),结果必然大于253402337,说明seq是”非连续唯一数值型ID“.
如果觉得本博客对您有帮助,请 赞助作者 。



