HiveжҳҜж”ҜжҢҒзҙўеј•зҡ„пјҢдҪҶеҹәжң¬жІЎз”ЁиҝҮпјҢеҸӘеҒҡдәҶдёӢиҜ•йӘҢгҖӮ
дёәд»Җд№ҲеӨ§е®¶йғҪдёҚз”ЁпјҢиӮҜе®ҡжңүе®ғзҡ„ејҠз«ҜгҖӮ
Hiveзҙўеј•жңәеҲ¶пјҡ
еңЁжҢҮе®ҡеҲ—дёҠе»әз«Ӣзҙўеј•пјҢдјҡдә§з”ҹдёҖеј зҙўеј•иЎЁпјҲHiveзҡ„дёҖеј зү©зҗҶиЎЁпјүпјҢйҮҢйқўзҡ„еӯ—ж®өеҢ…жӢ¬пјҢзҙўеј•еҲ—зҡ„еҖјгҖҒиҜҘеҖјеҜ№еә”зҡ„HDFSж–Ү件и·Ҝеҫ„гҖҒиҜҘеҖјеңЁж–Ү件дёӯзҡ„еҒҸ移йҮҸ;
еңЁжү§иЎҢзҙўеј•еӯ—ж®өжҹҘиҜўж—¶еҖҷпјҢйҰ–е…ҲйўқеӨ–з”ҹжҲҗдёҖдёӘMR jobпјҢж №жҚ®еҜ№зҙўеј•еҲ—зҡ„иҝҮж»ӨжқЎд»¶пјҢд»Һзҙўеј•иЎЁдёӯиҝҮж»ӨеҮәзҙўеј•еҲ—зҡ„еҖјеҜ№еә”зҡ„hdfsж–Ү件и·Ҝеҫ„еҸҠеҒҸ移йҮҸпјҢиҫ“еҮәеҲ°hdfsдёҠзҡ„дёҖдёӘж–Ү件дёӯпјҢ然еҗҺж №жҚ®иҝҷдәӣж–Ү件дёӯзҡ„hdfsи·Ҝеҫ„е’ҢеҒҸ移йҮҸпјҢзӯӣйҖүеҺҹе§Ӣinputж–Ү件пјҢз”ҹжҲҗж–°зҡ„split,дҪңдёәж•ҙдёӘjobзҡ„split,иҝҷж ·е°ұиҫҫеҲ°дёҚз”Ёе…ЁиЎЁжү«жҸҸзҡ„зӣ®зҡ„гҖӮ
Hiveзҙўеј•е»әз«ӢиҝҮзЁӢпјҡ
еҲӣе»әзҙўеј•пјҡ
create index lxw1234_index on table lxw1234(key) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;
д№ӢеҗҺеңЁHiveдёӯдјҡеҲӣе»әдёҖеј зҙўеј•иЎЁпјҢд№ҹжҳҜзү©зҗҶиЎЁпјҡ
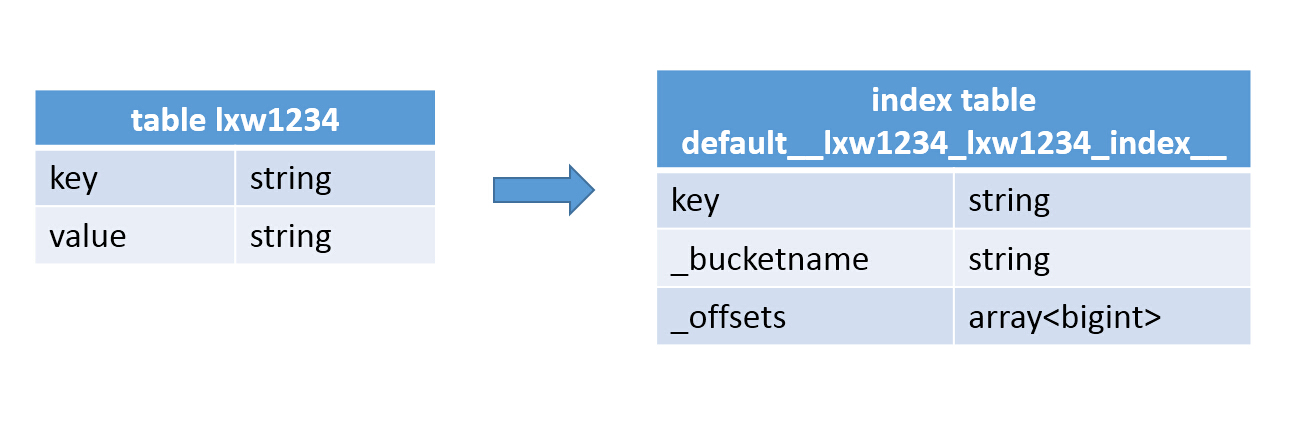
Hive index Hiveзҙўеј•
е…¶дёӯпјҢзҙўеј•иЎЁдёӯkeyеӯ—ж®өпјҢе°ұжҳҜеҺҹиЎЁдёӯkeyеӯ—ж®өзҡ„еҖјпјҢ_bucketname еӯ—ж®өпјҢд»ЈиЎЁж•°жҚ®ж–Ү件еҜ№еә”зҡ„HDFSж–Ү件и·Ҝеҫ„пјҢ_offsets д»ЈиЎЁиҜҘkeyеҖјеңЁж–Ү件дёӯзҡ„еҒҸ移йҮҸпјҢжңүеҸҜиғҪжңүеӨҡдёӘеҒҸ移йҮҸпјҢеӣ жӯӨпјҢиҜҘеӯ—ж®өзұ»еһӢдёәж•°з»„гҖӮ
е…¶е®һпјҢзҙўеј•иЎЁе°ұзӣёеҪ“дәҺдёҖдёӘеңЁеҺҹиЎЁзҙўеј•еҲ—дёҠзҡ„дёҖдёӘжұҮжҖ»иЎЁгҖӮ
з”ҹжҲҗзҙўеј•ж•°жҚ®
alter index lxw1234_index on lxw1234 rebuild;
з”ЁдёҖдёӘMRд»»еҠЎпјҢд»Ҙtable lxw1234зҡ„ж•°жҚ®дҪңдёәinputпјҢе°Ҷзҙўеј•еӯ—ж®өkeyдёӯзҡ„жҜҸдёҖдёӘеҖјеҸҠе…¶еҜ№еә”зҡ„HDFSж–Ү件е’ҢеҒҸ移йҮҸиҫ“еҮәеҲ°зҙўеј•иЎЁдёӯгҖӮ
иҮӘеҠЁдҪҝз”Ёзҙўеј•
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; SET hive.optimize.index.filter=true; SET hive.optimize.index.filter.compact.minsize=0;
жҹҘиҜўж—¶еҖҷзҙўеј•еҰӮдҪ•иө·ж•Ҳпјҡ
select * from lxw1234 where key = '13400000144_1387531071_460606566970889';
- йҰ–е…Ҳз”ЁдёҖдёӘjobпјҢд»Һзҙўеј•иЎЁдёӯиҝҮж»ӨеҮәkey = ‘13400000144_1387531071_460606566970889’зҡ„и®°еҪ•пјҢе°Ҷе…¶еҜ№еә”зҡ„HDFSж–Ү件и·Ҝеҫ„еҸҠеҒҸ移йҮҸиҫ“еҮәеҲ°HDFSдёҙж—¶ж–Ү件дёӯ
- жҺҘдёӢжқҘзҡ„jobдёӯд»Ҙдёҙж—¶ж–Ү件дёәinputпјҢж №жҚ®йҮҢйқўзҡ„HDFSж–Ү件и·Ҝеҫ„еҸҠеҒҸ移йҮҸпјҢз”ҹжҲҗж–°зҡ„splitпјҢдҪңдёәжҹҘиҜўjobзҡ„mapд»»еҠЎinput
- дёҚдҪҝз”Ёзҙўеј•ж—¶еҖҷпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ

Hive index Hiveзҙўеј•
- table lxw1234зҡ„жҜҸдёҖдёӘsplitйғҪдјҡз”ЁдёҖдёӘmap taskеҺ»жү«жҸҸпјҢдҪҶе…¶е®һеҸӘжңүsplit2дёӯжңүжҲ‘们жғіиҰҒзҡ„з»“жһңж•°жҚ®пјҢmap task1е’Ңmap task3йҖ жҲҗдәҶиө„жәҗжөӘиҙ№гҖӮ
- дҪҝз”Ёзҙўеј•еҗҺпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
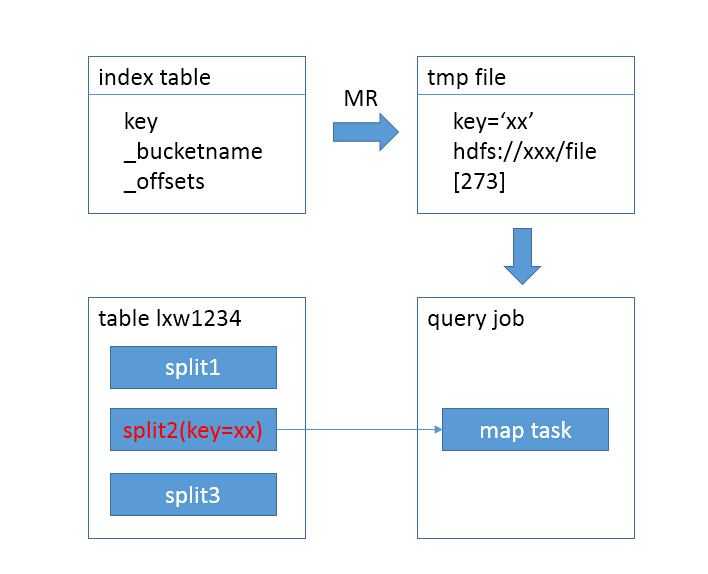
Hive index Hiveзҙўеј•
- жҹҘиҜўжҸҗдәӨеҗҺпјҢе…Ҳз”ЁдёҖдёӘMRпјҢжү«жҸҸзҙўеј•иЎЁпјҢд»Һзҙўеј•иЎЁдёӯжүҫеҮәkey=’xx’зҡ„и®°еҪ•пјҢиҺ·еҸ–еҲ°HDFSж–Ү件еҗҚе’ҢеҒҸ移йҮҸпјӣ
- жҺҘдёӢжқҘпјҢзӣҙжҺҘе®ҡдҪҚеҲ°иҜҘж–Ү件дёӯзҡ„еҒҸ移йҮҸпјҢз”ЁдёҖдёӘmap taskеҚіеҸҜе®ҢжҲҗжҹҘиҜўпјҢе…¶жңҖз»Ҳзӣ®зҡ„е°ұжҳҜдёәдәҶеҮҸе°‘жҹҘиҜўж—¶еҖҷзҡ„input size
жүӢеҠЁдҪҝз”Ёзҙўеј•
- е…¶е®һе°ұжҳҜжүӢеҠЁе®ҢжҲҗд»Һзҙўеј•иЎЁдёӯиҝҮж»Өж•°жҚ®зҡ„йғЁеҲҶпјҢе°ҶиҝҮж»ӨеҮәжқҘзҡ„ж•°жҚ®loadВ В В еҲ°HDFSдёҙж—¶ж–Ү件пјҢдҫӣжҹҘиҜўд»»еҠЎдҪҝз”Ё
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; Insert overwrite directory "/tmp/lxw1234_index_data" select `_bucketname`, `_offsets` from default__lxw1234_lxw1234_index__ where key = '13400000144_1387531071_460606566970889'; ##жҢҮе®ҡзҙўеј•ж•°жҚ®ж–Ү件 SET hive.index.compact.file=/tmp/ll1_index_data; SET hive.optimize.index.filter=false; SET hive.input.format=org.apache.hadoop.hive.ql.index.compact.HiveCompactIndexInputFormat; select * from lxw1234 where key = '13400000144_1387531071_460606566970889';
д»Һд»ҘдёҠиҝҮзЁӢеҸҜд»ҘзңӢеҮәпјҢHiveзҙўеј•зҡ„дҪҝз”ЁиҝҮзЁӢжҜ”иҫғз№Ғзҗҗпјҡ
- жҜҸж¬ЎжҹҘиҜўж—¶еҖҷйғҪиҰҒе…Ҳз”ЁдёҖдёӘjobжү«жҸҸзҙўеј•иЎЁпјҢеҰӮжһңзҙўеј•еҲ—зҡ„еҖјйқһеёёзЁҖз–ҸпјҢйӮЈд№Ҳзҙўеј•иЎЁжң¬иә«д№ҹдјҡйқһеёёеӨ§пјӣ
- зҙўеј•иЎЁдёҚдјҡиҮӘеҠЁrebuildпјҢеҰӮжһңиЎЁжңүж•°жҚ®ж–°еўһжҲ–еҲ йҷӨпјҢйӮЈд№Ҳеҝ…йЎ»жүӢеҠЁrebuildзҙўеј•иЎЁж•°жҚ®пјӣ
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » Hiveзҙўеј•

