Hive从1.1之后,支持使用Spark作为执行引擎,配置使用Spark On Yarn作为Hive的执行引擎,首先需要注意以下两个问题:
Hive的版本和Spark的版本要匹配;
具体来说,你使用的Hive版本编译时候用的哪个版本的Spark,那么就需要使用相同版本的Spark,可以在Hive的pom.xml中查看spark.version来确定;
Hive root pom.xml’s <spark.version> defines what version of Spark it was built/tested with.
Spark使用的jar包,必须是没有集成Hive的;
也就是说,编译时候没有指定-Phive.
一般官方提供的编译好的Spark下载,都是集成了Hive的,因此这个需要另外编译。
Note that you must have a version of Spark which does not include the Hive jars. Meaning one which was not built with the Hive profile.
如果不注意版本问题,则会遇到各种错误,比如:
Caused by: java.lang.NoClassDefFoundError: org/apache/hive/spark/client/Job Caused by: java.lang.ClassNotFoundException: org.apache.hive.spark.client.Job
我这里使用的环境信息如下:
hadoop-2.3.0-cdh5.0.0
apache-hive-2.0.0-bin
spark-1.5.0-bin-hadoop2.3
其中,Spark使用了另外编译的spark-assembly-1.5.0-hadoop2.3.0.jar。编译很简单,下载spark-1.5.0的源码,使用命令:
mvn -Pyarn -Phadoop-2.3 -Dhadoop.version=2.3.0-cdh5.0.0 -DskipTests -Dscala-2.10 clean package
首先在hive-site.xml中添加spark.home:
<property>
<name>spark.home</name>
<value>/usr/local/spark/spark-1.5.0-bin-hadoop2.3</value>
</property>
同时也配置了环境变量
export SPARK_HOME=/usr/local/spark/spark-1.5.0-bin-hadoop2.3
这两块应该只需要配置一处即可。
进入hive-cli命令行,使用set的方式设置以下参数:
set spark.master=yarn-cluster; //默认即为yarn-cluster模式,该参数可以不配置 set hive.execution.engine=spark; set spark.eventLog.enabled=true; set spark.eventLog.dir=hdfs://cdh5/tmp/sparkeventlog; set spark.executor.memory=1g; set spark.executor.instances=50; //executor数量,默认貌似只有2个 set spark.driver.memory=1g; set spark.serializer=org.apache.spark.serializer.KryoSerializer;
当然,这些参数也可以配置在hive-site.xml中。
接下来就可以执行HQL查询试试了:
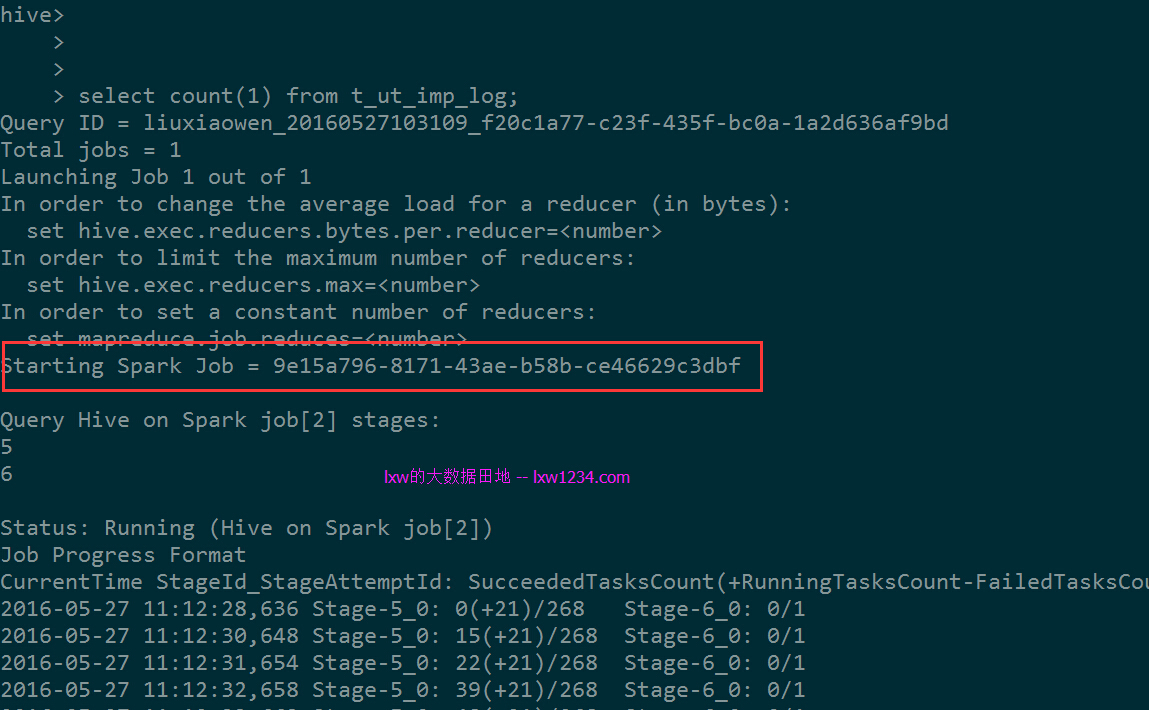
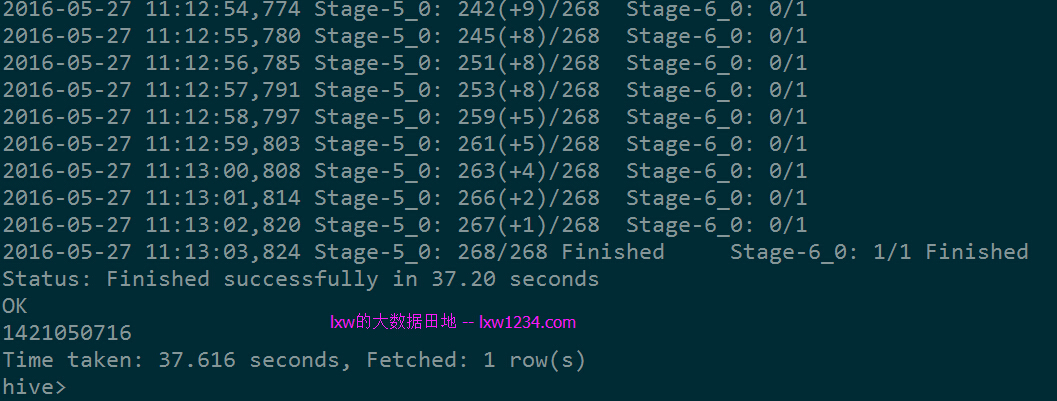
可以看到,已经使用Spark作为执行引擎了。
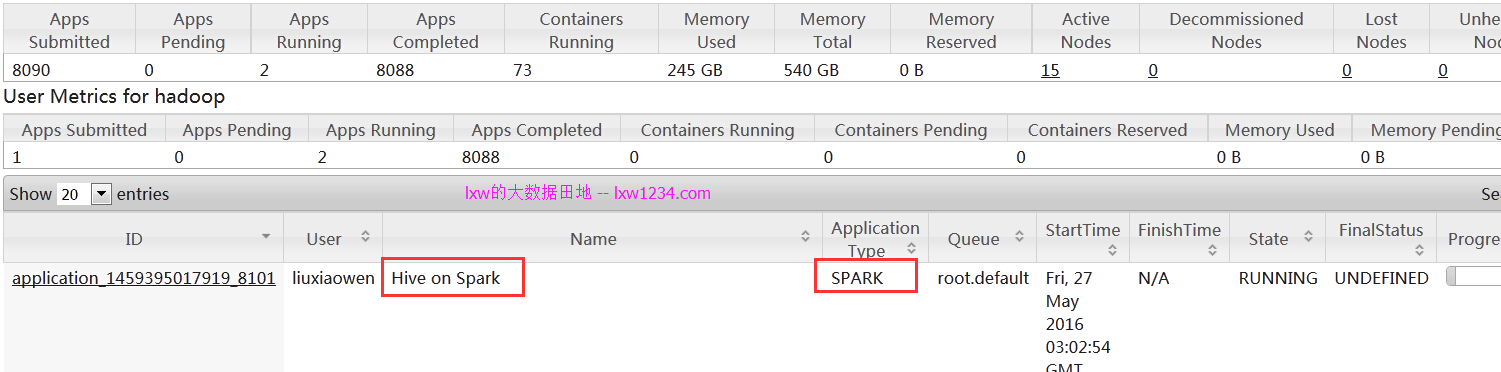
在Yarn的WEB页面上也看到了对应的Application。
在进入hive-cli命令行,第一次执行查询之后,Hive向Yarn申请Container资源,即参数spark.executor.instances指定的数量,另外加一个Driver使用的Container。该Application便会一直运行,直到退出hive-cli,该Application便会成功结束,期间占用的集群资源不会自动释放和回收。如果在hive-cli中修改和executor相关的参数,再次执行查询时候,Hive会结束上一次在Yarn上运行的Application,重新申请资源提交运行。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Hive使用Spark on Yarn作为执行引擎


