Spark2.0新增了Structured Streaming,它是基于SparkSQL构建的可扩展和容错的流式数据处理引擎,使得实时流式数据计算可以和离线计算采用相同的处理方式(DataFrame&SQL)。Structured Streaming顾名思义,它将数据源和计算结果都映射成一张”结构化”的表,在计算的时候以结构化的方式去操作数据流,大大方便和提高了数据开发的效率。
Spark2.0之前,流式计算通过Spark Streaming进行:

使用Spark Streaming每次只能消费当前批次内的数据,当然可以通过window操作,消费过去一段时间(多个批次)内的数据。举个简例子,需要每隔10秒,统计当前小时的PV和UV,在数据量特别大的情况下,使用window操作并不是很好的选择,通常是借助其它如Redis、HBase等完成数据统计。
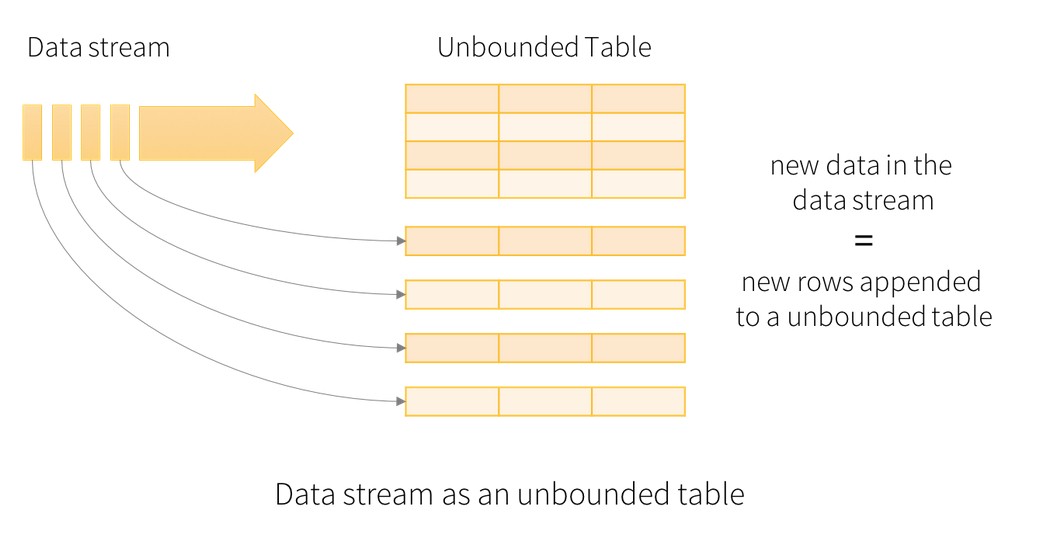
Structured Streaming将数据源和计算结果都看做是无限大的表,数据源中每个批次的数据,经过计算,都添加到结果表中作为行。
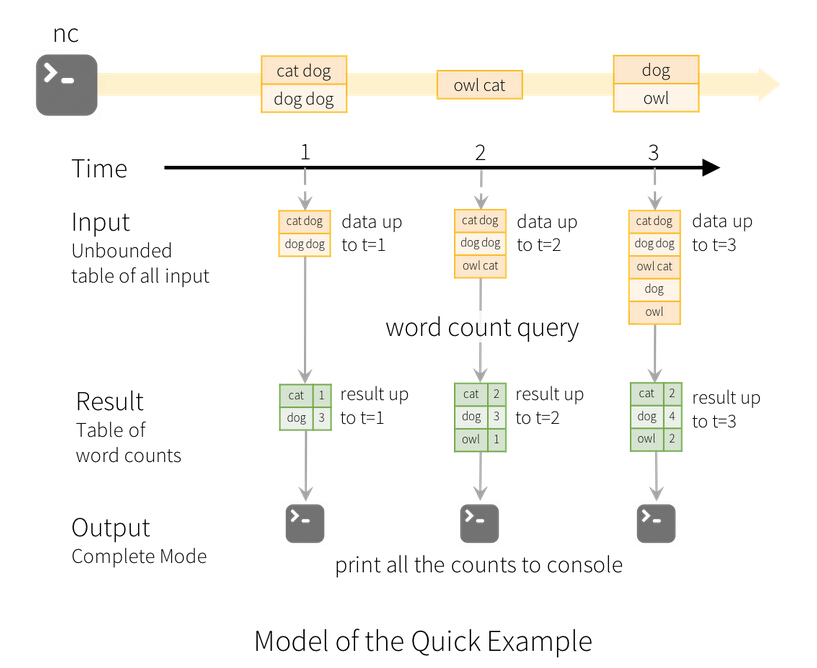
先试试官方给的例子,在本地启动NetCat: nc -lk 9999
在另一个会话中:
cd $SPARK_HOME/bin
./spark-shell(以local模式进入spark-shell命令行),运行下面的程序:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
import spark.implicits._
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream.outputMode("complete").format("console").start()
query.awaitTermination()
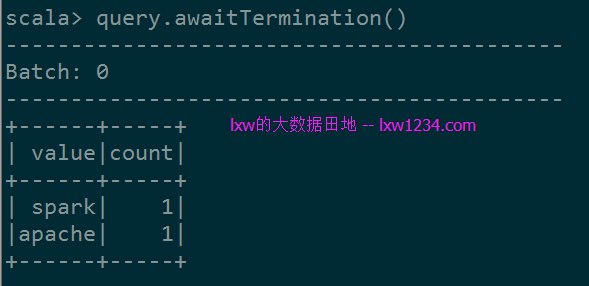
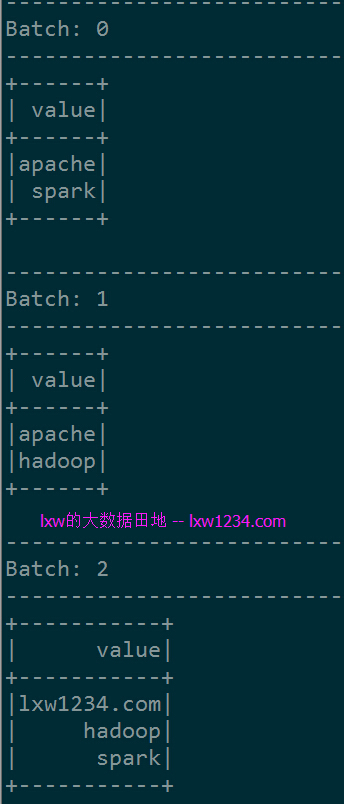
在NetCat会话中输入”apache spark”,spark-shell中显示:
在NetCat会话中分两次再输入”apache hadoop”,”lxw1234.com hadoop spark”, spark-shell中显示:
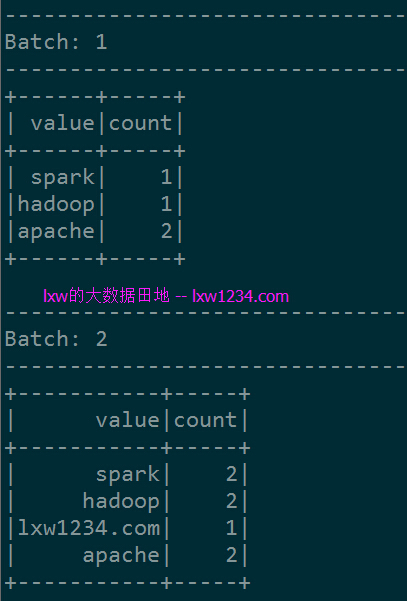
可以看到,每个Batch显示的结果,都是完整的WordCount统计结果,这便是结算结果输出中的完整模式(Complete Mode)。
关于结算结果的输出,有三种模式:
- Complete Mode:输出最新的完整的结果表数据。
- Append Mode:只输出结果表中本批次新增的数据,其实也就是本批次中的数据;
- Update Mode(暂不支持):只输出结果表中被本批次修改的数据;
这些Output,可以直接通过连接器(如MySQL JDBC、HBase API等)写入外部存储系统。
再看看Append模式,
注意:Append模式不支持基于数据流上的聚合操作(Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets);
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()
import spark.implicits._
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
val words = lines.as[String].flatMap(_.split(" "))
val query = words.writeStream.outputMode("append").format("console").start()
query.awaitTermination()
在NetCat中分三次输入:
apache spark
apache hadoop
lxw1234.com hadoop spark
spark-shell中显示:
只有当前批次的数据。
如果觉得本博客对您有帮助,请 赞助作者 。


