如果你已经按照《写给大数据开发初学者的话》中第一章和第二章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
- 0和Hadoop2.0的区别;
- MapReduce的原理(还是那个经典的题目,一个10G大小的文件,给定1G大小的内存,如何使用Java程序统计出现次数最多的10个单词及次数);
- HDFS读写数据的流程;向HDFS中PUT数据;从HDFS中下载数据;
- 自己会写简单的MapReduce程序,运行出现问题,知道在哪里查看日志;
- 会写简单的SELECT、WHERE、GROUP BY等SQL语句;
- Hive SQL转换成MapReduce的大致流程;
- Hive中常见的语句:创建表、删除表、往表中加载数据、分区、将表中数据下载到本地;
从上面的学习,你已经了解到,HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。
此时,你的”大数据平台”是这样的:
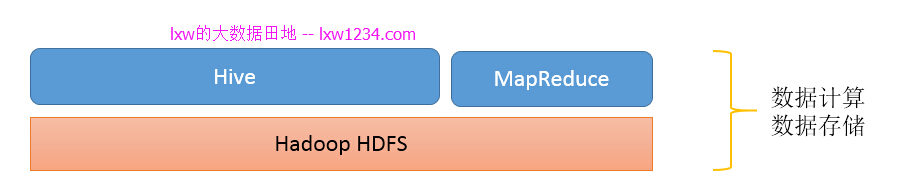
那么问题来了,海量数据如何到HDFS上呢?
第三章:把别处的数据搞到Hadoop上
此处也可以叫做数据采集,把各个数据源的数据采集到Hadoop上。
3.1 HDFS PUT命令
这个在前面你应该已经使用过了。
put命令在实际环境中也比较常用,通常配合shell、python等脚本语言来使用。
建议熟练掌握。
3.2 HDFS API
HDFS提供了写数据的API,自己用编程语言将数据写入HDFS,put命令本身也是使用API。
实际环境中一般自己较少编写程序使用API来写数据到HDFS,通常都是使用其他框架封装好的方法。比如:Hive中的INSERT语句,Spark中的saveAsTextfile等。
建议了解原理,会写Demo。
3.3 Sqoop
Sqoop是一个主要用于Hadoop/Hive与传统关系型数据库Oracle/MySQL/SQLServer等之间进行数据交换的开源框架。
就像Hive把SQL翻译成MapReduce一样,Sqoop把你指定的参数翻译成MapReduce,提交到Hadoop运行,完成Hadoop与其他数据库之间的数据交换。
自己下载和配置Sqoop(建议先使用Sqoop1,Sqoop2比较复杂)。
了解Sqoop常用的配置参数和方法。
使用Sqoop完成从MySQL同步数据到HDFS;
使用Sqoop完成从MySQL同步数据到Hive表;
PS:如果后续选型确定使用Sqoop作为数据交换工具,那么建议熟练掌握,否则,了解和会用Demo即可。
3.4 Flume
Flume是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。
Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。
因此,如果你的业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
下载和配置Flume。
使用Flume监控一个不断追加数据的文件,并将数据传输到HDFS;
PS:Flume的配置和使用较为复杂,如果你没有足够的兴趣和耐心,可以先跳过Flume。
3.5 阿里开源的DataX
之所以介绍这个,是因为我们公司目前使用的Hadoop与关系型数据库数据交换的工具,就是之前基于DataX开发的,非常好用。
可以参考我的博文《异构数据源海量数据交换工具-Taobao DataX 下载和使用》。
现在DataX已经是3.0版本,支持很多数据源。
你也可以在其之上做二次开发。
PS:有兴趣的可以研究和使用一下,对比一下它与Sqoop。
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
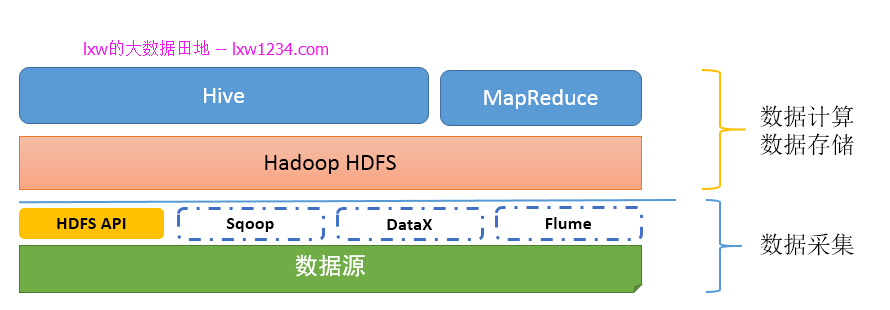

第四章:把Hadoop上的数据搞到别处去
前面介绍了如何把数据源的数据采集到Hadoop上,数据到Hadoop上之后,便可以使用Hive和MapReduce进行分析了。那么接下来的问题是,分析完的结果如何从Hadoop上同步到其他系统和应用中去呢?
其实,此处的方法和第三章基本一致的。
4.1 HDFS GET命令
把HDFS上的文件GET到本地。需要熟练掌握。
4.2 HDFS API
同3.2.
4.3 Sqoop
同3.3.
使用Sqoop完成将HDFS上的文件同步到MySQL;
使用Sqoop完成将Hive表中的数据同步到MySQL;
4.4 DataX
同3.5.
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
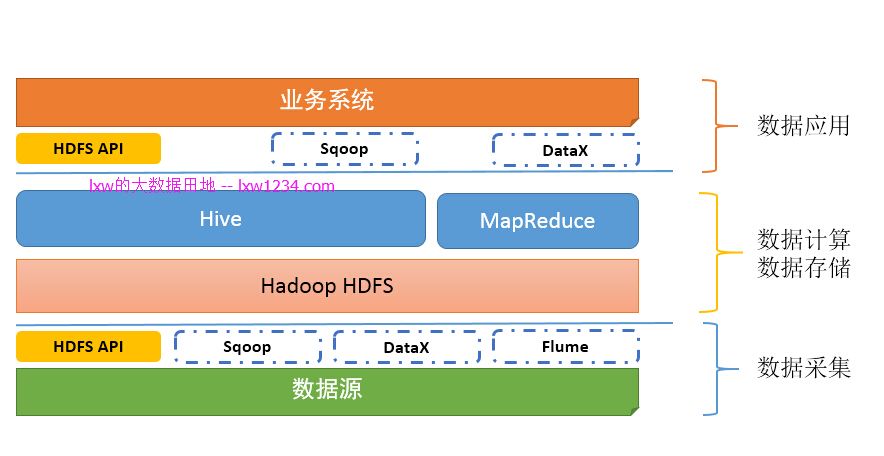
以下章节正在整理中,请持续关注 lxw的大数据田地
第五章:快一点吧,我的SQL
第六章:一夫多妻制
第七章:越来越多的分析任务
第八章:我的数据要实时
第九章:我的数据要对外
第十章:牛逼高大上的机器学习
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 写给大数据开发初学者的话2
