еҰӮжһңдҪ е·Із»ҸжҢүз…§гҖҠеҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ3гҖӢдёӯ第дә”з« е’Ң第е…ӯз« зҡ„жөҒзЁӢи®Өзңҹе®Ңж•ҙзҡ„иө°дәҶдёҖйҒҚпјҢйӮЈд№ҲдҪ еә”иҜҘе·Із»Ҹе…·еӨҮд»ҘдёӢжҠҖиғҪе’ҢзҹҘиҜҶзӮ№пјҡ
- дёәд»Җд№ҲSparkжҜ”MapReduceеҝ«гҖӮ
- дҪҝз”ЁSparkSQLд»ЈжӣҝHiveпјҢжӣҙеҝ«зҡ„иҝҗиЎҢSQLгҖӮ
- дҪҝз”ЁKafkaе®ҢжҲҗж•°жҚ®зҡ„дёҖ次收йӣҶпјҢеӨҡж¬Ўж¶Ҳиҙ№жһ¶жһ„гҖӮ
- иҮӘе·ұеҸҜд»ҘеҶҷзЁӢеәҸе®ҢжҲҗKafkaзҡ„з”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…гҖӮ
д»ҺеүҚйқўзҡ„еӯҰд№ пјҢдҪ е·Із»ҸжҺҢжҸЎдәҶеӨ§ж•°жҚ®е№іеҸ°дёӯзҡ„ж•°жҚ®йҮҮйӣҶгҖҒж•°жҚ®еӯҳеӮЁе’Ңи®Ўз®—гҖҒж•°жҚ®дәӨжҚўзӯүеӨ§йғЁеҲҶжҠҖиғҪпјҢиҖҢиҝҷе…¶дёӯзҡ„жҜҸдёҖжӯҘпјҢйғҪйңҖиҰҒдёҖдёӘд»»еҠЎпјҲзЁӢеәҸпјүжқҘе®ҢжҲҗпјҢеҗ„дёӘд»»еҠЎд№Ӣй—ҙеҸҲеӯҳеңЁдёҖе®ҡзҡ„дҫқиө–жҖ§пјҢжҜ”еҰӮпјҢеҝ…йЎ»зӯүж•°жҚ®йҮҮйӣҶд»»еҠЎжҲҗеҠҹе®ҢжҲҗеҗҺпјҢж•°жҚ®и®Ўз®—д»»еҠЎжүҚиғҪејҖе§ӢиҝҗиЎҢгҖӮеҰӮжһңдёҖдёӘд»»еҠЎжү§иЎҢеӨұиҙҘпјҢйңҖиҰҒз»ҷејҖеҸ‘иҝҗз»ҙдәәе‘ҳеҸ‘йҖҒе‘ҠиӯҰпјҢеҗҢж—¶йңҖиҰҒжҸҗдҫӣе®Ңж•ҙзҡ„ж—Ҙеҝ—жқҘж–№дҫҝжҹҘй”ҷгҖӮ
第дёғз« пјҡи¶ҠжқҘи¶ҠеӨҡзҡ„еҲҶжһҗд»»еҠЎ
дёҚд»…д»…жҳҜеҲҶжһҗд»»еҠЎпјҢж•°жҚ®йҮҮйӣҶгҖҒж•°жҚ®дәӨжҚўеҗҢж ·жҳҜдёҖдёӘдёӘзҡ„д»»еҠЎгҖӮиҝҷдәӣд»»еҠЎдёӯпјҢжңүзҡ„жҳҜе®ҡж—¶и§ҰеҸ‘пјҢжңүзӮ№еҲҷйңҖиҰҒдҫқиө–е…¶д»–д»»еҠЎжқҘи§ҰеҸ‘гҖӮеҪ“е№іеҸ°дёӯжңүеҮ зҷҫдёҠеҚғдёӘд»»еҠЎйңҖиҰҒз»ҙжҠӨе’ҢиҝҗиЎҢж—¶еҖҷпјҢд»…д»…йқ crontabиҝңиҝңдёҚеӨҹдәҶпјҢиҝҷж—¶дҫҝйңҖиҰҒдёҖдёӘи°ғеәҰзӣ‘жҺ§зі»з»ҹжқҘе®ҢжҲҗиҝҷ件дәӢгҖӮи°ғеәҰзӣ‘жҺ§зі»з»ҹжҳҜж•ҙдёӘж•°жҚ®е№іеҸ°зҡ„дёӯжһўзі»з»ҹпјҢзұ»дјјдәҺAppMasterпјҢиҙҹиҙЈеҲҶй…Қе’Ңзӣ‘жҺ§д»»еҠЎгҖӮ
7.1 Apache Oozie
1.В В В OozieжҳҜд»Җд№Ҳпјҹжңүе“ӘдәӣеҠҹиғҪпјҹ
2.В В В OozieеҸҜд»Ҙи°ғеәҰе“Әдәӣзұ»еһӢзҡ„д»»еҠЎпјҲзЁӢеәҸпјүпјҹ
3.В В В OozieеҸҜд»Ҙж”ҜжҢҒе“Әдәӣд»»еҠЎи§ҰеҸ‘ж–№ејҸпјҹ
4.В В В е®үиЈ…й…ҚзҪ®OozieгҖӮ
7.2 е…¶д»–ејҖжәҗзҡ„д»»еҠЎи°ғеәҰзі»з»ҹ
Azkabanпјҡ
https://azkaban.github.io/
light-task-schedulerпјҡ
https://github.com/ltsopensource/light-task-scheduler
Zeusпјҡ
https://github.com/alibaba/zeus
зӯүзӯүвҖҰвҖҰ
еҸҰеӨ–пјҢжҲ‘иҝҷиҫ№жҳҜд№ӢеүҚеҚ•зӢ¬ејҖеҸ‘зҡ„д»»еҠЎи°ғеәҰдёҺзӣ‘жҺ§зі»з»ҹпјҢе…·дҪ“иҜ·еҸӮиҖғгҖҠеӨ§ж•°жҚ®е№іеҸ°д»»еҠЎи°ғеәҰдёҺзӣ‘жҺ§зі»з»ҹгҖӢ.
еҰӮжһңдҪ и®Өзңҹе®ҢжҲҗдәҶдёҠйқўзҡ„еӯҰд№ е’Ңе®һи·өпјҢжӯӨж—¶пјҢдҪ зҡ„вҖқеӨ§ж•°жҚ®е№іеҸ°вҖқеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
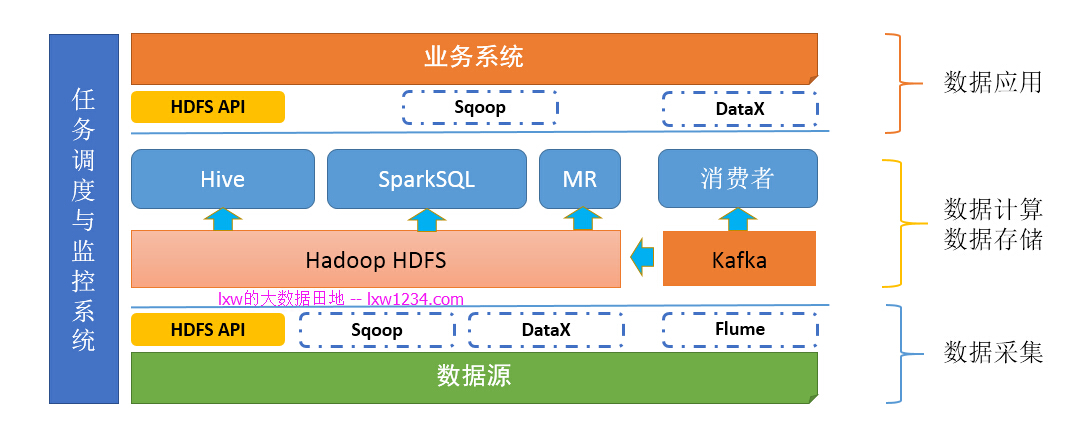
з¬¬е…«з« пјҡжҲ‘зҡ„ж•°жҚ®иҰҒе®һж—¶
еңЁз¬¬е…ӯз« д»Ӣз»ҚKafkaзҡ„ж—¶еҖҷжҸҗеҲ°дәҶдёҖдәӣйңҖиҰҒе®һж—¶жҢҮж Үзҡ„дёҡеҠЎеңәжҷҜпјҢе®һж—¶еҹәжң¬еҸҜд»ҘеҲҶдёәз»қеҜ№е®һж—¶е’ҢеҮҶе®һж—¶пјҢз»қеҜ№е®һж—¶зҡ„延иҝҹиҰҒжұӮдёҖиҲ¬еңЁжҜ«з§’зә§пјҢеҮҶе®һж—¶зҡ„延иҝҹиҰҒжұӮдёҖиҲ¬еңЁз§’гҖҒеҲҶй’ҹзә§гҖӮеҜ№дәҺйңҖиҰҒз»қеҜ№е®һж—¶зҡ„дёҡеҠЎеңәжҷҜпјҢз”Ёзҡ„жҜ”иҫғеӨҡзҡ„жҳҜStormпјҢеҜ№дәҺе…¶д»–еҮҶе®һж—¶зҡ„дёҡеҠЎеңәжҷҜпјҢеҸҜд»ҘжҳҜStormпјҢд№ҹеҸҜд»ҘжҳҜSpark StreamingгҖӮеҪ“然пјҢеҰӮжһңеҸҜд»Ҙзҡ„иҜқпјҢд№ҹеҸҜд»ҘиҮӘе·ұеҶҷзЁӢеәҸжқҘеҒҡгҖӮ
8.1 Storm
1.В В В д»Җд№ҲжҳҜStormпјҹжңүе“ӘдәӣеҸҜиғҪзҡ„еә”з”ЁеңәжҷҜпјҹ
2.В В В Stormз”ұе“Әдәӣж ёеҝғ组件жһ„жҲҗпјҢеҗ„иҮӘжӢ…д»»д»Җд№Ҳи§’иүІпјҹ
3.В В В Stormзҡ„з®ҖеҚ•е®үиЈ…е’ҢйғЁзҪІгҖӮ
4.В В В иҮӘе·ұзј–еҶҷDemoзЁӢеәҸпјҢдҪҝз”ЁStormе®ҢжҲҗе®һж—¶ж•°жҚ®жөҒи®Ўз®—гҖӮ
8.2 Spark Streaming
1.В В В д»Җд№ҲжҳҜSpark StreamingпјҢе®ғе’ҢSparkжҳҜд»Җд№Ҳе…ізі»пјҹ
2.В В В Spark Streamingе’ҢStormжҜ”иҫғпјҢеҗ„жңүд»Җд№ҲдјҳзјәзӮ№пјҹ
3.В В В дҪҝз”ЁKafka + Spark StreamingпјҢе®ҢжҲҗе®һж—¶и®Ўз®—зҡ„DemoзЁӢеәҸгҖӮ
еҰӮжһңдҪ и®Өзңҹе®ҢжҲҗдәҶдёҠйқўзҡ„еӯҰд№ е’Ңе®һи·өпјҢжӯӨж—¶пјҢдҪ зҡ„вҖқеӨ§ж•°жҚ®е№іеҸ°вҖқеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ

д»ҘдёӢз« иҠӮжӯЈеңЁж•ҙзҗҶдёӯпјҢиҜ·жҢҒз»ӯе…іжіЁ lxwзҡ„еӨ§ж•°жҚ®з”°ең°
第д№қз« пјҡжҲ‘зҡ„ж•°жҚ®иҰҒеҜ№еӨ–
第еҚҒз« пјҡзүӣйҖјй«ҳеӨ§дёҠзҡ„жңәеҷЁеӯҰд№
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ4
