еҰӮжһңдҪҝз”ЁSparkThrfitServerз»“еҗҲHiveжқҘеҒҡеҚіеёӯжҹҘиҜўпјҢйӮЈд№ҲдјҡйҒҮеҲ°иҝҷж ·зҡ„й—®йўҳпјҢдёҖдёӘж•°жҚ®йҮҸеҫҲеӨ§зҡ„жҹҘиҜўSQLжҠҠжүҖжңүзҡ„иө„жәҗе…ЁеҚ дәҶпјҢеҜјиҮҙеҗҺйқўзҡ„SQLйғҪзӯүеҫ…пјҢе°Ҫз®ЎеңЁзӯүеҫ…зҡ„SQLеҸӘйңҖиҰҒ1з§’е°ұиғҪе®ҢжҲҗпјҢиҝҷз§Қжғ…еҶөиӮҜе®ҡжҳҜдҪ дёҚжғізңӢеҲ°зҡ„гҖӮ
Sparkй»ҳи®Өзҡ„и°ғеәҰзӯ–з•ҘдёәFIFOпјҢеҚіе…Ҳиҝӣе…ҲеҮәпјҢеҸӘиҰҒжҳҜжҲ‘е…ҲжқҘпјҢйӮЈд№Ҳеҝ…йЎ»зӯүжҲ‘жү§иЎҢе®ҢеҗҺпјҢдҪ жүҚиғҪжү§иЎҢгҖӮеҰӮдёӢеӣҫпјҢеүҚйқўжҸҗдәӨдәҶдёҖдёӘйңҖиҰҒеҮ еҚғдёӘиө„жәҗзҡ„д»»еҠЎеңЁжү§иЎҢпјҢеҗҺйқўжҸҗдәӨзҡ„еҸӘйңҖиҰҒ22дёӘиө„жәҗзҡ„д»»еҠЎе°ұеҫ—дёҖзӣҙзӯүгҖӮ

еҰӮжһңдҪ и§ЈеҶіиҝҮHadoopзҡ„еӨҡз”ЁжҲ·иө„жәҗеҲҶй…Қй—®йўҳпјҢйӮЈд№ҲиӮҜе®ҡеҜ№FAIRпјҲе…¬е№іи°ғеәҰеҷЁпјүдёҚйҷҢз”ҹпјҢSparkдёәдәҶи§ЈеҶіеӨҡз”ЁжҲ·зҡ„иҝҷз§Қй—®йўҳпјҢд№ҹжҸҗдҫӣдәҶFAIRзҡ„и°ғеәҰзӯ–з•ҘгҖӮ
жң¬ж–Үд»Ӣз»ҚеҰӮдҪ•еңЁSparkThriftServer&Beeline&JDBCдёӯй…ҚзҪ®е’ҢдҪҝз”ЁиҜҘзӯ–з•ҘгҖӮ
еҰӮжһңдҪ зҹҘйҒ“FAIRпјҢйӮЈд№ҲиӮҜе®ҡеҜ№fairscheduler.xml й…ҚзҪ®ж–Ү件дёҚйҷҢз”ҹгҖӮ
cd $SPARK_HOME/conf
cp fairscheduler.xml.template fairscheduler.xml
vi fairscheduler.xml
<allocations> В <pool name="pool1"> В В В <schedulingMode>FAIR</schedulingMode> В В В <weight>5</weight> В В В <minShare>3</minShare> В </pool> </allocations>
еңЁfairscheduler.xml дёӯпјҢй…ҚзҪ®ж·»еҠ дәҶдёҖдёӘиө„жәҗжұ pool1пјҢе…¶дёӯпјҢ
schedulingMode жҢҮе®ҡдёәFAIRпјӣ
weight зӣёеҪ“дәҺиө„жәҗжұ жқғйҮҚпјҢй»ҳи®Өдёә1пјҢиҝҷйҮҢжҢҮе®ҡдәҶ5пјҢиЎЁзӨәиҝҷдёӘиө„жәҗжұ еҸҜд»ҘжҜ”й»ҳи®Өиө„жәҗжұ еӨҡиҺ·еҫ—5еҖҚзҡ„иө„жәҗпјӣ
minShare з»ҷжҜҸдёӘи°ғеәҰжұ жҢҮе®ҡдёҖдёӘжңҖе°Ҹзҡ„sharesеҖјпјҲд№ҹе°ұжҳҜCPUзҡ„ж ёж•°зӣ®пјүгҖӮе…¬е№іи°ғеәҰеҷЁйҖҡиҝҮжқғйҮҚйҮҚж–°еҲҶй…Қиө„жәҗд№ӢеүҚжҖ»жҳҜиҜ•еӣҫж»Ўи¶іжүҖжңүжҙ»еҠЁи°ғеәҰжұ зҡ„жңҖе°ҸshareгҖӮеңЁжІЎжңүз»ҷе®ҡдёҖдёӘй«ҳдјҳе…Ҳзә§зҡ„е…¶д»–йӣҶзҫӨдёӯпјҢminShareеұһжҖ§жҳҜеҸҰеӨ–зҡ„дёҖз§Қж–№ејҸжқҘзЎ®дҝқи°ғеәҰжұ иғҪеӨҹиҝ…йҖҹзҡ„иҺ·еҫ—дёҖе®ҡж•°йҮҸзҡ„иө„жәҗпјҲдҫӢеҰӮ10ж ёCPUпјүпјҢй»ҳи®Өжғ…еҶөдёӢпјҢжҜҸдёӘи°ғеәҰжұ зҡ„minShareеҖјйғҪдёә0
й…ҚзҪ®дәҶиө„жәҗжұ пјҢиҝҳйңҖиҰҒеңЁspark-defaults.conf дёӯжҢҮе®ҡдёӢйқўдёӨдёӘеҸӮж•°пјҡ
spark.scheduler.mode FAIR
spark.scheduler.allocation.file /opt/spark/current/conf/fairscheduler.xml
й…ҚзҪ®еҘҪдәҶпјҢеҗҜеҠЁSparkThriftServerпјҲOn Yarnпјүпјҡ
cd $SPARK_HOME/sbin ./start-thriftserver.sh --master yarn --conf spark.driver.memory=3G --executor-memory 1G --num-executors 10 --hiveconf hive.server2.thrift.port=10003
еҗҜеҠЁеҗҺпјҢдјҡеңЁWEBз•ҢйқўзңӢеҲ°иө„жәҗжұ й…ҚзҪ®пјҡ
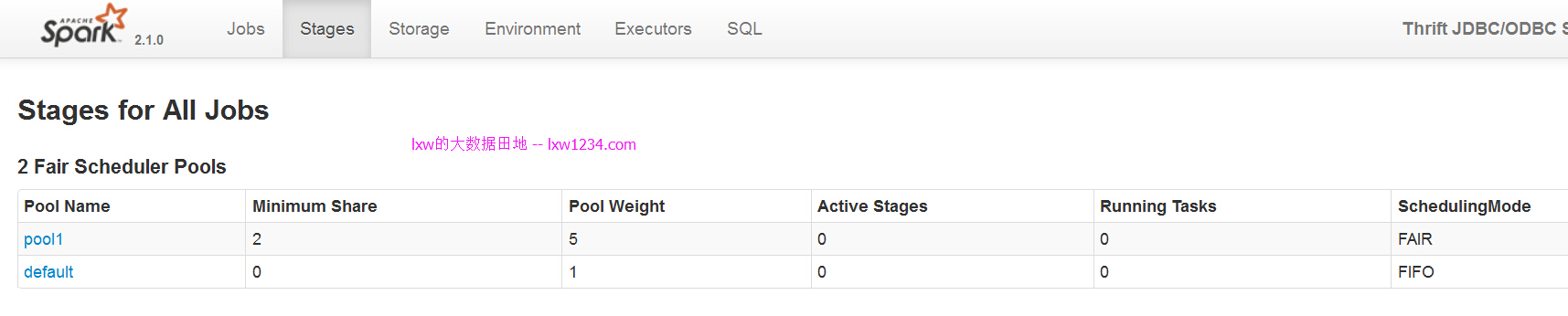
дҪҝз”Ёbeelineй“ҫжҺҘпјҢе…ҲжҸҗдәӨйӮЈдёӘеӨ§зҡ„SQLпјҡ
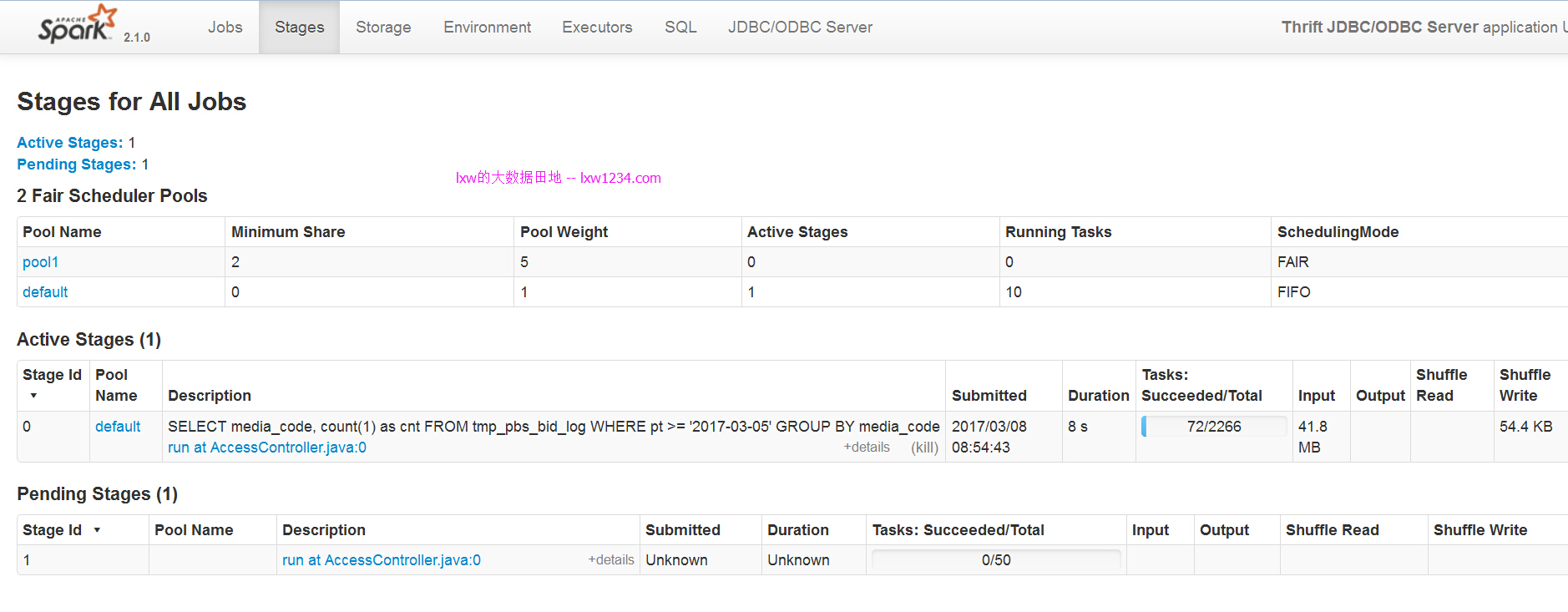
еҸҜд»ҘзңӢеҲ°пјҢиҜҘд»»еҠЎиў«жҸҗдәӨеҲ°й»ҳи®Өиө„жәҗжұ пјҲdefaultпјүдёӯгҖӮ
еҸҰеӨ–еҗҜеҠЁдёҖдёӘbeelineпјҢиҝһжҺҘеҗҺпјҢе…ҲжҢҮе®ҡиө„жәҗжұ pool1пјҡ
SET spark.sql.thriftserver.scheduler.pool=pool1;
然еҗҺпјҢеҶҚжҸҗдәӨе°Ҹзҡ„SQLгҖӮ
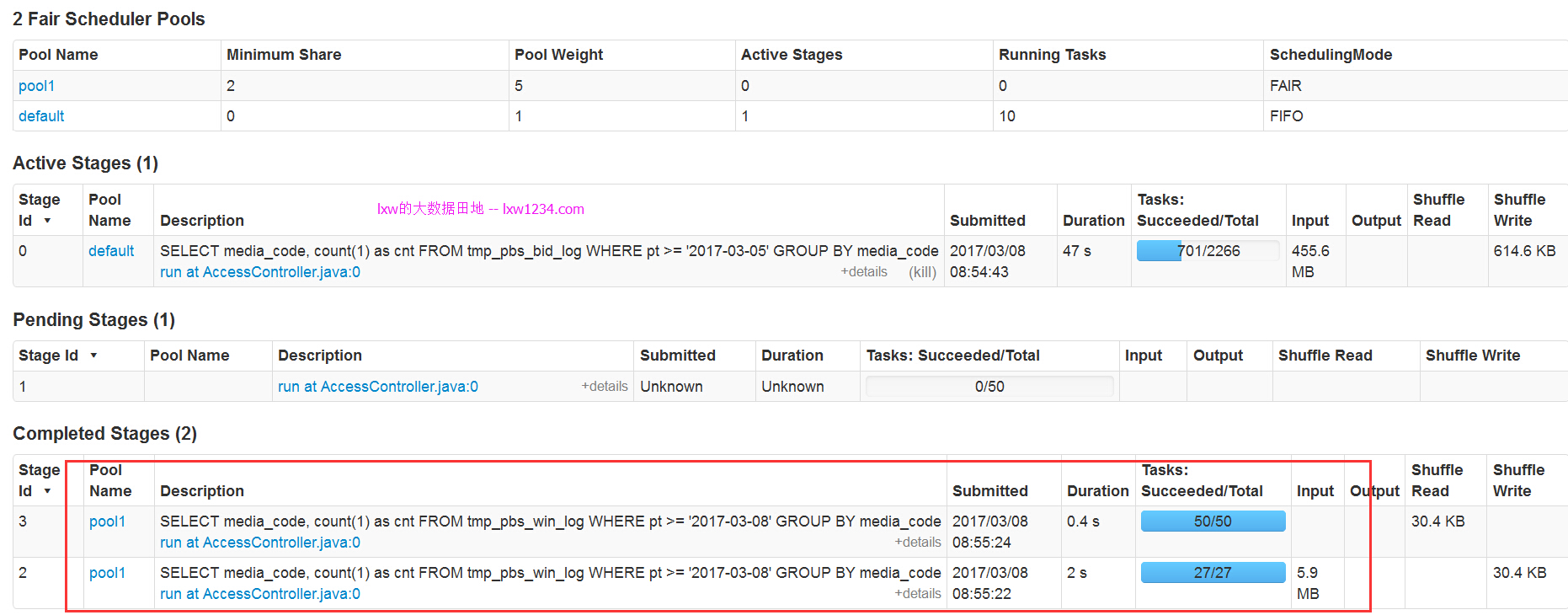
еҸҜд»ҘзңӢеҲ°пјҢе°Ҹзҡ„SQLиў«жҸҗдәӨеҲ°pool1дёӯпјҢеӣ дёәpool1зҡ„дјҳе…Ҳзә§й«ҳпјҢеӣ жӯӨе®ғиғҪдјҳе…Ҳиў«жү§иЎҢгҖӮ
JDBCдёӯеҗҢж ·еҸҜд»Ҙе…ҲжҢҮе®ҡиө„жәҗжұ пјҢеҶҚжү§иЎҢSQLпјҡ
Statement stmt = con.createStatement();
stmt.execute("SET spark.sql.thriftserver.scheduler.pool=pool1");
String sql = "select count(1) from xxx";
ResultSet res = stmt.executeQuery(sql);
еҪ“然пјҢдҪ еҸҜд»ҘеңЁfairscheduler.xml дёӯеӨҡй…ҚзҪ®еҮ дёӘиө„жәҗжұ пјҢи®ҫзҪ®дёҚеҗҢзҡ„дјҳе…Ҳзә§пјҢдҫӣз”ЁжҲ·дҪҝз”ЁгҖӮ
дҪҶжҳҜпјҢSparkзҡ„е…¬е№іи°ғеәҰеҷЁиө„жәҗжұ пјҢдҪҝз”Ёж—¶еҖҷеҸӘиғҪжҳҫзӨәзҡ„жҢҮе®ҡпјҢж— жі•еғҸHadoopйӮЈж ·пјҢж №жҚ®з”ЁжҲ·гҖҒз”ЁжҲ·з»„жқҘиҮӘеҠЁйҖүжӢ©иө„жәҗжұ пјҢеҪ“然пјҢдҪ еҸҜд»Ҙдҝ®ж”№жәҗз ҒпјҢжҜ”еҰӮпјҡж №жҚ®йңҖиҰҒзҡ„executorж•°йҮҸпјҢе°‘зҡ„пјҢе°ұи®©е®ғеҲ°дјҳе…Ҳзә§й«ҳзҡ„иө„жәҗжұ еҫҲеҝ«жү§иЎҢе®ҢпјҢеӨҡзҡ„пјҢе°ұи®©е®ғеҲ°дјҳе…Ҳзә§дҪҺзҡ„иө„жәҗжұ ж…ўж…ўжү§иЎҢгҖӮ
д»ҘдёҠпјҢеёҢжңӣеҜ№еӨ§е®¶еңЁе®һйҷ…дҪҝз”ЁдёӯжңүжүҖеё®еҠ©гҖӮ
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » SparkThrfitServerеӨҡз”ЁжҲ·иө„жәҗз«һдәүдёҺеҲҶй…Қй—®йўҳ


