关键字:Hive Orc、Java API 读取Hive OrcFile
Orc是Hive特有的一种列式存储的文件格式,它有着非常高的压缩比和读取效率,因此很快取代了之前的RCFile,成为Hive中非常常用的一种文件格式。
在实际业务场景中,可能需要使用Java API,或者MapReduce读写Orc文件。
本文先介绍使用Java API读取Hive Orc文件。
在Hive中已有一张Orc格式存储的表lxw1234:
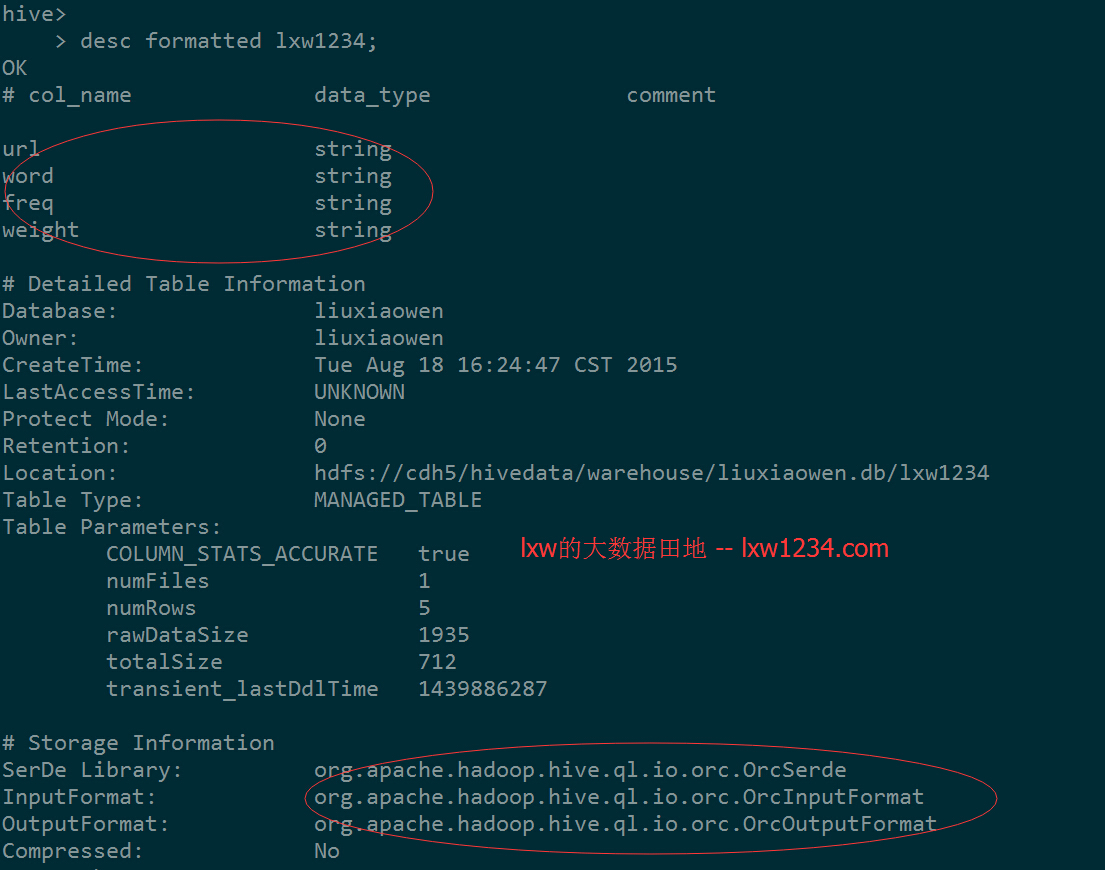
该表有四个字段:url、word、freq、weight,类型均为string;
数据只有5条:
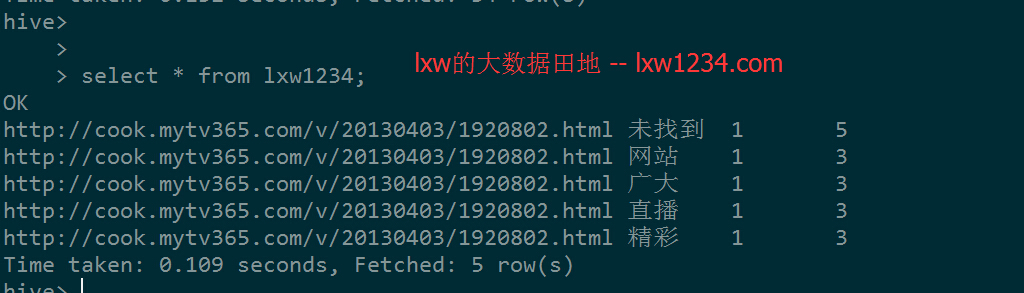
下面的代码,从表lxw1234对应的HDFS路径中使用API直接读取Orc文件:
package com.lxw1234.test;
import java.util.List;
import java.util.Properties;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.io.orc.OrcInputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcSerde;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.InputFormat;
import org.apache.hadoop.mapred.InputSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.Reporter;
/**
* lxw的大数据田地 -- http://lxw1234.com
* @author lxw.com
*
*/
public class TestOrcReader {
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf();
Path testFilePath = new Path(args[0]);
Properties p = new Properties();
OrcSerde serde = new OrcSerde();
p.setProperty("columns", "url,word,freq,weight");
p.setProperty("columns.types", "string:string:string:string");
serde.initialize(conf, p);
StructObjectInspector inspector = (StructObjectInspector) serde.getObjectInspector();
InputFormat in = new OrcInputFormat();
FileInputFormat.setInputPaths(conf, testFilePath.toString());
InputSplit[] splits = in.getSplits(conf, 1);
System.out.println("splits.length==" + splits.length);
conf.set("hive.io.file.readcolumn.ids", "1");
RecordReader reader = in.getRecordReader(splits[0], conf, Reporter.NULL);
Object key = reader.createKey();
Object value = reader.createValue();
List<? extends StructField> fields = inspector.getAllStructFieldRefs();
long offset = reader.getPos();
while(reader.next(key, value)) {
Object url = inspector.getStructFieldData(value, fields.get(0));
Object word = inspector.getStructFieldData(value, fields.get(1));
Object freq = inspector.getStructFieldData(value, fields.get(2));
Object weight = inspector.getStructFieldData(value, fields.get(3));
offset = reader.getPos();
System.out.println(url + "|" + word + "|" + freq + "|" + weight);
}
reader.close();
}
}
将上面的代码打包成orc.jar;
在Hadoop客户端机器上运行命令:
export HADOOP_CLASSPATH=/usr/local/apache-hive-0.13.1-bin/lib/hive-exec-0.13.1.jar:$HADOOP_CLASSPATH
hadoop jar orc.jar com.lxw1234.test.TestOrcReader /hivedata/warehouse/liuxiaowen.db/lxw1234/
运行结果如下:
[liuxiaowen@dev tmp]$ hadoop jar orc.jar com.lxw1234.test.TestOrcReader /hivedata/warehouse/liuxiaowen.db/lxw1234/
15/08/18 17:03:37 INFO log.PerfLogger:
15/08/18 17:03:38 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
15/08/18 17:03:38 INFO orc.OrcInputFormat: FooterCacheHitRatio: 0/1
15/08/18 17:03:38 INFO log.PerfLogger:
splits.length==1
15/08/18 17:03:38 INFO orc.ReaderImpl: Reading ORC rows from hdfs://cdh5/hivedata/warehouse/liuxiaowen.db/lxw1234/000000_0 with {include: null, offset: 0, length: 712}
http://cook.mytv365.com/v/20130403/1920802.html|未找到|1|5
http://cook.mytv365.com/v/20130403/1920802.html|网站|1|3
http://cook.mytv365.com/v/20130403/1920802.html|广大|1|3
http://cook.mytv365.com/v/20130403/1920802.html|直播|1|3
http://cook.mytv365.com/v/20130403/1920802.html|精彩|1|3
结果没有问题。
注意:该程序只做可行性测试,如果Orc数据量太大,则需要改进,或者使用MapReduce;
后续将介绍Java API写Orc文件,以及使用MapReduce读写Hive Orc文件。
请关注我的博客。或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Java API 读取Hive Orc文件


