关键字:Hive存储过程、PL/HQL、HQL/SQL、MySQL
通过PL/HQL可以在一个脚本中同时访问多个数据库系统。在实际业务场景中,经常会有需要将Hive和RDBMS中的数据结合分析,比如:
- 往RDBMS中写入Hive分析的审计信息;
- 从RDBMS中获取一些维表的数据,和Hive表进行关联;
- 从RDBMS中读取一些配置数据;
- 往RDBMS中保存Hive的分析结果;
在PL/HQL中提供了这个功能,它允许在一个PL/HQL脚本中访问多个数据库系统。下面以一个简单需求为例:
在PL/HQL脚本中执行Hive分析任务,并将本次执行的审计信息记录到MySQL,其中,审计信息包括Hive分析任务的开始时间,结束时间和最终完成状态。
MySQL中建立审计信息表
CREATE TABLE hive_task_log ( seq INT PRIMARY KEY auto_increment, start_time VARCHAR(20), end_time VARCHAR(20), return_code INT );
配置hplsql-site.xml
在hplsql-site.xml中的主要配置如下:
<property>
<name>hplsql.conn.default</name>
<value>hive2conn</value>
<description>The default connection profile</description>
</property>
<property>
<name>hplsql.conn.hive2conn</name>
<value>org.apache.hive.jdbc.HiveDriver;jdbc:hive2://172.16.212.17:10000/liuxiaowen;liuxiaowen;</value>
<description>HiveServer2 JDBC connection</description>
</property>
<property>
<name>hplsql.conn.mysql.conn</name>
<value>com.mysql.jdbc.Driver;jdbc:mysql://172.16.212.102:3306/test;test;test1234</value>
<description>MySQL connection</description>
</property>
其中,
参数hplsql.conn.default表示默认的连接器为hive2conn;
参数hplsql.conn.hive2conn表示hive2conn的具体链接串;
参数hplsql.conn.mysql.conn表示mysql的具体链接串。
特别注意:原始的hplsql-site.xml给出的是hplsql.conn.mysqlconn,经过测试有bug,这里的链接名称中必须包含”mysql.”,才会被正确解析成MYSQL的链接类型,否则,全被解析成HIVE,其他非Hive的数据库链接名称也是如此。
开发PL/HQL脚本
PL/HQL脚本1.sql中的内容如下:
MAP OBJECT log TO test.hive_task_log AT mysql.conn;
DECLARE
start_time VARCHAR(20);
end_time VARCHAR(20);
return_code INT;
BEGIN
start_time = SYSDATE || '';
SELECT COUNT(1) FROM liuxiaowen.lxw1234;
return_code = SQLCODE;
end_time = SYSDATE || '';
INSERT INTO log (`start_time`,`end_time`,`return_code`)
VALUES(start_time,end_time,return_code);
EXCEPTION WHEN OTHERS THEN
return_code = SQLCODE;
end_time = SYSDATE || '';
INSERT INTO log (`start_time`,`end_time`,`return_code`)
VALUES(start_time,end_time,return_code);
DBMS_OUTPUT.PUT_LINE('SQL execute error,return code : ' || return_code);
END
其中:
MAP OBJECT log TO test.hive_task_log AT mysql.conn;
这句是使用mysql.conn链接器,将test.hive_task_log表映射到log对象上,后面直接使用log即可。
SELECT COUNT(1) FROM liuxiaowen.lxw1234;
这句是执行Hive的分析任务。
return_code = SQLCODE;
这句是获取Hive分析任务的结果状态码,0表示正常,非0表示错误;
另外,在Hive分析任务开始前和结束后,使用SYSDATE获取当前时间。
使用PL/HQL的异常处理,当执行有问题时候,同样需要往审计表中记录开始和结束时间,以及返回的错误码。
执行PL/HQL并查看结果
在命令行执行hplsql -f 1.sql
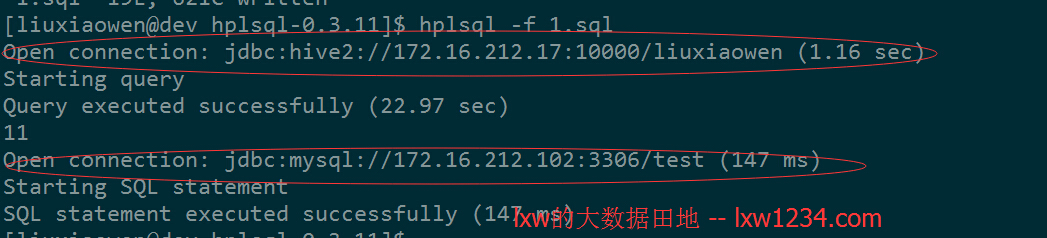
从执行的打印信息中可以看出,本次执行有两个数据库链接,第一个是链接到Hive,第二个是链接到MySQL。
在MySQL中查看表test.hive_task_log的数据:
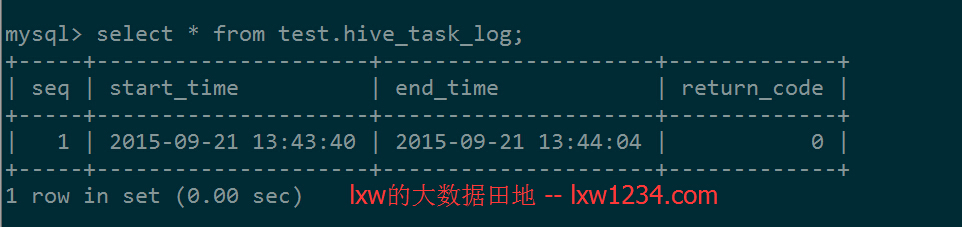
修改1.sql文件,使Hive的分析任务出错:
SELECT COUNT(1) FROM liuxiaowen.lxw1234.com;
再执行一遍:
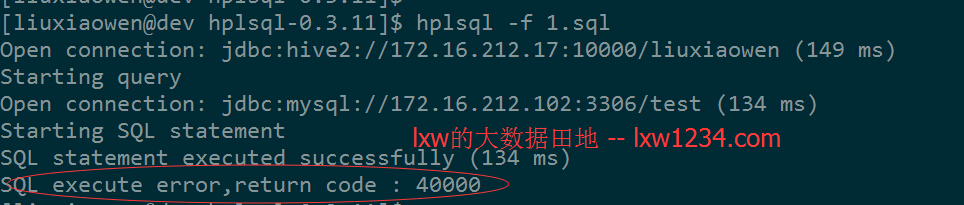
已经报错了,查看MySQL中的审计信息:

遗憾的是,目前还不支持直接将Hive中的表和MySQL中的表关联起来查询,只能通过类似游标的方式去实现关联。
更多关于Hive中使用存储过程的文章,阅读《Hive存储过程系列文章》。
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。

