关键字:海量数据去重、BloomFilter
今天尝试了使用Bloom filter对大量数据的去重计数,记录一下。
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
关于BloomFilter的原理,请参考文章最后的相关阅读或者自行搜索。这里引入一个简单的例子说明一下:
- 初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0:

- 当来了一个元素 a,进行判断,使用两个哈希函数,计算出该元素对应的Hash值为1和5,然后到Bloom Filter中判断第1位和第5位的值,上面全部为0,因此a不在Bloom Filter内,将 a 添加进去:
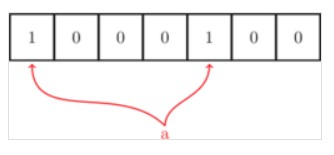
- 添加a之后,BloomFilter的第1位和第5位的值为1,之后的元素,要判断是不是在Bloom Filter内,也是同a一样的方法,只有对元素哈希后对应位置上都是 1 才认为这个元素在集合内(虽然这样可能会误判):
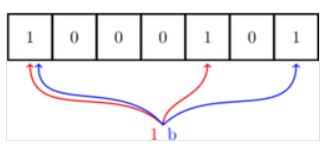
- 随着元素的插入,Bloom filter 中修改的值变多,出现误判的几率也随之变大,当新来一个元素时,满足其在Bloom Filter内的条件,即所有对应位都是 1 ,这样就可能有两种情况,一是这个元素就在集合内,没有发生误判;还有一种情况就是发生误判,出现了哈希碰撞,这个元素本不在集合内。
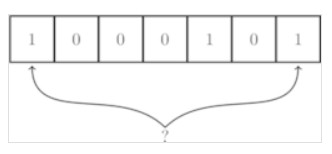
使用BloomFilter,有三个重要的值,错误率(false positive rate)、哈希函数个数以及BloomFilter位数组的大小,关于这三个值的最优配置算法,相关阅读中的文章有详细的说明。有一个原则,(BloomFilter位数组大小)/(实际的元素个数)越大,错误率越低,但消耗的空间会越多。
在网上搜了一个Java版本的Bloom Filter(https://github.com/magnuss/java-bloomfilter),做了下测试:
package com.lxw1234.bloomfilter;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Date;
public class TestBloomFilter {
public static void main(String[] args) {
File file = new File(args[0]);
//错误率
double falsePositiveProbability = 0.000001;
//预估的元素个数
int expectedNumberOfElements = 200000000;
long uv = 0l;
long pv = 0l;
Runtime rt = Runtime.getRuntime();
long start = System.currentTimeMillis();
System.out.println("start at [" + new Date() + "] ..");
MyBloomFilter bloomFilter = new MyBloomFilter(falsePositiveProbability, expectedNumberOfElements);
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
while ((tempString = reader.readLine()) != null) {
if(!bloomFilter.contains(tempString)) {
bloomFilter.add(tempString);
uv++;
}
pv++;
if(pv % 100000 == 0) {
System.out.println("pv:[" + pv + "] uv:[" + uv + "] max:[" + rt.maxMemory() + "] free:[" + rt.freeMemory() + "] ..");
}
}
reader.close();
System.out.println("Total pv:[" + pv + "] Total uv:[" + uv + "] ..");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {}
}
}
long end = System.currentTimeMillis();
System.out.println("end at [" + new Date() + "] ..");
System.out.println("Total cost [" + (end - start) + "] ms ..");
System.out.println("count:[" + bloomFilter.count() + "] ..");
System.out.println("size:[" + bloomFilter.size() + "] ..");
}
}
第一次测试使用一个较小的数据集:
总记录数:11014003 去重记录数:2590210 总大小:约250M
运行结果如下:
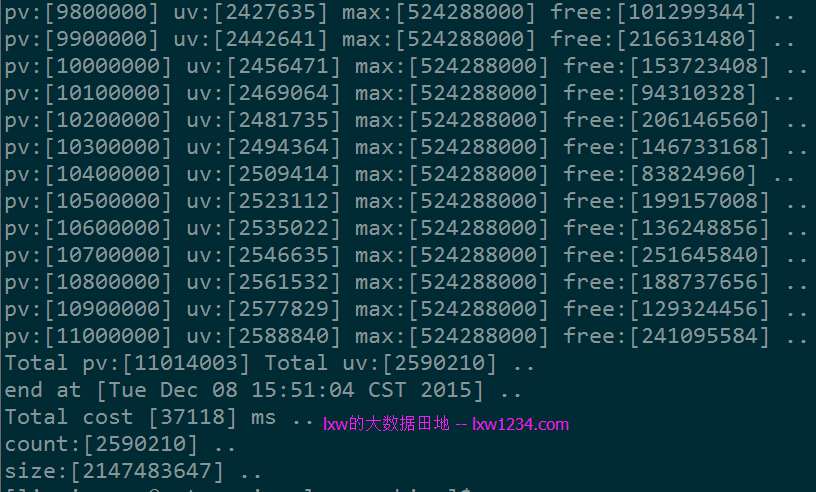
上面使用Java版本的BloomFilter中,使用了BitSet,根据配置的错误率及元素个数,将BitSet初始化成最大位数(即Integer.MAX_VALUE)2147483647,那么此时(BloomFilter位数组大小)/(实际的元素个数) = 2147483647/2590210 = 829,统计结果和实际去重记录完全一致,没有误判。
第二次测试使用一个较大的数据集:
总记录数:209310285 去重记录数:103274131 总大小:约4.5G
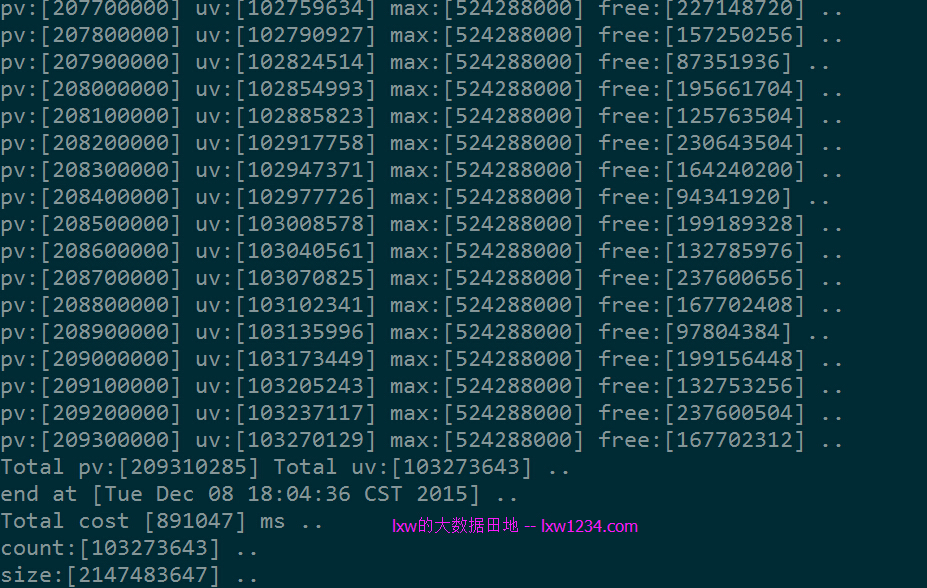
此时(BloomFilter位数组大小)/(实际的元素个数) = 2147483647/103274131 = 21,该比值大大降低,因此出现了误判。
另外,也使用streamlib跑了一下:

当然这个测试只是大概跑了一下,对于BloomFilter还有一些可优化的余地。
较之前使用的streamlib基数估计法对大数据量去重计数,这种方法准确率更高,但消耗的内存太大,而且受Hash函数个数影响,性能也差一些。
但这种方式在特定场景下特别有效,比如用来判断一个KEY是否存在,因而减少数据库或缓存的空查询次数等等。
相关阅读:
http://lxw1234.com/archives/2015/09/516.htm
http://blog.csdn.net/jiaomeng/article/details/1495500
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 大数据去重统计之BloomFilter


