ElasticSearch是一个开源搜索服务框架,它已经成为搜索解决方案领域的重要成员。ElasticSearch还经常被用作文档数据库,这主要得益于它的分布式特性和实时搜索能力,另外,ElasticSearch支持越来越多的聚合功能,而且和Yarn、Hadoop、Hive、Pig、Spark、Flume等大数据处理框架的兼容性越来越好。我主要是想调研一下看是否能将它用于实时的数据搜索统计、以及实时OLAP的业务场景之上。这里先记录一下ElasticSearch集群的安装配置。
ElasticSearch的一些术语
- 索引(index)
索引(Index)相当于关系型数据库中的表;
- 文档(document)
文档相当于关系型数据库中的行。但ES中的文档不需要有固定的结构,不同文档可以有不同的字段集合。
- 文档类型(type)
在一个索引中,可以用不同的文档类型来代表不同的数据集合。
- 节点和集群
ElastichSearch可以作为一个独立的搜索服务器工作,也可以在多台协同工作的服务器上运行,统称为一个集群,其中有一台被作为Master,其他为Slave;
- 分片(shard)
一个索引会被分隔成多个分片,分别存放于集群中的不同节点中,类似于HDFS的文件块。
- 副本
副本是针对每个分片的,可以为一个分片设置多个副本,分布在不同的节点上,即是容错,也可以提高查询任务的性能,原理同HDFS的文件块副本机制。
硬件及软件环境
两台CentOS,172.16.212.17(32G内存)、172.16.212.102(72G内存)
JAVA: jdk-8u65-linux-x64.tar.gz
ElasticSearch:elasticsearch-2.1.0
下载JAVA和ElasticSearch之后解压到指定目录(/home/liuxiaowen/)。
配置elasticsearch.yml
cluster.name: hy_es //集群名称 node.name: es_node_102 //节点名称,两台节点名称不能一样 path.data: /data/es/data //ES存放数据的目录 path.logs: /data/es/logs //ES存放日志的目录 network.host: 172.16.212.102 //这个可以不配置,默认为0.0.0.0 network.publish_host: 172.16.212.102 //这个可以不配置,默认为0.0.0.0 gateway.recover_after_nodes: 2 //设置集群中N个节点启动时进行数据恢复 discovery.zen.ping_timeout: 10s //节点之间通过ping进行应答的超时时间 discovery.zen.ping.unicast.hosts: ["172.16.212.102", "172.16.212.17"] //集群中可以作为master节点的初始列表,通过这些节点来自动发现新加入集群的节点 discovery.zen.minimum_master_nodes: 1 //配置当前集群中最少的主节点数,对于多于两个节点的集群环境,建议配置大于1
配置ElasticSearch使用内存
$ES_HOME/bin/elasticsearch.in.sh
if [ "x$ES_MIN_MEM" = "x" ]; then
ES_MIN_MEM=10g //最小内存,根据机器内存来定
fi
if [ "x$ES_MAX_MEM" = "x" ]; then
ES_MAX_MEM=36g //最大内存,根据机器内存来定,最好不要超过机器物理内存的50%
fi
配置JAVA环境变量
在用户的.bash_profile中加入:
export JAVA_HOME=/hom/liuxiaowen/jdk1.8.0_65
export PATH=$JAVA_HOME/bin:$PATH
或者在$ES_HOME/bin/elasticsearch脚本中配置:
export JAVA_HOME=/hom/liuxiaowen/jdk1.8.0_65
或者在启动ElasticSearch之前在命令行export JAVA_HOME=/hom/liuxiaowen/jdk1.8.0_65
都可以。
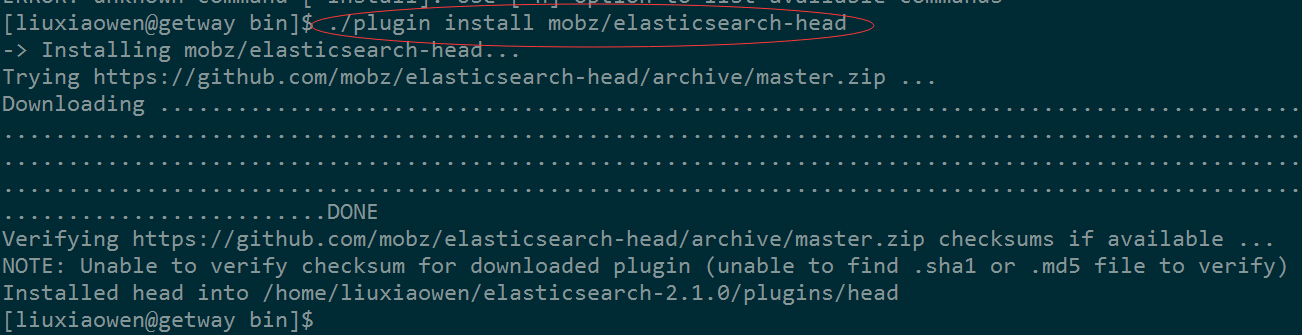
安装head监控插件
cd $ES_HOME/bin
./plugin install mobz/elasticsearch-head
需要在两台机器上都安装。
安装成功后,如图所示:
启动ElasticSearch
cd $ES_HOME/bin
./elasticsearch -d
-d参数表示在后台启动。
ElasticSearch运行日志在配置的${path.logs}/${cluster.name}.log中
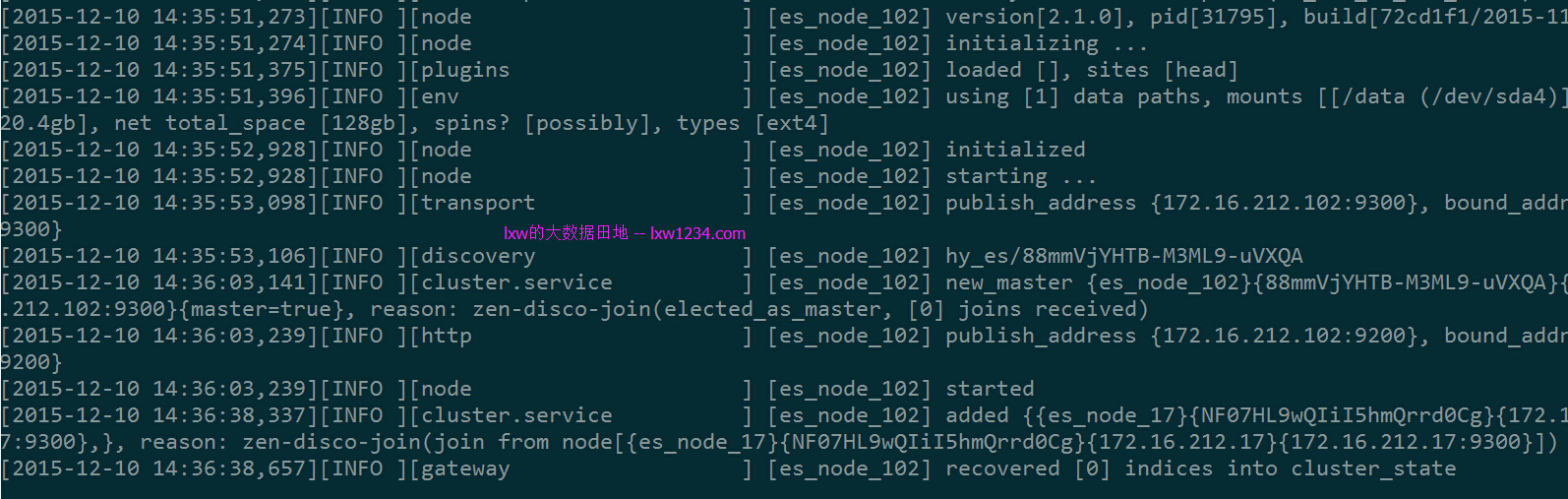
Master(102)
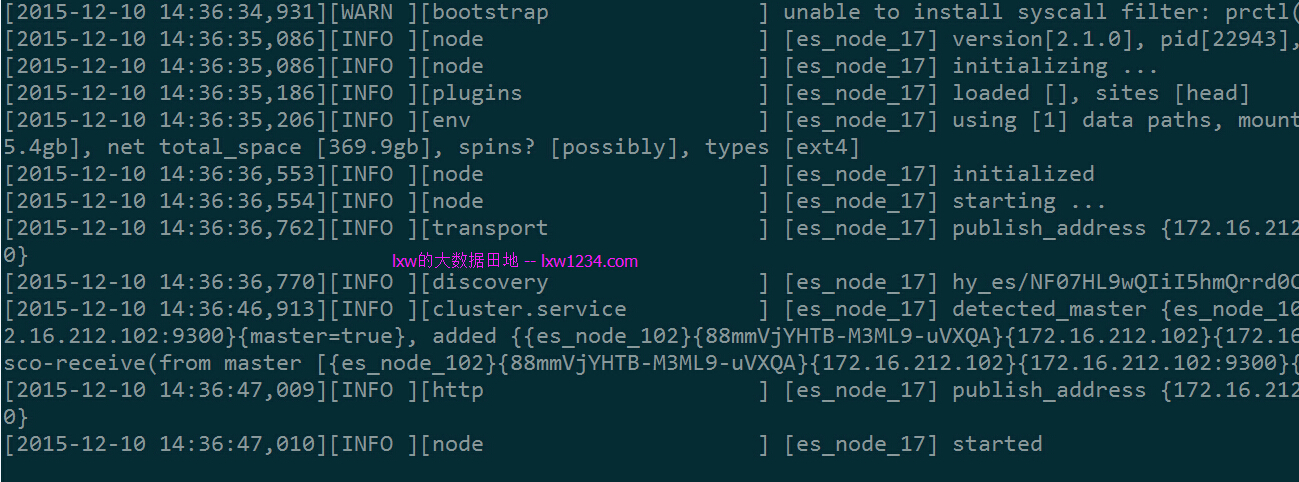
Slave(17)
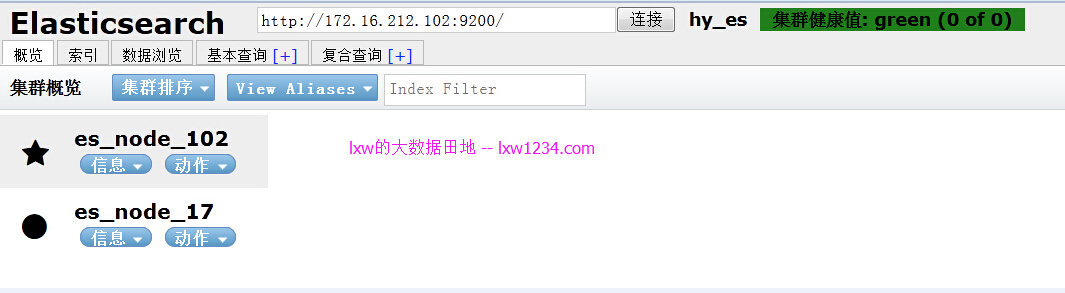
head监控页面(http://172.16.212.102:9200/_plugin/head/)
查看集群状态:
curl -XGET 'http://172.16.212.102:9200/_cluster/health?pretty'
响应结果:
{
"cluster_name" : "hy_es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 5,
"active_shards" : 10,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
集群配置完毕,刚接触,有些参数可能配置的不合理,后续再慢慢研究。
接下来将介绍ElasticSearch的一些基本操作。
您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » ElasticSearch集群安装配置
