关于Impala
Impala是SQL ON Hadoop框架,和它类似的有Presto、Drill等,但它和Hive区别较大,请参考下面的介绍。
下面的介绍来自百度百科:
-
Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
-
省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
-
Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
-
通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
-
用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
-
使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
Impala适合大规模数据的交互式查询,内存要求很高,但它并不太适合海量数据的批处理。因此,常用的方式是使用Hive完成离线批处理过程,之上使用Impala提供交互式即席查询。
本文介绍的是以RPM方式安装和配置Impala。
我的环境
CentOS 7 (64位)
hadoop-2.6.0-cdh5.8.3
hbase-1.2.0-cdh5.8.3 (即使不用HBase,也需要为Impala指定HBase相关的jar包)
hive-1.1.0-cdh5.8.3(Impala目前好像还不支持Hive2.0)
sentry-1.5.1-cdh5.8.3(Impala依赖)
zookeeper-3.4.6
impala-2.6.0+cdh5.8.3
下载RPM包
在http://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/5.8.3/RPMS/x86_64/页面中下载以下RPM包(如果你的操作系统不是CentOS7,请选择对应的操作系统页面):
impala-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-catalog-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-debuginfo-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-server-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-shell-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-state-store-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
impala-udf-devel-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
安装依赖包
wget http://archive.cloudera.com/cdh5/redhat/7/x86_64/cdh/5.8.3/RPMS/noarch/bigtop-utils-0.7.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.noarch.rpm
rpm -ivh bigtop-utils-0.7.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.noarch.rpm
yum install redhat-lsb
PS:redhat-lsb依赖的包很多,最好采用在线yum方式安装。
HADOOP_HOME=/home/bigdata/hadoop/current
HBASE_HOME=/home/bigdata/hbase/current
ZK_HOME=/home/bigdata/zk/current
SENTRY_HOME=/home/bigdata/sentry/current
HIVE_HOME=/home/bigdata/hive/current
PS:此步需要在所有节点以root用户执行。
Master节点
rpm -ivh –nodeps impala-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-state-store-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-catalog-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-udf-devel-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-debuginfo-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
PS:此步需要在Master节点以root用户执行。
Slave节点
rpm -ivh –nodeps impala-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-server-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-shell-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-udf-devel-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
rpm -ivh impala-debuginfo-2.6.0+cdh5.8.3+0-1.cdh5.8.3.p0.7.el7.x86_64.rpm
PS:此步需要在所有Slave节点以root用户执行。
修复/usr/lib/impala/lib下的软链接
由于我的Hadoop、Hive、HBase等环境都是通过tar包命令行方式安装的,因此需要修复Impala默认的链接:
PS:此步需要在所有节点以root用户执行。
cd /usr/lib/impala/lib/
删除无效链接:
rm -f avro.jar rm -f hadoop-aws.jar rm -f hadoop-annotations.jar rm -f hadoop-auth.jar rm -f hadoop-common.jar rm -f hadoop-hdfs.jar rm -f hadoop-mapreduce-client-common.jar rm -f hadoop-mapreduce-client-core.jar rm -f hadoop-mapreduce-client-jobclient.jar rm -f hadoop-mapreduce-client-shuffle.jar rm -f hadoop-yarn-api.jar rm -f hadoop-yarn-client.jar rm -f hadoop-yarn-common.jar rm -f hadoop-yarn-server-applicationhistoryservice.jar rm -f hadoop-yarn-server-common.jar rm -f hadoop-yarn-server-nodemanager.jar rm -f hadoop-yarn-server-resourcemanager.jar rm -f hadoop-yarn-server-web-proxy.jar rm -f hive-ant.jar rm -f hive-beeline.jar rm -f hive-common.jar rm -f hive-exec.jar rm -f hive-hbase-handler.jar rm -f hive-metastore.jar rm -f hive-serde.jar rm -f hive-service.jar rm -f hive-shims-common.jar rm -f hive-shims.jar rm -f hive-shims-scheduler.jar rm -f libhadoop.so rm -f libhadoop.so.1.0.0 rm -f libhdfs.so rm -f libhdfs.so.0.0.0 rm -f zookeeper.jar rm -f parquet-hadoop-bundle.jar rm -f sentry-binding-hive.jar rm -f sentry-core-common.jar rm -f sentry-core-model-db.jar rm -f sentry-core-model-kafka.jar rm -f sentry-core-model-search.jar rm -f sentry-policy-common.jar rm -f sentry-policy-db.jar rm -f sentry-policy-kafka.jar rm -f sentry-policy-search.jar rm -f sentry-provider-cache.jar rm -f sentry-provider-common.jar rm -f sentry-provider-db-sh.jar rm -f sentry-provider-file.jar rm -f hbase-annotations.jar rm -f hbase-client.jar rm -f hbase-common.jar rm -f hbase-protocol.jar
新建软链接:
HADOOP_HOME=/home/bigdata/hadoop/current HBASE_HOME=/home/bigdata/hbase/current ZK_HOME=/home/bigdata/zk/current SENTRY_HOME=/home/bigdata/sentry/current HIVE_HOME=/home/bigdata/hive/current ln -s $HADOOP_HOME/share/hadoop/common/lib/avro-1.7.6-cdh5.8.3.jar avro.jar ln -s $HADOOP_HOME/share/hadoop/common/lib/hadoop-annotations-2.6.0-cdh5.8.3.jar hadoop-annotations.jar ln -s $HADOOP_HOME/share/hadoop/common/lib/hadoop-auth-2.6.0-cdh5.8.3.jar hadoop-auth.jar ln -s $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0-cdh5.8.3.jar hadoop-common.jar ln -s $HADOOP_HOME/share/hadoop/hdfs/hadoop-hdfs-2.6.0-cdh5.8.3.jar hadoop-hdfs.jar ln -s $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.6.0-cdh5.8.3.jar hadoop-mapreduce-client-common.jar ln -s $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0-cdh5.8.3.jar hadoop-mapreduce-client-core.jar ln -s $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.8.3.jar hadoop-mapreduce-client-jobclient.jar ln -s $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.6.0-cdh5.8.3.jar hadoop-mapreduce-client-shuffle.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-api-2.6.0-cdh5.8.3.jar hadoop-yarn-api.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-client-2.6.0-cdh5.8.3.jar hadoop-yarn-client.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-common-2.6.0-cdh5.8.3.jar hadoop-yarn-common.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.6.0-cdh5.8.3.jar hadoop-yarn-server-applicationhistoryservice.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-common-2.6.0-cdh5.8.3.jar hadoop-yarn-server-common.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.6.0-cdh5.8.3.jar hadoop-yarn-server-nodemanager.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.6.0-cdh5.8.3.jar hadoop-yarn-server-resourcemanager.jar ln -s $HADOOP_HOME/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.6.0-cdh5.8.3.jar hadoop-yarn-server-web-proxy.jar ln -s $HIVE_HOME/lib/hive-ant-1.1.0-cdh5.8.3.jar hive-ant.jar ln -s $HIVE_HOME/lib/hive-beeline-1.1.0-cdh5.8.3.jar hive-beeline.jar ln -s $HIVE_HOME/lib/hive-common-1.1.0-cdh5.8.3.jar hive-common.jar ln -s $HIVE_HOME/lib/hive-exec-1.1.0-cdh5.8.3.jar hive-exec.jar ln -s $HIVE_HOME/lib/hive-hbase-handler-1.1.0-cdh5.8.3.jar hive-hbase-handler.jar ln -s $HIVE_HOME/lib/hive-metastore-1.1.0-cdh5.8.3.jar hive-metastore.jar ln -s $HIVE_HOME/lib/hive-serde-1.1.0-cdh5.8.3.jar hive-serde.jar ln -s $HIVE_HOME/lib/hive-service-1.1.0-cdh5.8.3.jar hive-service.jar ln -s $HIVE_HOME/lib/hive-shims-common-1.1.0-cdh5.8.3.jar hive-shims-common.jar ln -s $HIVE_HOME/lib/hive-shims-1.1.0-cdh5.8.3.jar hive-shims.jar ln -s $HIVE_HOME/lib/hive-shims-scheduler-1.1.0-cdh5.8.3.jar hive-shims-scheduler.jar ln -s $HBASE_HOME/lib/hbase-annotations-1.2.0-cdh5.8.3.jar hbase-annotations.jar ln -s $HBASE_HOME/lib/hbase-client-1.2.0-cdh5.8.3.jar hbase-client.jar ln -s $HBASE_HOME/lib/hbase-common-1.2.0-cdh5.8.3.jar hbase-common.jar ln -s $HBASE_HOME/lib/hbase-protocol-1.2.0-cdh5.8.3.jar hbase-protocol.jar ln -s $HADOOP_HOME/lib/native/libhadoop.so libhadoop.so ln -s $HADOOP_HOME/lib/native/libhadoop.so.1.0.0 libhadoop.so.1.0.0 ln -s $ZK_HOME/zookeeper-3.4.6.jar zookeeper.jar ln -s $SENTRY_HOME/lib/parquet-hadoop-bundle-1.5.0-cdh5.8.3.jar parquet-hadoop-bundle.jar ln -s $SENTRY_HOME/lib/sentry-binding-hive-1.5.1-cdh5.8.3.jar sentry-binding-hive.jar ln -s $SENTRY_HOME/lib/sentry-core-common-1.5.1-cdh5.8.3.jar sentry-core-common.jar ln -s $SENTRY_HOME/lib/sentry-core-model-db-1.5.1-cdh5.8.3.jar sentry-core-model-db.jar ln -s $SENTRY_HOME/lib/sentry-core-model-kafka-1.5.1-cdh5.8.3.jar sentry-core-model-kafka.jar ln -s $SENTRY_HOME/lib/sentry-core-model-search-1.5.1-cdh5.8.3.jar sentry-core-model-search.jar ln -s $SENTRY_HOME/lib/sentry-policy-common-1.5.1-cdh5.8.3.jar sentry-policy-common.jar ln -s $SENTRY_HOME/lib/sentry-policy-db-1.5.1-cdh5.8.3.jar sentry-policy-db.jar ln -s $SENTRY_HOME/lib/sentry-policy-kafka-1.5.1-cdh5.8.3.jar sentry-policy-kafka.jar ln -s $SENTRY_HOME/lib/sentry-policy-search-1.5.1-cdh5.8.3.jar sentry-policy-search.jar ln -s $SENTRY_HOME/lib/sentry-provider-cache-1.5.1-cdh5.8.3.jar sentry-provider-cache.jar ln -s $SENTRY_HOME/lib/sentry-provider-common-1.5.1-cdh5.8.3.jar sentry-provider-common.jar ln -s $SENTRY_HOME/lib/sentry-provider-db-1.5.1-cdh5.8.3.jar sentry-provider-db-sh.jar ln -s $SENTRY_HOME/lib/sentry-provider-file-1.5.1-cdh5.8.3.jar sentry-provider-file.jar
修改HDFS配置
PS:此步需要在所有Hadoop节点以hadoop超级用户执行。
vi hdfs-site.xml
<property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name>dfs.domain.socket.path</name> <value>/var/run/hadoop/dn._PORT</value> </property> <property> <name>dfs.datanode.hdfs-blocks-metadata.enabled</name> <value>true</value> </property> <property> <name>dfs.client.use.legacy.blockreader.local</name> <value>false</value> </property> <property> <name>dfs.datanode.data.dir.perm</name> <value>750</value> </property> <property> <name>dfs.block.local-path-access.user</name> <value>hadoop</value> </property> <property> <name>dfs.client.file-block-storage-locations.timeout</name> <value>3000</value> </property>
重启HDFS,注意需要创建/var/run/hadoop/目录,并且具有写权限。
配置Impala
PS:此步需要在所有节点以root用户执行。
在/etc/impala/conf下建立Hadoop和Hive的配置文件链接
ln -s $HIVE_HOME/conf/hive-site.xml hive-site.xml
ln -s $HIVE_HOME/conf/hive-env.sh hive-env.sh
ln -s /etc/hadoop/conf/core-site.xml core-site.xml
ln -s /etc/hadoop/conf/hdfs-site.xml hdfs-site.xml
编辑/etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=192.168.180.10
IMPALA_STATE_STORE_HOST=192.168.180.10
IMPALA_STATE_STORE_PORT=24000
IMPALA_BACKEND_PORT=22000
IMPALA_LOG_DIR=/var/log/impala
IMPALA_CATALOG_ARGS=" -log_dir=${IMPALA_LOG_DIR} "
IMPALA_STATE_STORE_ARGS=" -log_dir=${IMPALA_LOG_DIR} -state_store_port=${IMPALA_STATE_STORE_PORT}"
IMPALA_SERVER_ARGS=" \
-log_dir=${IMPALA_LOG_DIR} \
-catalog_service_host=${IMPALA_CATALOG_SERVICE_HOST} \
-state_store_port=${IMPALA_STATE_STORE_PORT} \
-use_statestore \
-state_store_host=${IMPALA_STATE_STORE_HOST} \
-be_port=${IMPALA_BACKEND_PORT}"
ENABLE_CORE_DUMPS=false
# LIBHDFS_OPTS=-Djava.library.path=/usr/lib/impala/lib
HIVE_HOME=/home/bigdata/hive/current
MYSQL_CONNECTOR_JAR=${HIVE_HOME}/lib/mysql-connector-java-5.1.40-bin.jar
HADOOP_CONF_DIR=/etc/hadoop/conf
# IMPALA_BIN=/usr/lib/impala/sbin
# IMPALA_HOME=/usr/lib/impala
# HBASE_HOME=/usr/lib/hbase
# IMPALA_CONF_DIR=/etc/impala/conf
# HADOOP_CONF_DIR=/etc/impala/conf
# HIVE_CONF_DIR=/etc/impala/conf
# HBASE_CONF_DIR=/etc/impala/conf
修改impala运行用户
PS:此步需要在所有节点以root用户执行。
impala默认以impala用户执行,可以在三个文件中修改 /etc/init.d/impala-state-store、/etc/init.d/impala-server、/etc/init.d/impala-catalog
SVC_USER=”hadoop”
install -d -m 0755 -o hadoop -g hadoop /var/run/impala 1>/dev/null 2>&1 || :
修改日志目录权限:
chmod -R 777 /var/log/impala/
补充依赖jar包
PS:此步需要在所有节点以root用户执行。
将$HIVE_HOME/lib/mysql-connector-java-5.1.40-bin.jar 复制到 /usr/lib/impala/lib下,
并且修改/usr/bin/catalogd中修改CLASSPATH,添加MySQL驱动包:
export CLASSPATH=”${IMPALA_HOME}/lib/mysql-connector-java-5.1.40-bin.jar:……”
启动Master
PS:此步需要在Master节点以root用户执行。
service impala-state-store start
service impala-catalog start
启动Slave
PS:此步需要在所有Slave节点以root用户执行。
service impala-server start
查看日志
启动后,在/var/log/impala目录下会产生对应服务的日志。
连接测试
到任意一台Slave节点上,执行impala-shell命令,进入impala命令行:
初步试了一下,它的性能表现还是很不错的。
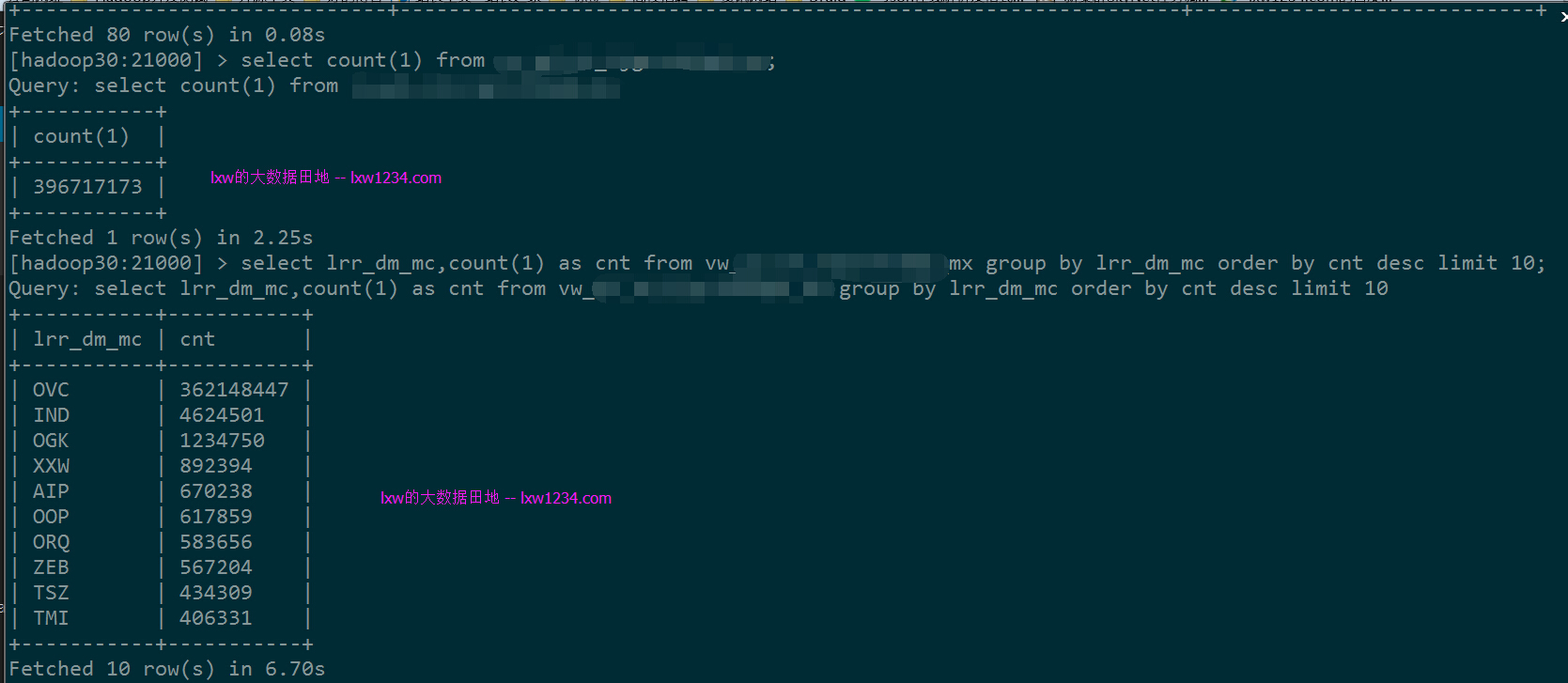
接下来会继续看看它的内存管理、监控、JDBC连接、负载均衡等。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Impala安装配置–RPM方式
