关键字:caravel、python3、hiveserver2、sparksql、spark thrift server、impyla
之前在Caravel中想通过pyhive连接Spark Thrift Server做查询分析,发现pyhive不支持python3。
这两天找到了Cloudera开源的impyla支持python3,impyla可以用来连接impala、hive,想试一下是否适用于Spark Thrift Server,试验结果是可用的。
本文介绍在Python3环境下,使用Caravel连接Spark Thrift Server,来完成Hive中数据的多维分析与可视化。
我测试使用的相关环境如下:
Caravel0.9.1(做过一些修改);
Python 3.5.1
apache-hive-2.1.0-bin
spark-2.0.0-bin-hadoop2.3
在Yarn上运行Spark Thrift Server
将hive-site.xml拷贝到$SPARK_HOME/conf下,进入$SPARK_HOME/sbin/目录,执行下面的命令:
./start-thriftserver.sh --master yarn --conf spark.driver.memory=3G --executor-memory 1G --num-executors 10
这样,便会在Yarn上运行Spark Thrift Server。
安装impyla
参照官网https://github.com/cloudera/impyla中的安装步骤执行:
pip install six pip install bit_array pip install thriftpy ## thrift (on Python 2.x) or thriftpy (on Python 3.x) pip install thrift_sasl pip install sasl pip install impyla ## 注意:还需要安装另外一个模块,官网上并没有给出(for python3): pip install git+https://github.com/laserson/python-sasl.git@cython
安装完后,可以使用下面的脚本来测试是否可以成功连接:
from impala.dbapi import connect
conn = connect(host='127.0.0.217', port=10001, user='liuxiaowen', password='', database='liuxiaowen', auth_mechanism='PLAIN')
cursor = conn.cursor()
cursor.execute('SELECT * FROM liuxiaowen.lxw_pbs_uv_fact LIMIT 100')
print(cursor.description) # prints the result set's schema
results = cursor.fetchall()
print(results)
如果没有启用用户认证,密码留空即可。
注意:必须设置auth_mechanism=’PLAIN’
在Caravel中配置连接SparkThriftServer
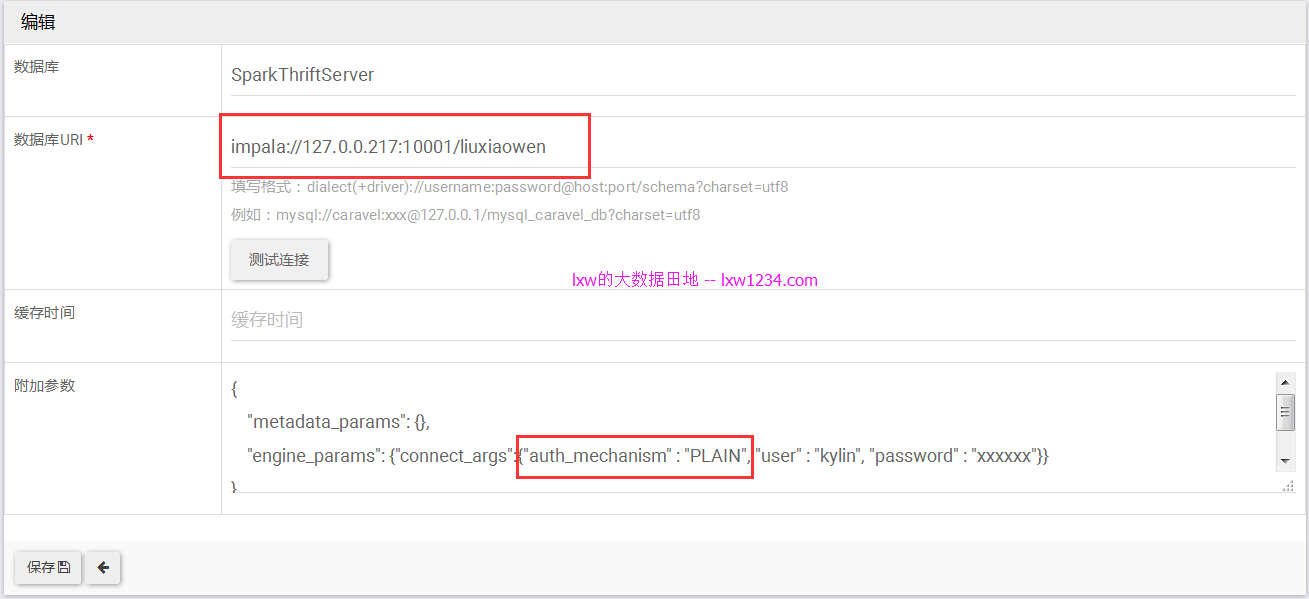
数据库URI:impala://127.0.0.217:10001/liuxiaowen
其他Connect的参数需要填在engine_params中:
“engine_params”: {“connect_args”:{“auth_mechanism” : “PLAIN”, “user” : “kylin”, “password” : “xxxxxx”}}
测试连接之后即可看到Hive中的表。
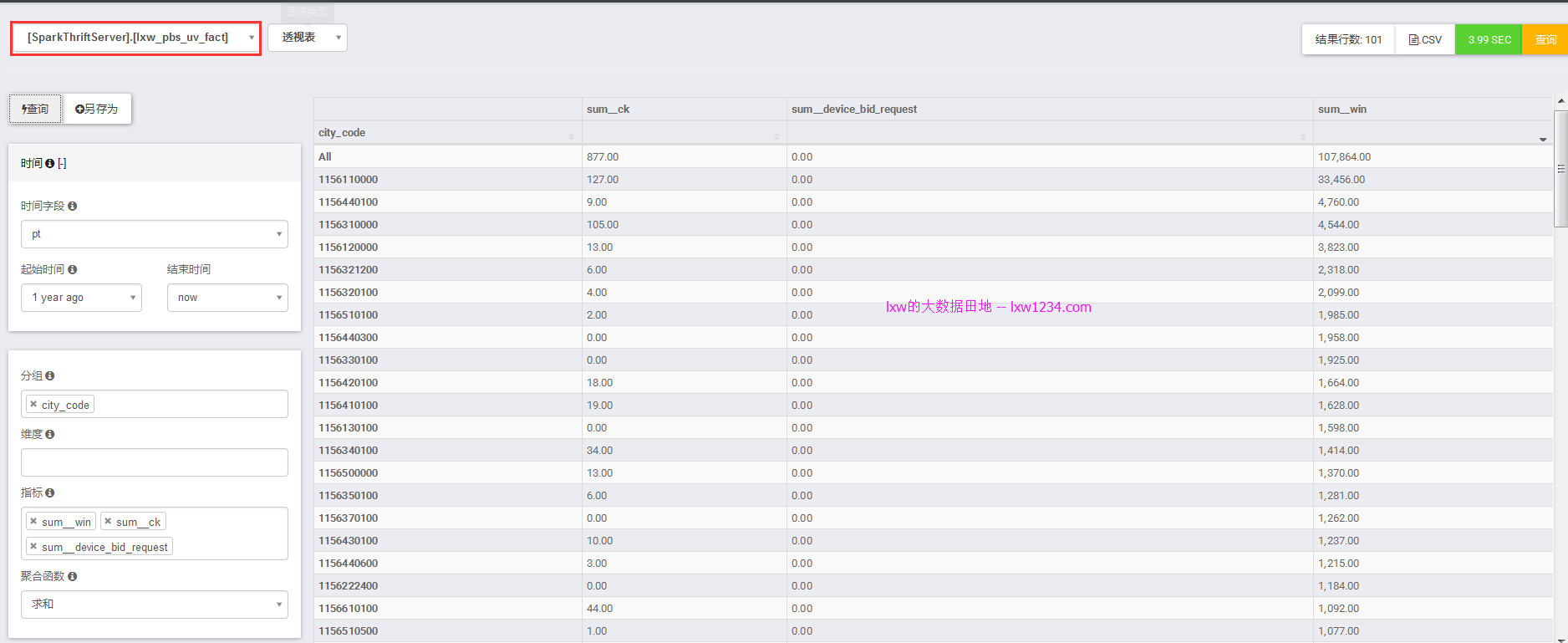
配置好事实表模型之后,就可以进行自助多维分析了。
如果觉得本博客对您有帮助,请 赞助作者 。

