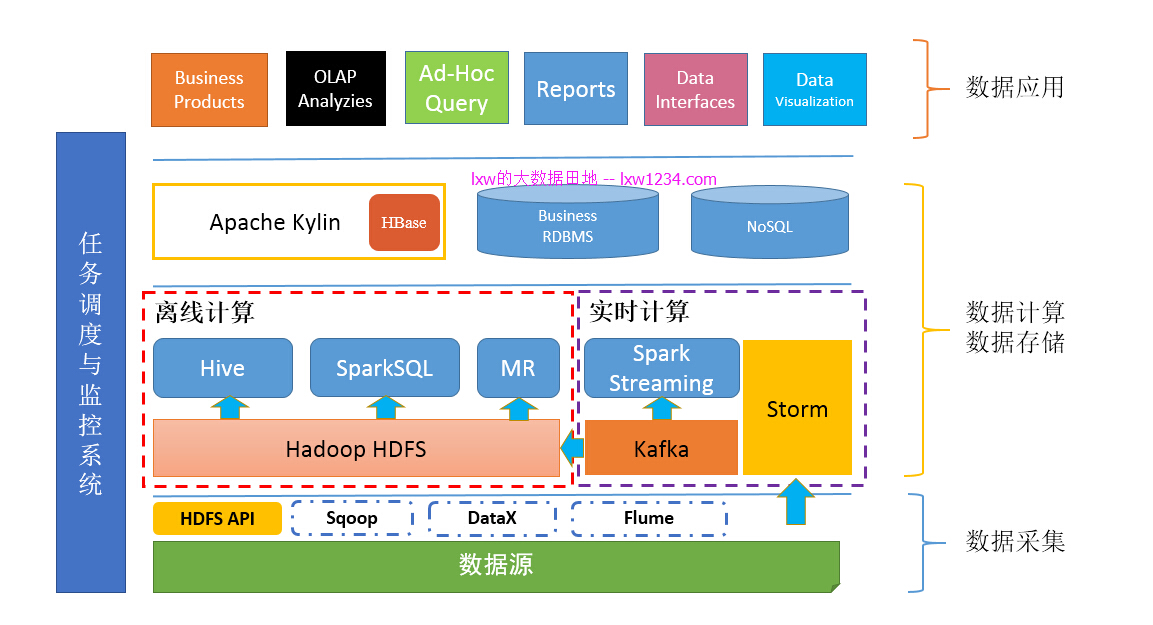
иҮіжӯӨпјҢдҪ зҡ„еӨ§ж•°жҚ®е№іеҸ°еә•еұӮжһ¶жһ„е·Із»ҸжҲҗеһӢдәҶпјҢе…¶дёӯеҢ…жӢ¬дәҶж•°жҚ®йҮҮйӣҶгҖҒж•°жҚ®еӯҳеӮЁдёҺи®Ўз®—пјҲзҰ»зәҝе’Ңе®һж—¶пјүгҖҒж•°жҚ®еҗҢжӯҘгҖҒд»»еҠЎи°ғеәҰдёҺзӣ‘жҺ§иҝҷеҮ еӨ§жЁЎеқ—гҖӮжҺҘдёӢжқҘжҳҜж—¶еҖҷиҖғиҷ‘еҰӮдҪ•жӣҙеҘҪзҡ„еҜ№еӨ–жҸҗдҫӣж•°жҚ®дәҶгҖӮ
第д№қз« пјҡжҲ‘зҡ„ж•°жҚ®иҰҒеҜ№еӨ–
йҖҡеёёеҜ№еӨ–пјҲдёҡеҠЎпјүжҸҗдҫӣж•°жҚ®и®ҝй—®пјҢеӨ§дҪ“дёҠеҢ…еҗ«д»ҘдёӢж–№йқўпјҡ
- зҰ»зәҝпјҡжҜ”еҰӮпјҢжҜҸеӨ©е°ҶеүҚдёҖеӨ©зҡ„ж•°жҚ®жҸҗдҫӣеҲ°жҢҮе®ҡзҡ„ж•°жҚ®жәҗпјҲDBгҖҒFILEгҖҒFTPпјүзӯүпјӣ
зҰ»зәҝж•°жҚ®зҡ„жҸҗдҫӣеҸҜд»ҘйҮҮз”ЁSqoopгҖҒDataXзӯүзҰ»зәҝж•°жҚ®дәӨжҚўе·Ҙе…·гҖӮ
- е®һж—¶пјҡжҜ”еҰӮпјҢеңЁзәҝзҪ‘з«ҷзҡ„жҺЁиҚҗзі»з»ҹпјҢйңҖиҰҒе®һж—¶д»Һж•°жҚ®е№іеҸ°дёӯиҺ·еҸ–з»ҷз”ЁжҲ·зҡ„жҺЁиҚҗж•°жҚ®пјҢиҝҷз§ҚиҰҒжұӮ延时йқһеёёдҪҺпјҲ50жҜ«з§’д»ҘеҶ…пјүгҖӮ
ж №жҚ®е»¶ж—¶иҰҒжұӮе’Ңе®һж—¶ж•°жҚ®зҡ„жҹҘиҜўйңҖиҰҒпјҢеҸҜиғҪзҡ„ж–№жЎҲжңүпјҡHBaseгҖҒRedisгҖҒMongoDBгҖҒElasticSearchзӯүгҖӮ
- OLAPеҲҶжһҗпјҡOLAPйҷӨдәҶиҰҒжұӮеә•еұӮзҡ„ж•°жҚ®жЁЎеһӢжҜ”иҫғ规иҢғпјҢеҸҰеӨ–пјҢеҜ№жҹҘиҜўзҡ„е“Қеә”йҖҹеәҰиҰҒжұӮд№ҹи¶ҠжқҘи¶Ҡй«ҳпјҢеҸҜиғҪзҡ„ж–№жЎҲжңүпјҡImpalaгҖҒPrestoгҖҒSparkSQLгҖҒKylinгҖӮеҰӮжһңдҪ зҡ„ж•°жҚ®жЁЎеһӢжҜ”иҫғ规模пјҢйӮЈд№ҲKylinжҳҜжңҖеҘҪзҡ„йҖүжӢ©гҖӮ
- еҚіеёӯжҹҘиҜўпјҡеҚіеёӯжҹҘиҜўзҡ„ж•°жҚ®жҜ”иҫғйҡҸж„ҸпјҢдёҖиҲ¬еҫҲйҡҫе»әз«ӢйҖҡз”Ёзҡ„ж•°жҚ®жЁЎеһӢпјҢеӣ жӯӨеҸҜиғҪзҡ„ж–№жЎҲжңүпјҡImpalaгҖҒPrestoгҖҒSparkSQLгҖӮ
иҝҷд№ҲеӨҡжҜ”иҫғжҲҗзҶҹзҡ„жЎҶжһ¶е’Ңж–№жЎҲпјҢйңҖиҰҒз»“еҗҲиҮӘе·ұзҡ„дёҡеҠЎйңҖжұӮеҸҠж•°жҚ®е№іеҸ°жҠҖжңҜжһ¶жһ„пјҢйҖүжӢ©еҗҲйҖӮзҡ„гҖӮеҺҹеҲҷеҸӘжңүдёҖдёӘпјҡи¶Ҡз®ҖеҚ•и¶ҠзЁіе®ҡзҡ„пјҢе°ұжҳҜжңҖеҘҪзҡ„гҖӮ
еҰӮжһңдҪ е·Із»ҸжҺҢжҸЎдәҶеҰӮдҪ•еҫҲеҘҪзҡ„еҜ№еӨ–пјҲдёҡеҠЎпјүжҸҗдҫӣж•°жҚ®пјҢйӮЈд№ҲдҪ зҡ„вҖңеӨ§ж•°жҚ®е№іеҸ°вҖқеә”иҜҘжҳҜиҝҷж ·зҡ„пјҡ
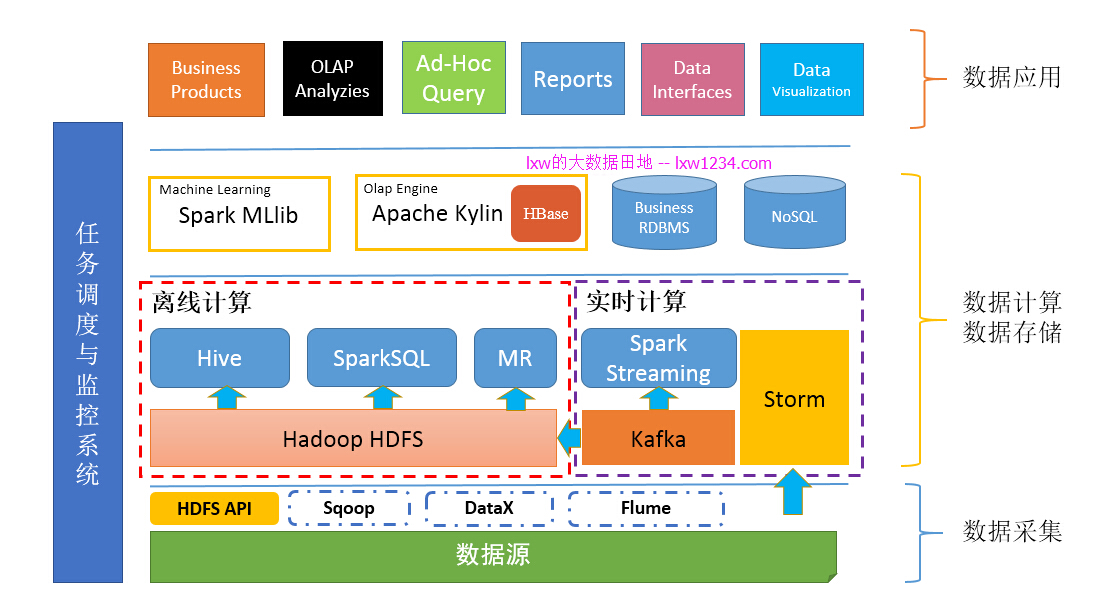
第еҚҒз« пјҡзүӣйҖјй«ҳеӨ§дёҠзҡ„жңәеҷЁеӯҰд№
е…ідәҺиҝҷеқ—пјҢжҲ‘иҝҷдёӘй—ЁеӨ–жұүд№ҹеҸӘиғҪжҳҜз®ҖеҚ•д»Ӣз»ҚдёҖдёӢдәҶгҖӮж•°еӯҰдё“дёҡжҜ•дёҡзҡ„жҲ‘йқһеёёжғӯ愧пјҢеҫҲеҗҺжӮ”еҪ“ж—¶жІЎжңүеҘҪеҘҪеӯҰж•°еӯҰгҖӮ
еңЁжҲ‘们зҡ„дёҡеҠЎдёӯпјҢйҒҮеҲ°зҡ„иғҪз”ЁжңәеҷЁеӯҰд№ и§ЈеҶізҡ„й—®йўҳеӨ§жҰӮиҝҷд№Ҳдёүзұ»пјҡ
- еҲҶзұ»й—®йўҳпјҡеҢ…жӢ¬дәҢеҲҶзұ»е’ҢеӨҡеҲҶзұ»пјҢдәҢеҲҶзұ»е°ұжҳҜи§ЈеҶідәҶйў„жөӢзҡ„й—®йўҳпјҢе°ұеғҸйў„жөӢдёҖе°ҒйӮ®д»¶жҳҜеҗҰеһғеңҫйӮ®д»¶пјӣеӨҡеҲҶзұ»и§ЈеҶізҡ„жҳҜж–Үжң¬зҡ„еҲҶзұ»пјӣ
- иҒҡзұ»й—®йўҳпјҡд»Һз”ЁжҲ·жҗңзҙўиҝҮзҡ„е…ій”®иҜҚпјҢеҜ№з”ЁжҲ·иҝӣиЎҢеӨ§жҰӮзҡ„еҪ’зұ»гҖӮ
- жҺЁиҚҗй—®йўҳпјҡж №жҚ®з”ЁжҲ·зҡ„еҺҶеҸІжөҸи§Ҳе’ҢзӮ№еҮ»иЎҢдёәиҝӣиЎҢзӣёе…іжҺЁиҚҗгҖӮ
еӨ§еӨҡж•°иЎҢдёҡпјҢдҪҝз”ЁжңәеҷЁеӯҰд№ и§ЈеҶізҡ„пјҢд№ҹе°ұжҳҜиҝҷеҮ зұ»й—®йўҳгҖӮ
е…Ҙй—ЁеӯҰд№ зәҝи·Ҝпјҡ
- ж•°еӯҰеҹәзЎҖпјӣ
- жңәеҷЁеӯҰд№ е®һжҲҳпјҲMachine Learning in ActionпјүпјҢжҮӮPythonжңҖеҘҪпјӣ
- SparkMlLibжҸҗдҫӣдәҶдёҖдәӣе°ҒиЈ…еҘҪзҡ„з®—жі•пјҢд»ҘеҸҠзү№еҫҒеӨ„зҗҶгҖҒзү№еҫҒйҖүжӢ©зҡ„ж–№жі•гҖӮ
жңәеҷЁеӯҰд№ зЎ®е®һзүӣйҖјй«ҳеӨ§дёҠпјҢд№ҹжҳҜжҲ‘еӯҰд№ зҡ„зӣ®ж ҮгҖӮ
йӮЈд№ҲпјҢеҸҜд»ҘжҠҠжңәеҷЁеӯҰд№ йғЁеҲҶд№ҹеҠ иҝӣдҪ зҡ„вҖңеӨ§ж•°жҚ®е№іеҸ°вҖқдәҶгҖӮ
зӣёе…ійҳ…иҜ»пјҡ
еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ
еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ2
еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ3
еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ4
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » еҶҷз»ҷеӨ§ж•°жҚ®ејҖеҸ‘еҲқеӯҰиҖ…зҡ„иҜқ5
