本文基于Spark1.3.1,介绍一下Spark基于hadoop-2.3.0-cdh5.0.0的安装配置和简单使用。
我是在一台机器上完成了Spark的部署,其实也是集群,只不过Master和Slave都在一台机器上。如果是多台机器的集群部署,步骤完全一样,只不过多些Slave而已。
一、环境需求
- 下载并安装scala-2.11.4
配置环境变量:
export SCALA_HOME=/usr/local/scala-2.11.4
export PATH=$SCALA_HOME/bin:$PATH - Java 1.7
- Hadoop2.3.0-cdh5
- 下载编译好的Spark安装包
http://spark.apache.org/downloads.html
解压后根目录为:/home/lxw1234/spark-1.3.1-bin-hadoop2.3
- 配置环境变量:
vi ~/.bash_profile
export SPARK_HOME=/home/lxw1234/spark-1.3.1-bin-hadoop2.3
export PATH=$SPARK_HOME/bin:$PATH
source ~/.bash_profile
二、Spark配置
- 配置Spark环境变量
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh 添加以下内容:
export JAVA_HOME=/usr/local/java-1.7.0
export HADOOP_HOME=/opt/hadoop-2.3.0-cdh5.0.0
export HADOOP_CONF_DIR=/etc/hadoop/conf
export SCALA_HOME=/usr/local/scala-2.11.4
export SPARK_HOME=/home/lxw1234/spark-1.3.1-bin-hadoop2.3
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3 //每个Worker使用的CPU核数
export SPARK_WORKER_INSTANCES=1 //每个Slave中启动几个Worker实例
export SPARK_WORKER_MEMORY=10G //每个Worker使用多大的内存
export SPARK_WORKER_WEBUI_PORT=8081 //Worker的WebUI端口号
export SPARK_EXECUTOR_CORES=1 //每个Executor使用使用的核数
export SPARK_EXECUTOR_MEMORY=1G //每个Executor使用的内存
export SPARK_CLASSPATH=/opt/hadoop-lzo/current/hadoop-lzo.jar //由于要用到lzo,因此需要配置
export SPARK_CLASSPATH=$SPARK_CLASSPATH:$CLASSPATH
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
- 配置Slave
cp slaves.template slaves
vi slaves 添加以下内容:
localhost
三、配置免密码ssh登陆
因为Master和Slave处于一台机器,因此配置本机到本机的免密码ssh登陆,如有其他Slave,都需要配置Master到Slave的无密码ssh登陆。
cd ~/ ssh-keygen (一路回车) cd .ssh/ cat id_rsa.pub >> authorized_keys chmod 600 authorized_keys
四、启动Spark Master
cd $SPARK_HOME/sbin/
./start-master.sh
启动日志位于 $SPARK_HOME/logs/目录下,正常启动的日志如下:
15/06/05 14:54:16 INFO server.AbstractConnector: Started SelectChannelConnector@localhost:6066
15/06/05 14:54:16 INFO util.Utils: Successfully started service on port 6066.
15/06/05 14:54:16 INFO rest.StandaloneRestServer: Started REST server for submitting applications on port 6066
15/06/05 14:54:16 INFO master.Master: Starting Spark master at spark://127.0.0.1:7077
15/06/05 14:54:16 INFO master.Master: Running Spark version 1.3.1
15/06/05 14:54:16 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/06/05 14:54:16 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:8099
15/06/05 14:54:16 INFO util.Utils: Successfully started service ‘MasterUI’ on port 8099.
15/06/05 14:54:16 INFO ui.MasterWebUI: Started MasterWebUI at http://127.1.1.1:8099
15/06/05 14:54:16 INFO master.Master: I have been elected leader! New state: ALIVE
在浏览器输入 http://127.1.1.1:8099,即可看到Spark的WebUI界面,如图:
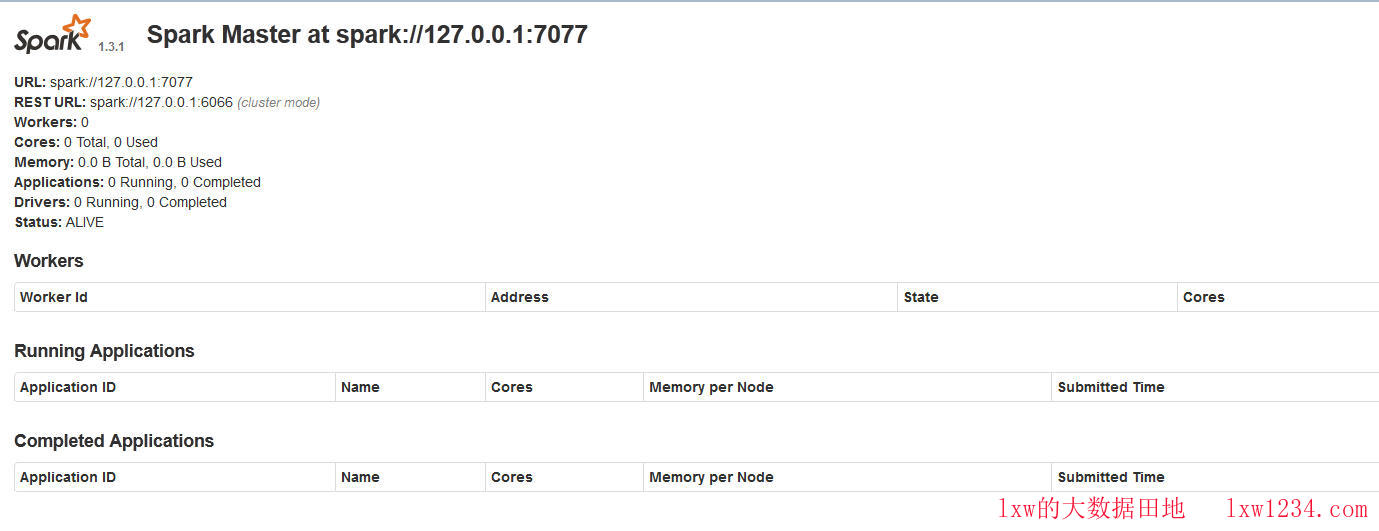
Spark WebUI
五、启动Spark Slave
cd $SPARK_HOME/sbin/
./start-slaves.sh
会根据$SPARK_HOME/conf/slaves文件中配置的主机,逐个ssh过去,启动Spark Worker
成功启动后,在WebUI界面上可以看到,已经有Worker注册上来了,如图:

Spark WebUI
界面上显示,该Worker可用的CPU核数为3,内存为10G,正是上面spark-env.sh中配置的每个Worker使用的CPU核数和内存。
六、运行示例程序,WordCount TOP-N
cd $SPARK_HOME/bin
./spark-shell –master spark://127.0.0.1:7077
进入Spark Shell
这时候在WebUI上观察到,有一个正在运行的Spark Application,即Spark-Shell,如图:

Spark WebUI
运行示例程序,读取HDFS上的文件,统计出现次数TOP50的词语:
在Spark Shell中依次执行:
var srcFile = sc.textFile("/logs/ut/imp/2015-06-02/ds_log_ft_02.log")
var a = srcFile.flatMap(line=>line.split("\\t")).map(word=>(word,1)).reduceByKey(_+_)
a.map(word=>(word._2,word._1)).sortByKey(false).map(word=>(word._2,word._1)).take(50).foreach(println)
运行结果如图:
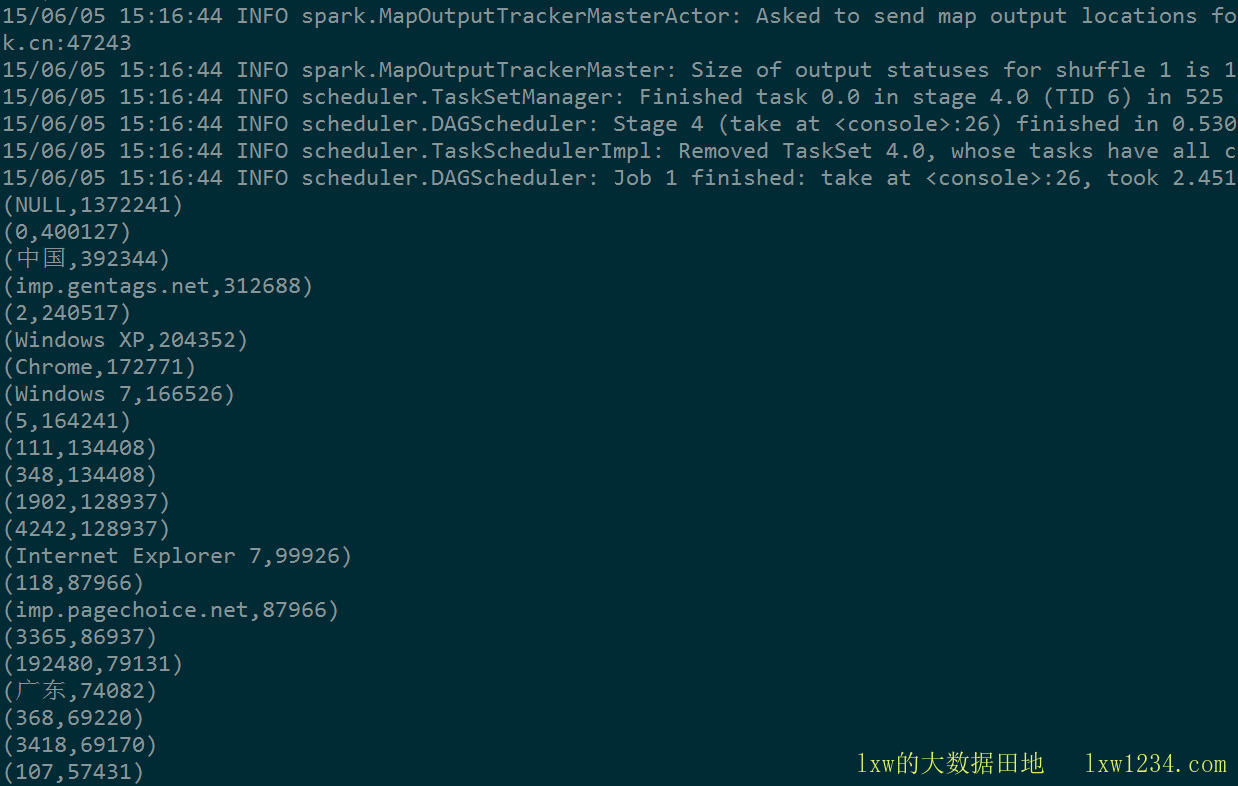
Spark WordCount TopN
180多M的文件,单个Worker,几秒钟就分析完了。
更多有关大数据Hadoop、Spark、Hive的文章,请关注我的博客:http://lxw1234.com
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Spark1.3.1安装配置运行


