Spark也有数据本地化的概念(Data Locality),这和MapReduce的Local Task差不多,如果读取HDFS文件,Spark则会根据数据的存储位置,分配离数据存储最近的Executor去执行任务。
这么理解没错,我搭建的Spark集群情况是这样:
15台DataNode节点的HDFS集群,我在每个DataNode上都部署了一个Spark Worker,并且,启动Spark Application的时候,每个Worker都有一个Executor,这样理论上来说,只要读取HDFS文件,Spark都可以使用本地任务来读取(NODE_LOCAL)。
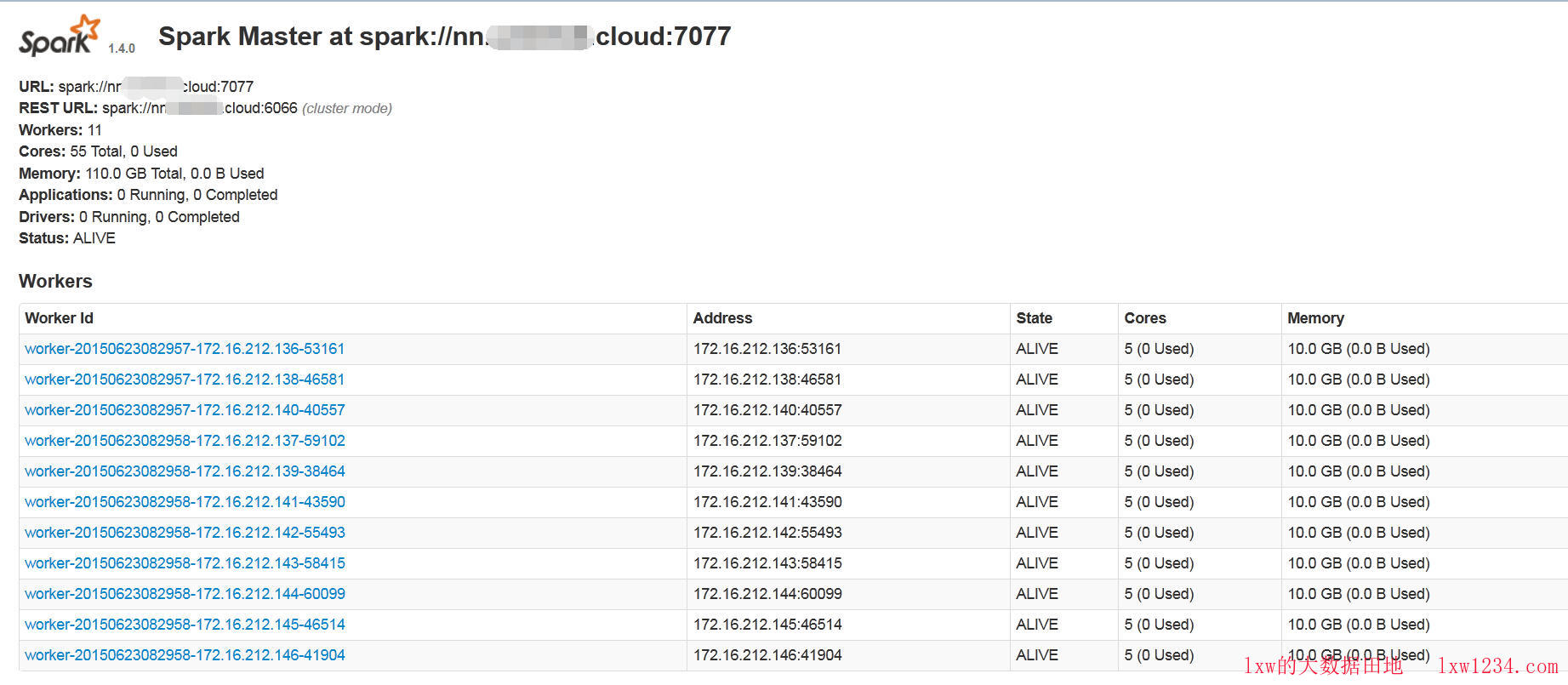
在$SPARK_HOME/conf/slaves文件中配置了每个Worker的hostname,之后在Master上,执行$SPARK_HOME/sbin/start-slaves.sh来启动Workers,启动之后集群如图显示:
进入spark-sql,从hive中扫描一张表,执行情况如下:
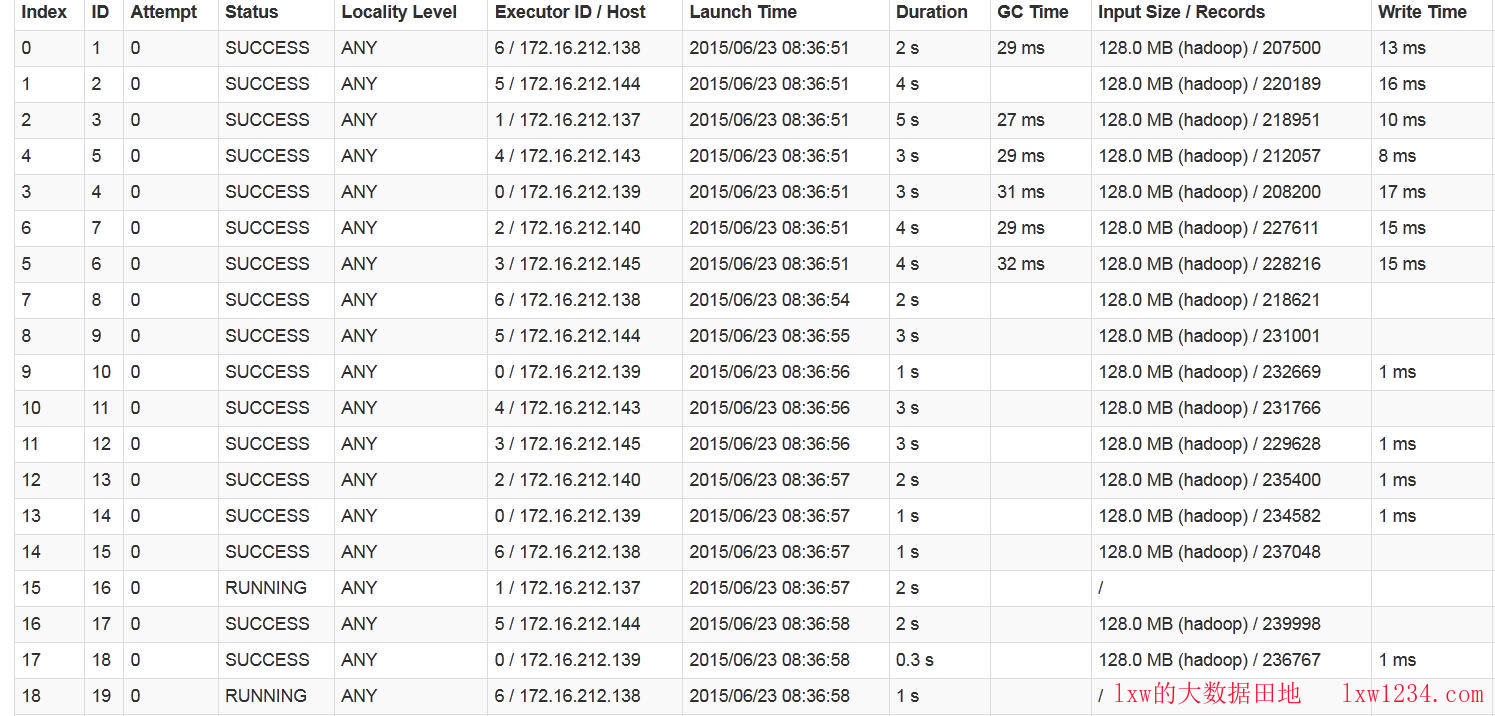
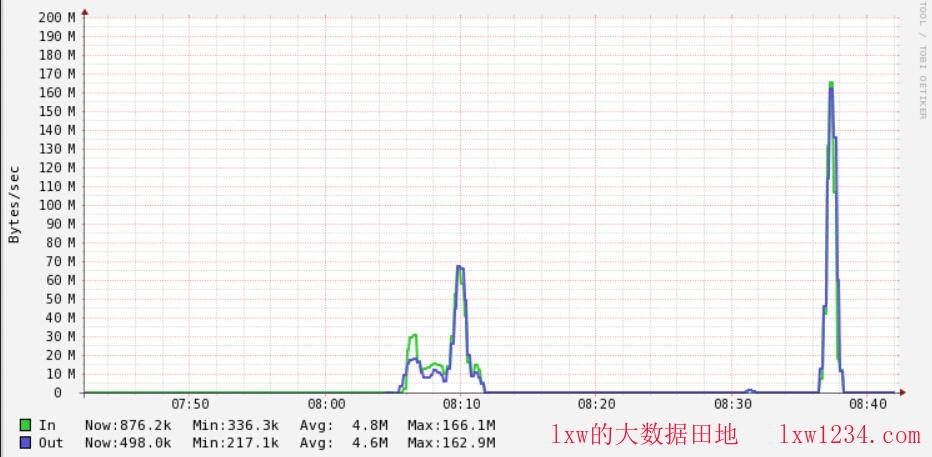
奇怪的是,所有读取HDFS文件的Task Locality Level全部是ANY,也就是说,没有一个使用NODE_LOCAL本地化任务,这样导致集群的网络消耗非常大(因为所有的数据都要经网络拷贝一遍),如图,后面那个峰值是执行任务的网络情况:
直接说原因和解决办法吧。
请注意最上面集群情况的图中,Worker Id和Address中都使用的IP地址作为Worker的标识,而HDFS集群中一般都以hostname作为slave的标识,这样,Spark从HDFS中获取文件的保存位置对应的是hostname,而Spark自己的Worker标识为IP地址,两者不同,因此没有将任务的Locality Level标记为NODE_LOCAL,而是ANY。奇怪的是,我在Spark的slaves文件中都配置的是hostname,为何集群启动后都采用了IP地址?最大的可能是/etc/hosts文件的配置。
解决办法是:没有采用slaves文件+start-slaves.sh的方式启动,而是每台Worker单独启动,
使用命令:$SPARK_HOME/sbin/start-slave.sh -h <hostname> <masterURI>,这样启动之后,Spark WEBUI中Worker Id和Address中都以hostname来显示了,如图:
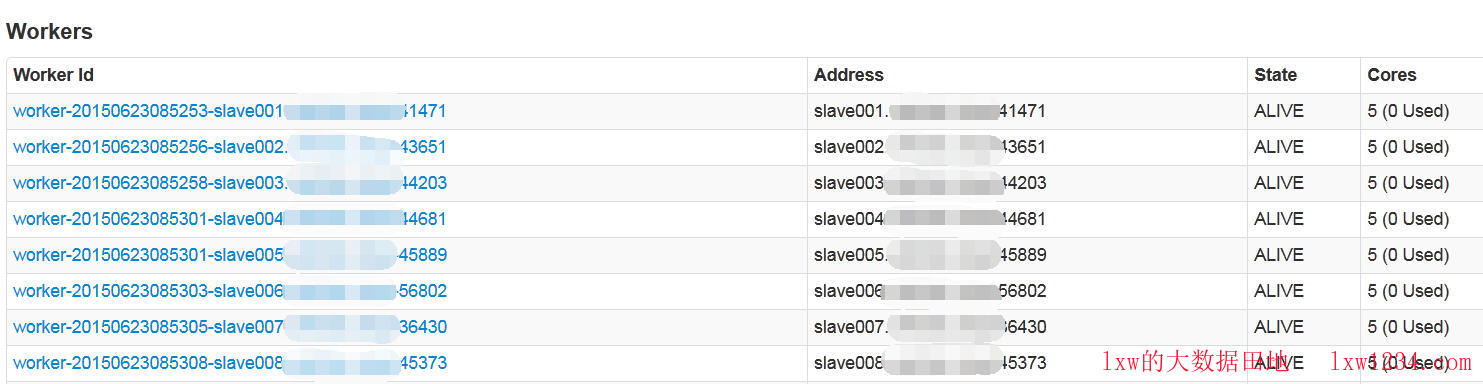
再次进入spark-sql,执行同样的任务,所有的Task Locality Level都是NODE_LOCAL,没有网络传输,速度比之前快了好几倍。
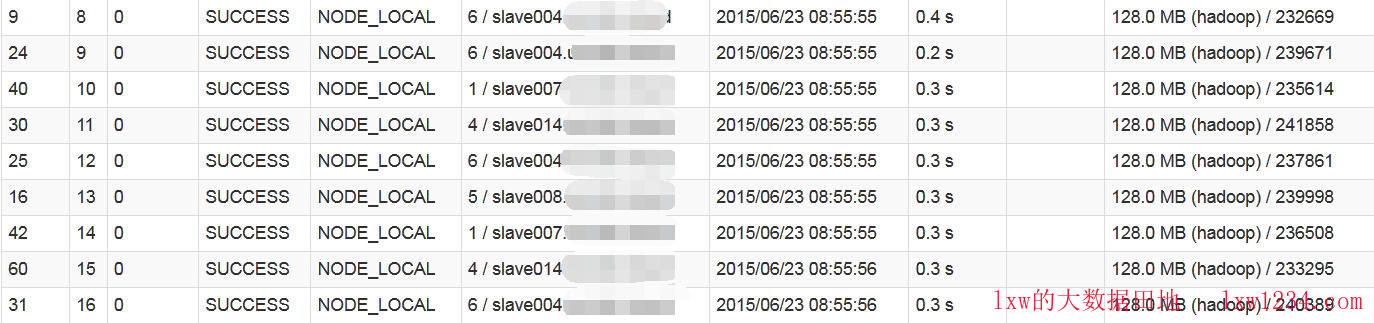
这才是期望的结果,至于导致salves文件中配置的明明是hostname,为何Spark集群中解析成IP地址的原因,后续再查吧。
如果觉得本博客对您有帮助,请 赞助作者 。


