关键字:Spark RDD、Spark RDD partition、Spark RDD dependencies、Spark RDD preferredLocations、Spark RDD compute、Spark RDD partitioner
一、学习Spark RDD
RDD是Spark中的核心数据模型,一个RDD代表着一个被分区(partition)的只读数据集。
RDD的生成只有两种途径:
一种是来自于内存集合或外部存储系统;
另一种是通过转换操作来自于其他RDD;
一般需要了解RDD的以下五个接口:
| partition | 分区,一个RDD会有一个或者多个分区 |
| dependencies() | RDD的依赖关系 |
| preferredLocations(p) | 对于每个分区而言,返回数据本地化计算的节点 |
| compute(p,context) | 对于分区而言,进行迭代计算 |
| partitioner() | RDD的分区函数 |
1.1 RDD分区(partitions)
一个RDD包含一个或多个分区,每个分区都有分区属性,分区的多少决定了对RDD进行并行计算的并行度。
在生成RDD时候可以指定分区数,如果不指定分区数,则采用默认值,系统默认的分区数,是这个程序所分配到的资源的CPU核数。
可以使用RDD的成员变量partitions返回RDD对应的分区数组:
scala> var file = sc.textFile("/tmp/lxw1234/1.txt")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at textFile at :21
scala> file.partitions
res14: Array[org.apache.spark.Partition] = Array(org.apache.spark.rdd.HadoopPartition@735, org.apache.spark.rdd.HadoopPartition@736)
scala> file.partitions.size
res15: Int = 2 //默认两个分区
//可以指定RDD的分区数
scala> var file = sc.textFile("/tmp/lxw1234/1.txt",4)
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at textFile at :21
scala> file.partitions
res16: Array[org.apache.spark.Partition] = Array(org.apache.spark.rdd.HadoopPartition@787, org.apache.spark.rdd.HadoopPartition@788, org.apache.spark.rdd.HadoopPartition@789, org.apache.spark.rdd.HadoopPartition@78a)
scala> file.partitions.size
res17: Int = 4
1.2 RDD依赖关系(dependencies)
由于RDD即可以由外部存储而来,也可以从另一个RDD转换而来,因此,一个RDD会存在一个或多个父的RDD,这里面也就存在依赖关系,
- 窄依赖:
每一个父RDD的分区最多只被子RDD的一个分区所使用,如图所示:
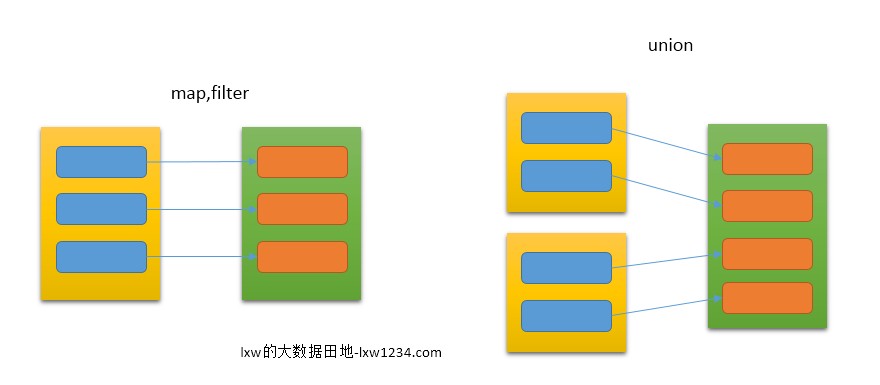
- 宽依赖
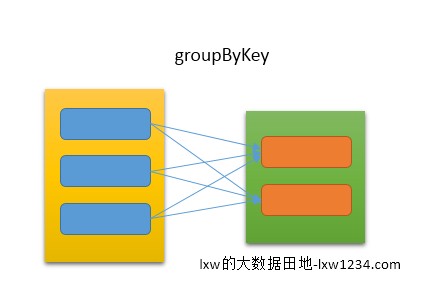
多个子RDD的分区会依赖同一个父RDD的分区,如图所示:
以下代码可以查看RDD的依赖信息:
scala> var file = sc.textFile("/tmp/lxw1234/1.txt")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[9] at textFile at :21
scala> file.dependencies.size
res20: Int = 1 //返回RDD的依赖数量
scala> file.dependencies(0)
res19:
org.apache.spark.Dependency[_] = org.apache.spark.OneToOneDependency@33c5abd0
//返回RDD file的第一个依赖
scala> file.dependencies(1)
java.lang.IndexOutOfBoundsException: 1
//因为file只有一个依赖,想获取第二个依赖时候,报了数组越界
再看一个存在多个父依赖的例子:
scala> var rdd1 = sc.textFile("/tmp/lxw1234/1.txt")
rdd1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at textFile at :21
scala> var rdd2 = sc.textFile("/tmp/lxw1234/1.txt")
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[13] at textFile at :21
scala> var rdd3 = rdd1.union(rdd2)
rdd3: org.apache.spark.rdd.RDD[String] = UnionRDD[14] at union at :25
scala> rdd3.dependencies.size
res24: Int = 2 // rdd3依赖rdd1和rdd2两个RDD
//分别打印出rdd3的两个父rdd,即 rdd1和rdd2的内容
scala> rdd3.dependencies(0).rdd.collect
res29: Array[_] = Array(hello world, hello spark, hello hive, hi spark)
scala> rdd3.dependencies(1).rdd.collect
res30: Array[_] = Array(hello world, hello spark, hello hive, hi spark)
1.3 RDD优先位置(preferredLocations)
RDD的优先位置,返回的是此RDD的每个partition所存储的位置,这个位置和Spark的调度有关(任务本地化),Spark会根据这个位置信息,尽可能的将任务分配到数据块所存储的位置,以从Hadoop中读取数据生成RDD为例,preferredLocations返回每一个数据块所在的机器名或者IP地址,如果每一个数据块是多份存储的(HDFS副本数),那么就会返回多个机器地址。
看以下代码:
scala> var file = sc.textFile("/tmp/lxw1234/1.txt")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[16] at textFile at :21
//这里的file为MappedRDD
scala> var hadoopRDD = file.dependencies(0).rdd
hadoopRDD: org.apache.spark.rdd.RDD[_] = /tmp/lxw1234/1.txt HadoopRDD[15] at textFile at :21 //这里获取file的父RDD,即hdfs文件/tmp/lxw1234/1.txt对应的HadoopRDD
scala> hadoopRDD.partitions.size
res31: Int = 2 //hadoopRDD默认有两个分区
//下面分别获取两个分区的位置信息
scala> hadoopRDD.preferredLocations(hadoopRDD.partitions(0))
res32: Seq[String] = WrappedArray(slave007.lxw1234.com, slave004.lxw1234.com)
scala> hadoopRDD.preferredLocations(hadoopRDD.partitions(1))
res33: Seq[String] = WrappedArray(slave007. lxw1234.com, slave004.lxw1234.com)
##
由于HDFS副本数设置为2,因此每个分区的位置信息中包含了所有副本(2个)的位置信息,这样Spark可以调度时候,根据任何一个副本所处的位置进行本地化任务调度。
1.4 RDD分区计算(compute)
基于RDD的每一个分区,执行compute操作。
对于HadoopRDD来说,compute中就是从HDFS读取分区中数据块信息。
对于JdbcRDD来说,就是连接数据库,执行查询,读取每一条数据。
1.5 RDD分区函数(partitioner)
目前Spark中实现了两种类型的分区函数,HashPartitioner(哈希分区)和RangePartitioner(区域分区)。
partitioner只存在于<K,V>类型的RDD中,非<K,V>类型的RDD的partitioner值为None.
partitioner函数既决定了RDD本身的分区数量,也可作为其父RDD Shuffle输出中每个分区进行数据切割的依据。
scala> var a = sc.textFile("/tmp/lxw1234/1.txt").flatMap(line => line.split("\\s+"))
a: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[19] at flatMap at :21
scala> a.partitioner
res15: Option[org.apache.spark.Partitioner] = None // RDD a为非<K,V>类型
scala> var b = a.map(l => (l,1)).reduceByKey((a,b) => a + b)
b: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[21] at reduceByKey at :30
scala> b.partitioner
res16: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2)
//RDD b为<K,V>类型,采用的是默认的partitioner- HashPartitioner
后续继续学习。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » 学习Spark RDD


