关键字:MapReduce、Hive、子目录、递归、输入、Input、mapreduce.input.fileinputformat.input.dir.recursive、hive.mapred.supports.subdirectories
一般情况下,传递给MapReduce和Hive的input文件夹中不能包含子目录,否则就会报错。但后来增加了递归遍历Input目录的功能,
这个貌似是从0.23开始的,具体不清楚,反正在0.20中是不支持的。
我使用的Hadoop版本为:hadoop-2.3.0-cdh5.0.0
Hive版本为:apache-hive-0.13.1-bin
具体使用示例如下:
数据准备
cat 1.txt 1 1 1 cat 2.txt 2 2 hadoop fs -mkdir /tmp/lxw1234/ hadoop fs -mkdir /tmp/lxw1234/subdir/ hadoop fs -put 1.txt /tmp/lxw1234/ hadoop fs -put 2.txt /tmp/lxw1234/subdir/ hadoop fs -ls -R /tmp/lxw1234/ -rw-r--r-- 2 lxw1234 supergroup 6 2015-07-08 13:56 /tmp/lxw1234/1.txt drwxr-xr-x - lxw1234 supergroup 0 2015-07-08 13:56 /tmp/lxw1234/subdir -rw-r--r-- 2 lxw1234 supergroup 4 2015-07-08 13:56 /tmp/lxw1234/subdir/2.txt
1.txt在/tmp/lxw1234/下,2.txt在/tmp/lxw1234/subdir/目录下。
MapReduce
默认情况下,mapreduce.input.fileinputformat.input.dir.recursive为flase.
运行wordcount:
hadoop jar hadoop-mapreduce-examples-2.3.0-cdh5.0.0.jar wordcount /tmp/lxw1234/ /tmp/output/
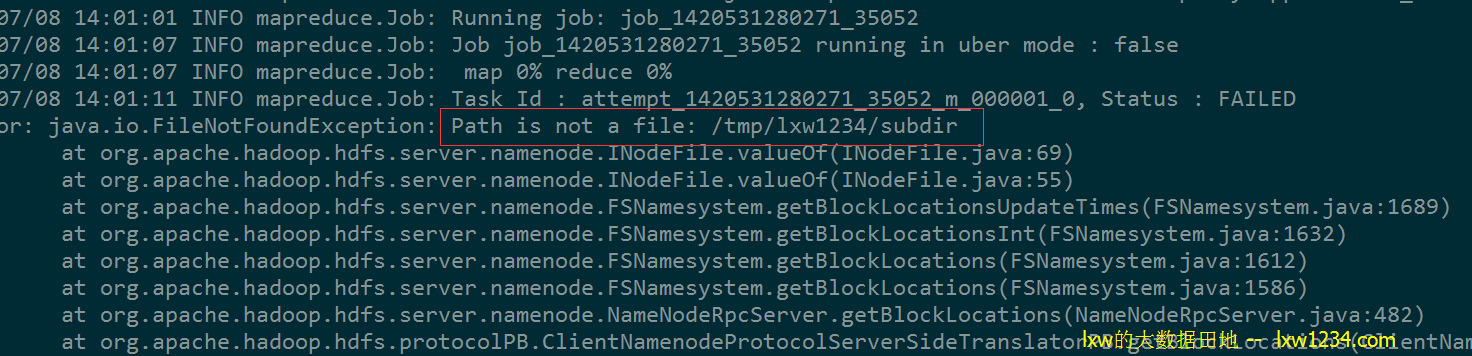
报错 “Error: java.io.FileNotFoundException: Path is not a file: /tmp/lxw1234/subdir”,原因是MapReduce获取/tmp/lxw1234下的列表,把/tmp/lxw1234/subdir也作为一个input file来处理。
设置mapreduce.input.fileinputformat.input.dir.recursive=true,这个参数是客户端参数,可以在MapReduce中设置,也可以在mapred-site.xml中设置,无所谓。
再运行上面的wordcount命令:
hadoop jar hadoop-mapreduce-examples-2.3.0-cdh5.0.0.jar wordcount /tmp/lxw1234/ /tmp/output/
Job成功执行,查看结果:
hadoop fs -cat /tmp/output/*
1 3
2 2
正确。
Hive
仍然使用上面的HDFS路径/tmp/lxw1234/建表:
CREATE EXTERNAL TABLE lxw1234 (d string) stored AS textfile location '/tmp/lxw1234/';
查询:select * from lxw1234;

同样报错 “Not a file: hdfs://cdh5/tmp/lxw1234/subdir” 。
在hive-cli中设置参数:
set hive.mapred.supports.subdirectories=true;
set mapreduce.input.fileinputformat.input.dir.recursive=true;
再执行:
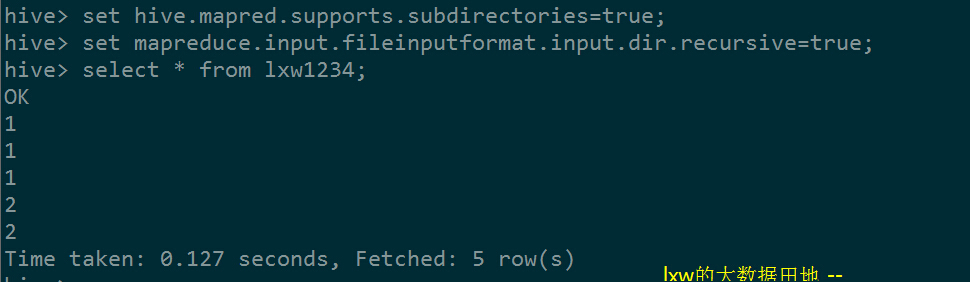
结果正确。
参数mapreduce.input.fileinputformat.input.dir.recursive表示是否在MapReduce中递归遍历Input目录,
Hadoop1.0中该参数为:mapred.input.dir.recursive
Hive中设置hive.mapred.supports.subdirectories=true之后,即可将包含子目录的文件夹作为表或分区的数据目录,
查询的时候会递归遍历查询,但需要Hadoop的版本支持该功能才可以。
比如:hive0.13+hadoop0.20就不起作用。
Hive相关文章(持续更新):
—-Hive中的数据库(Database)和表(Table)
hive优化之——控制hive任务中的map数和reduce数
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » MapReduce和Hive支持递归子目录作为输入


