1. Hive是什么
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
这是来自官方的解释。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
先上一张经典的Hive架构图:
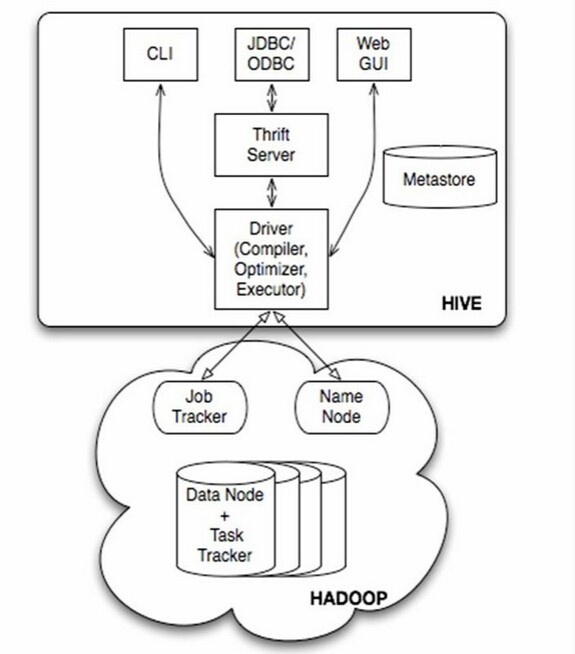
Hive架构图
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
在使用过程中,至需要将Hive看做是一个数据库就行,本身Hive也具备了数据库的很多特性和功能。
2. Hive擅长什么
Hive可以使用HQL(Hive SQL)很方便的完成对海量数据的统计汇总,即席查询和分析,除了很多内置的函数,还支持开发人员使用其他编程语言和脚本语言来自定义函数。
但是,由于Hadoop本身是一个批处理,高延迟的计算框架,Hive使用Hadoop作为执行引擎,自然也就有了批处理,高延迟的特点,在数据量很小的时候,Hive执行也需要消耗较长时间来完成,这时候,就显示不出它与Oracle,Mysql等传统数据库的优势。
此外,Hive对事物的支持不够好,原因是HDFS本身就设计为一次写入,多次读取的分布式存储系统,因此,不能使用Hive来完成诸如DELETE、UPDATE等在线事务处理的需求。
因此,Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
3. Hive的数据单元
- Databases:数据库。概念等同于关系型数据库的Schema,不多解释;
- Tables:表。概念等同于关系型数据库的表,不多解释;
- Partitions:分区。概念类似于关系型数据库的表分区,没有那么多分区类型,只支持固定分区,将同一组数据存放至一个固定的分区中。
- Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
4. Hive的数据类型
既然是被当做数据库来使用,除了数据单元,Hive当然也得有一些列的数据类型。这里先简单描述下,后续章节会有详细的介绍。
4.1 原始数据类型
- 整型
- TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。
- SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。
- INT– 整型,占用4个字节,存储范围-2147483648到2147483647。
- BIGINT– 长整型,占用8个字节,存储范围-2^63到2^63-1。
- 布尔型
- BOOLEAN — TRUE/FALSE
- 浮点型
- FLOAT– 单精度浮点数。
- DOUBLE– 双精度浮点数。
- 字符串型
- STRING– 不设定长度。
4.2 复合数据类型
- Structs:一组由任意数据类型组成的结构。比如,定义一个字段C的类型为STRUCT {a INT; b STRING},则可以使用a和C.b来获取其中的元素值;
- Maps:和Java中的Map没什么区别,就是存储K-V对的;
- Arrays:就是数组而已;
Hive相关文章(持续更新):
hive优化之——控制hive任务中的map数和reduce数
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » [一起学Hive]之一–Hive概述,Hive是什么
![[一起学Hive]之二十-自定义HiveServer2的用户安全认证](http://lxw1234.com/wp-content/themes/yusi1.0/timthumb.php?src=http://lxw1234.com/wp-content/uploads/2015/04/hive.png&h=110&w=185&q=90&zc=1&ct=1)