关键词:Mahout、K-Means、中文聚类
一、数据准备
版本说明
使用的Mahout版本为apache-mahout-distribution-0.10.1
使用的Hadoop版本为hadoop-2.3.0-cdh5.0.0
分词
使用爬虫对每个URL的标题、关键词、描述进行爬取,再用中文分词工具进行分词;
(中文分词工具:http://lxw1234.com/archives/2015/07/422.htm)
最后,每个URL的分词结果生成一个文本文件,以空格分隔,如:
url1.txt 四驱 旗舰版 多媒体 配置 参数 明细 url2.txt 代表 四宝 厨艺 视频 烹饪 四宝 如意 金砖 富贵 骑士 视频 url3.txt 体验 泰国 之旅 曼谷 高尔夫球场 球场 腾讯网 体验 泰国 之旅 曼谷 高尔夫球场 球场 ……
将文本文件转换成SequenceFile
将前面分词后的*.txt压缩上传至Hadoop网关机,解压到一个本地目录,如/tmp/txt/
使用Mahout命令将文本文件转换成SequenceFile,同时会将这么多小文本文件合并成一个Sequence:
cd $MAHOUT_HOME/bin export MAHOUT_LOCAL=true ./mahout seqdirectory -i file:///tmp/txt/ -o file:///home/lxw1234/txt-seq/ -c UTF-8 -chunk 64 -xm sequential
参数说明:
MAHOUT_LOCAL:指定Mahout是否以本地模式运行;如果该变量值为空,则表示在Hadoop上运行;
seqdirectory:Mahout自带的将文本文件转换成SequenceFile的命令;
-i:输入的文本文件目录;
-o:输出的SequenceFile目录;
-xm sequential:表示在本地执行,而不是用MapReduce执行;
-c UTF8:使用UTF8编码格式;
-chunk 64:64M一个chunk,也就是文件块block,应该和HDFS的块大小一致或成倍数关系;
执行成功后,在本地的/home/lxw1234/txt-seq/目录下生成了chunk-0文件,该文件格式为SequenceFile,可以用hadoop fs –text命令查看文件内容:
hadoop fs -text file:///home/lxw1234/txt-seq/chunk-0 | more /url809.txt 哈弗 精英 网易 精英 图片 哈弗 精英 哈弗 精英 车厢 内饰 哈弗 精英 细节 图片 哈弗 精英 经销商 图片 /url1369.txt 内饰 基本 不变 凤凰网 内饰 基本 不变 /url2625.txt 浪琴 按钮 致敬 历史 传统 /url2267.txt 一汽 马自达 阿特 少量 /url1831.txt 广州 的哥 收入 减半 租车公司 广州 的哥 收入 广州 的哥 离职 广州
将文本文件转换成SequenceFile也可以自己写程序来完成,Mahout也提供了相应的API。
将转换好的SequenceFile上传至HDFS
hadoop fs -mkdir /tmp/mahout/txt-seq/
hadoop fs -put /home/lxw1234/txt-seq/chunk-0 /tmp/mahout/txt-seq/
将SequenceFile上传至HDFS的/tmp/mahout/txt-seq/目录
二、解析SequenceFile,转换成向量表示
Mahout聚类算法使用向量空间(Vectors)作为数据数据。
接下来在Hadoop上,使用之前生成的SequenceFile,转换成向量表示:
使用命令:
cd $MAHOUT_HOME/bin export MAHOUT_LOCAL= export HADOOP_CLASSPATH=/home/lxw1234/apache-mahout-distribution-0.10.1/lib/lucene-analyzers-common-4.6.1.jar: /home/lxw1234/apache-mahout-distribution-0.10.1/lib/lucene-core-4.6.1.jar:$HADOOP_CLASSPATH ./mahout seq2sparse -i /tmp/mahout/txt-seq/ -o /tmp/mahout/txt-sparse -ow \ --weight tfidf --maxDFPercent 90 --namedVector \ -a org.apache.lucene.analysis.core.WhitespaceAnalyzer
参数说明:
MAHOUT_LOCAL:由于要在Hadoop上完成转换,因此,设该变量值为空;
HADOOP_CLASSPATH:加入需要的jar包到Hadoop的classpath,这两个jar包主要是mahout用来分词的;
seq2sparse:Mahout自带的解析向量的命令;
-i:输入的SequenceFile目录;
-o:输出目录;
-ow:当输出目录存在时,覆盖;
–weight tfidf:权重公式,可选的有tfidf和tf;
–maxDFPercent:过滤高频词,当DF值大于90%时候,将会被过滤掉;
–namedVector:生成的向量同时输出附加信息;
-a:指定分词器;由于Mahout本身对中文支持不好,前面已经将中文做好了分词,以空格分隔,这里指定的WhitespaceAnalyzer是以空格为分隔符的分词器;
其他可能有用的选项:
–minDF:最小DF阈值;
–minSupport:最小的支持度阈值,默认为2;
–maxNGramSize:是否创建ngram,默认为1。建议一般设定到2就够了;
–minLLR:The minimum Log Likelihood Ratio。默认为1.0。当设定了-ng > 1后,建议设置为较大的值,只过滤有意义的N-Gram。
–logNormalize:是否对输出向量做Log变换;
其他可输入命令./mahout seq2sparse –help 来查看。
在HDFS上查看解析后的结果:
hadoop fs -ls /tmp/mahout/txt-sparse Found 7 items /tmp/mahout/txt-sparse/df-count /tmp/mahout/txt-sparse/dictionary.file-0 /tmp/mahout/txt-sparse/frequency.file-0 /tmp/mahout/txt-sparse/tf-vectors /tmp/mahout/txt-sparse/tfidf-vectors /tmp/mahout/txt-sparse/tokenized-documents /tmp/mahout/txt-sparse/wordcount
各个文件的用途:
- file-0:文件。词文本 -> 词id(int)的映射。词转化为id,这是常见做法。
hadoop fs -text /tmp/mahout/txt-sparse/dictionary.file-0 | more 一发不可收拾 0 万元 1 两种 2 书店 3 书画 4 以上 5 低于 6 偷窥 7 全部 8 写真 9 前排 10
- df-count:目录。词id->文档频率(df);
hadoop fs -text /tmp/mahout/txt-sparse/df-count/* | more 0 1 15 2 30 4 45 7 60 2 75 1 90 6 105 1 120 5 135 1 150 2 165 2 180 2
- file:词id -> 文档集词频(cf)。
hadoop fs -text /tmp/mahout/txt-sparse/frequency.file-0 | more 0 1 15 2 30 4 45 7 60 2 75 1 90 6 105 1 120 5 135 1 150 2 165 2 180 2 195 470
- wordcount:目录。词文本 -> 文档集词频(cf),这个应该是各种过滤处理之前的信息。
hadoop fs -text /tmp/mahout/txt-sparse/wordcount/* | more 一发不可收拾 2 万元 220 两种 2 书店 2 书画 2 以上 2 低于 2 偷窥 3 全部 2 写真 3 前排 11
- tf-vectors、tfidf-vectors:目录。词向量,每篇文档一行,格式为{词id:特征值},其中特征值为tf或tfidf。采用了内置类型VectorWritable,需要用命令”mahout vectordump -i <path>”查看。
./mahout vectordump -i /tmp/mahout/txt-sparse/tf-vectors/ | more
{346:1.0,208:1.0,1532:1.0,668:1.0,238:1.0}
{390:2.0,367:1.0,844:2.0,692:2.0,952:1.0}
{1070:1.0}
{896:1.0,1341:1.0,434:1.0,153:6.0,195:1.0,838:1.0,1005:1.0,739:3.0,1025:1.0,1480:6.0,707:6.0}
{896:1.0,1341:1.0,838:1.0,153:6.0,195:1.0,1480:6.0,739:3.0,707:6.0}
{896:1.0,1341:1.0,838:1.0,153:6.0,195:1.0,1480:6.0,1005:1.0,739:3.0,707:6.0}
./mahout vectordump -i /tmp/mahout/txt-sparse/tfidf-vectors/ | more
{346:5.210176467895508,208:4.858778476715088,1532:7.749150276184082,668:6.545177459716797,238:6.075173854827881}
{390:7.129191875457764,367:7.749150276184082,844:11.532367706298828,692:11.532367706298828,952:7.749150276184082}
{1070:7.749150276184082}
{896:3.622015953063965,1341:2.697159767150879,434:7.2383246421813965,153:16.578933715820312,195:2.692904472351074,838:2.680246114730835,1005:3.03
6621570587158,739:4.602833271026611,1025:7.2383246421813965,1480:16.578933715820312,707:10.790275573730469}
{896:3.622015953063965,1341:2.697159767150879,838:2.680246114730835,153:16.578933715820312,195:2.692904472351074,1480:16.578933715820312,739:4.60
2833271026611,707:10.790275573730469}
- tokenized-documents:分词后的文档。
三、运行K-Means
cd $MAHOUT_HOME/bin export MAHOUT_LOCAL= ./mahout kmeans -i /tmp/mahout/txt-sparse/tfidf-vectors -c /tmp/mahout/txt-kmeans-clusters \ -o /tmp/mahout/txt-kmeans -k 30 \ -dm org.apache.mahout.common.distance.CosineDistanceMeasure -x 300 -ow --clustering
参数说明:
-i:输入为上面产出的tfidf向量。
-o:每一轮迭代的结果将输出在这里。
-k:几个簇,即最终聚为几个类别。
-c:若不设定k,则用这个目录里面的点,作为聚类中心点。否则,随机选择k个点,作为中心点。
-dm:距离公式,文本类型推荐用cosine距离。
-x:最大迭代次数。
–clustering:在mapreduce模式运行。
–convergenceDelta:迭代收敛阈值,默认0.5,对于Cosine来说略大。
输出1,初始随机选择的中心点;
hadoop fs -ls /tmp/mahout/txt-kmeans-clusters
Found 1 items
/tmp/mahout/txt-kmeans-clusters/part-randomSeed
输出2,聚类过程、结果:
hadoop fs -ls /tmp/mahout/txt-kmeans
Found 5 items
/tmp/mahout/txt-kmeans/_policy
/tmp/mahout/txt-kmeans/clusteredPoints
/tmp/mahout/txt-kmeans/clusters-0
/tmp/mahout/txt-kmeans/clusters-1
/tmp/mahout/txt-kmeans/clusters-2-final
其中,clusters-k(-final)为每次迭代后,簇的30个中心点的信息。
四、查看聚类结果
由于Mahout的clusterdump命令只能在本地运行,因此需要将聚类结果从HDFS下载到本地:
hadoop fs -get /tmp/mahout/txt-kmeans/ /home/lxw1234/
hadoop fs -get /tmp/mahout/txt-sparse/ /home/lxw1234/
运行命令:
cd $MAHOUT_HOME/bin export MAHOUT_LOCAL=true ./mahout clusterdump -i /home/lxw1234/txt-kmeans/clusters-2-final \ -d /home/lxw1234/txt-sparse/dictionary.file-0 -dt sequencefile \ -o /home/lxw1234/txt-kmeans-cluster-dump -n 50
参数说明:
-i:输入最终迭代生成的簇结果。
-d:使用 词 -> 词id 映射,使得我们输出结果中,可以直接显示每个簇,权重最高的词文本,而不是词id。
-dt:上面映射类型。
-o:最终产出目录。
-n:每个簇,只输出50个权重最高的词。
看看dump出来的结果:
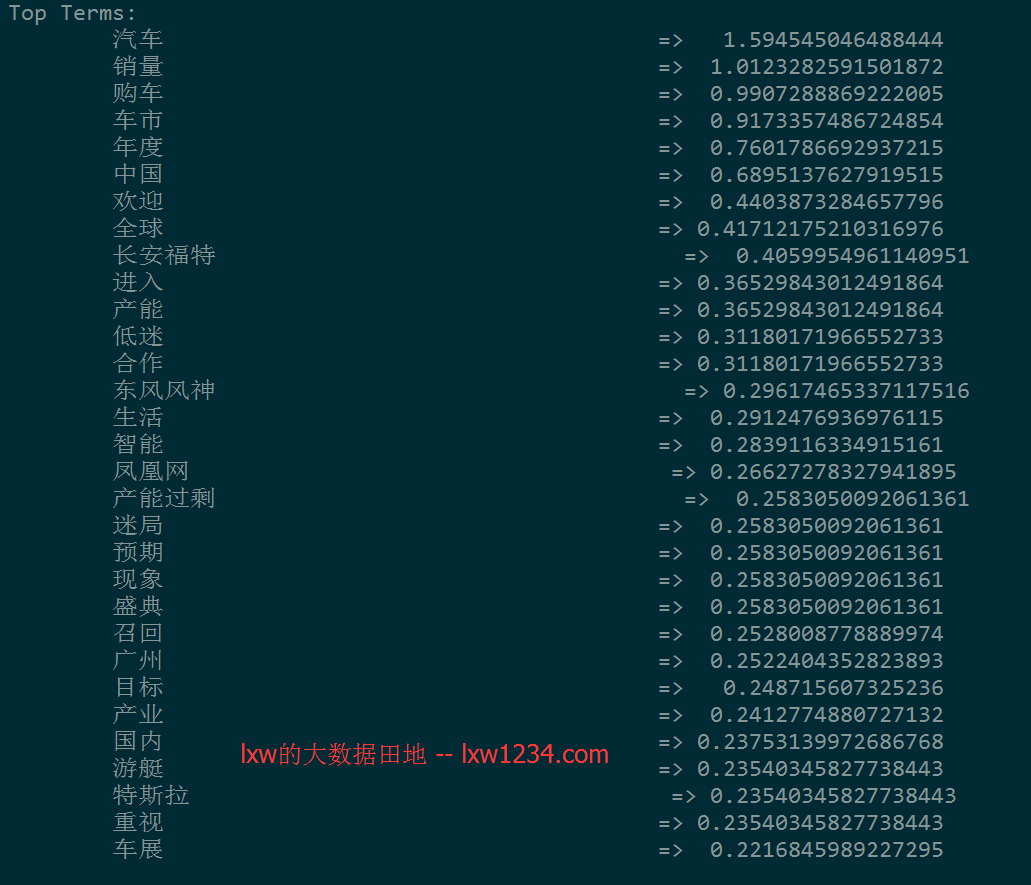
出来的聚类结果有些还可以,有些看上去有点不靠谱。
对Mahout的很多参数理解不够,还有待调整。
中文分词也是影响结果的重要因素。
本文只做测试性的试验。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Mahout使用K-Means进行中文文本聚类


