е…ій”®еӯ—пјҡHive udfгҖҒUDFгҖҒGenericUDF
HiveдёӯпјҢйҷӨдәҶжҸҗдҫӣдё°еҜҢзҡ„еҶ…зҪ®еҮҪж•°пјҲи§Ғ[дёҖиө·еӯҰHive]д№ӢдәҢвҖ“HiveеҮҪж•°еӨ§е…Ё-е®Ңж•ҙзүҲпјүд№ӢеӨ–пјҢиҝҳе…Ғи®ёз”ЁжҲ·дҪҝз”ЁJavaејҖеҸ‘иҮӘе®ҡд№үзҡ„UDFеҮҪж•°гҖӮ
ејҖеҸ‘иҮӘе®ҡд№үUDFеҮҪж•°жңүдёӨз§Қж–№ејҸпјҢдёҖдёӘжҳҜ继жүҝorg.apache.hadoop.hive.ql.exec.UDFпјҢеҸҰдёҖдёӘжҳҜ继жүҝorg.apache.hadoop.hive.ql.udf.generic.GenericUDFпјӣ
еҰӮжһңжҳҜй’ҲеҜ№з®ҖеҚ•зҡ„ж•°жҚ®зұ»еһӢпјҲжҜ”еҰӮStringгҖҒIntegerзӯүпјүеҸҜд»ҘдҪҝз”ЁUDFпјҢеҰӮжһңжҳҜй’ҲеҜ№еӨҚжқӮзҡ„ж•°жҚ®зұ»еһӢпјҲжҜ”еҰӮArrayгҖҒMapгҖҒStructзӯүпјүпјҢеҸҜд»ҘдҪҝз”ЁGenericUDFпјҢеҸҰеӨ–пјҢGenericUDFиҝҳеҸҜд»ҘеңЁеҮҪж•°ејҖе§Ӣд№ӢеүҚе’Ңз»“жқҹд№ӢеҗҺеҒҡдёҖдәӣеҲқе§ӢеҢ–е’Ңе…ій—ӯзҡ„еӨ„зҗҶж“ҚдҪңгҖӮ
UDF
дҪҝз”ЁUDFйқһеёёз®ҖеҚ•пјҢеҸӘйңҖиҰҒ继жүҝorg.apache.hadoop.hive.ql.exec.UDFпјҢ并е®ҡд№ү
public Object evaluate(Object args) {} ж–№жі•еҚіеҸҜгҖӮ
жҜ”еҰӮпјҢдёӢйқўзҡ„UDFеҮҪж•°е®һзҺ°дәҶеҜ№дёҖдёӘStringзұ»еһӢзҡ„еӯ—з¬ҰдёІеҸ–HashMD5пјҡ
package com.lxw1234.hive.udf;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.hadoop.hive.ql.exec.UDF;
public class HashMd5 extends UDF {
public String evaluate(String cookie) {
return MD5Hash.getMD5AsHex(Bytes.toBytes(cookie));
}
}
е°ҶдёҠйқўзҡ„HashMd5зұ»жү“жҲҗjarеҢ…пјҢudf.jar
дҪҝз”Ёж—¶еҖҷпјҢеңЁHiveе‘Ҫд»ӨиЎҢжү§иЎҢпјҡ
add jar file:///tmp/udf.jar; CREATE temporary function str_md5 as 'com.lxw1234.hive.udf.HashMd5'; select str_md5(вҖҳlxw1234.comвҖҷ) from dual;
GenericUDF
继жүҝorg.apache.hadoop.hive.ql.udf.generic.GenericUDFд№ӢеҗҺпјҢйңҖиҰҒйҮҚеҶҷеҮ дёӘйҮҚиҰҒзҡ„ж–№жі•пјҡ
public void configure(MapredContext context) {}
//еҸҜйҖүпјҢиҜҘж–№жі•дёӯеҸҜд»ҘйҖҡиҝҮcontext.getJobConf()иҺ·еҸ–jobжү§иЎҢж—¶еҖҷзҡ„Configurationпјӣ
//еҸҜд»ҘйҖҡиҝҮConfigurationдј йҖ’еҸӮж•°еҖј
public ObjectInspector initialize(ObjectInspector[] arguments)
//еҝ…йҖүпјҢиҜҘж–№жі•з”ЁдәҺеҮҪж•°еҲқе§ӢеҢ–ж“ҚдҪңпјҢ并е®ҡд№үеҮҪж•°зҡ„иҝ”еӣһеҖјзұ»еһӢпјӣ
//жҜ”еҰӮпјҢеңЁиҜҘж–№жі•дёӯеҸҜд»ҘеҲқе§ӢеҢ–еҜ№иұЎе®һдҫӢпјҢеҲқе§ӢеҢ–ж•°жҚ®еә“й“ҫжҺҘпјҢеҲқе§ӢеҢ–иҜ»еҸ–ж–Ү件зӯүпјӣ
public Object evaluate(DeferredObject[] args){}
//еҝ…йҖүпјҢеҮҪж•°еӨ„зҗҶзҡ„ж ёеҝғж–№жі•пјҢз”ЁйҖ”е’ҢUDFдёӯзҡ„evaluateдёҖж ·пјӣ
public String getDisplayString(String[] children)
//еҝ…йҖүпјҢжҳҫзӨәеҮҪж•°зҡ„её®еҠ©дҝЎжҒҜ
public void close(){}
//еҸҜйҖүпјҢmapе®ҢжҲҗеҗҺпјҢжү§иЎҢе…ій—ӯж“ҚдҪң
дёӢйқўзҡ„зЁӢеәҸе°ҶдёҖдёӘд»ҘйҖ—еҸ·еҲҶйҡ”зҡ„еӯ—з¬ҰдёІпјҢеҲҮеҲҶжҲҗListпјҢ并иҝ”еӣһпјҡ
package com.lxw1234.hive.udf;
import java.util.ArrayList;
import java.util.Date;
import org.apache.hadoop.hive.ql.exec.MapredContext;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* http://lxw1234.com
* lxwзҡ„еӨ§ж•°жҚ®з”°ең°
* @author lxw1234
* иҜҘеҮҪж•°з”ЁдәҺе°Ҷеӯ—з¬ҰдёІеҲҮеҲҶжҲҗListпјҢ并иҝ”еӣһ
*/
public class Lxw1234GenericUDF extends GenericUDF {
private static int mapTasks = 0;
private static String init = "";
private transient ArrayList ret = new ArrayList();
@Override
public void configure(MapredContext context) {
System.out.println(new Date() + "######## configure");
if(null != context) {
//д»ҺjobConfдёӯиҺ·еҸ–mapж•°
mapTasks = context.getJobConf().getNumMapTasks();
}
System.out.println(new Date() + "######## mapTasks [" + mapTasks + "] ..");
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments)
throws UDFArgumentException {
System.out.println(new Date() + "######## initialize");
//еҲқе§ӢеҢ–ж–Ү件系з»ҹпјҢеҸҜд»ҘеңЁиҝҷйҮҢеҲқе§ӢеҢ–иҜ»еҸ–ж–Ү件зӯү
init = "init";
//е®ҡд№үеҮҪж•°зҡ„иҝ”еӣһзұ»еһӢдёәjavaзҡ„List
ObjectInspector returnOI = PrimitiveObjectInspectorFactory
.getPrimitiveJavaObjectInspector(PrimitiveObjectInspector.PrimitiveCategory.STRING);
return ObjectInspectorFactory.getStandardListObjectInspector(returnOI);
}
@Override
public Object evaluate(DeferredObject[] args) throws HiveException {
ret.clear();
if(args.length < 1) return ret;
//иҺ·еҸ–第дёҖдёӘеҸӮж•°
String str = args[0].get().toString();
String[] s = str.split(",",-1);
for(String word : s) {
ret.add(word);
}
return ret;
}
@Override
public String getDisplayString(String[] children) {
return "Usage: Lxw1234GenericUDF(String str)";
}
}
е…¶дёӯпјҢеңЁconfigureж–№жі•дёӯпјҢиҺ·еҸ–дәҶжң¬ж¬Ўд»»еҠЎзҡ„Map Taskж•°зӣ®пјӣ
еңЁinitializeж–№жі•дёӯпјҢеҲқе§ӢеҢ–дәҶдёҖдёӘеҸҳйҮҸinitпјҢ并е®ҡд№үдәҶиҝ”еӣһзұ»еһӢдёәjavaзҡ„Listзұ»еһӢпјӣ
getDisplayStringж–№жі•дёӯжҳҫзӨәеҮҪж•°зҡ„з”Ёжі•пјӣ
evaluateжҳҜж ёеҝғзҡ„йҖ»иҫ‘еӨ„зҗҶпјӣ
йңҖиҰҒзү№еҲ«жіЁж„Ҹзҡ„жҳҜпјҢconfigureж–№жі•пјҢвҖңThis is only called in runtime of MapRedTaskвҖқ,иҜҘж–№жі•еҸӘжңүеңЁиҝҗиЎҢmap taskж—¶еҖҷжүҚиў«жү§иЎҢгҖӮе®ғе’Ңinitializeз”Ёжі•дёҚдёҖж ·пјҢеҰӮжһңеңЁinitializeж—¶еҖҷеҺ»дҪҝз”ЁMapredContextпјҢеҲҷдјҡжҠҘNullпјҢеӣ дёәжӯӨж—¶MapredContextиҝҳжҳҜNullгҖӮ
дёҠйқўзҡ„еҮҪж•°жү§иЎҢеҗҺпјҢеңЁMapReduceзҡ„ж—Ҙеҝ—дёӯжү“еҚ°еҮәдәҶд»ҘдёӢеҶ…е®№пјҡ
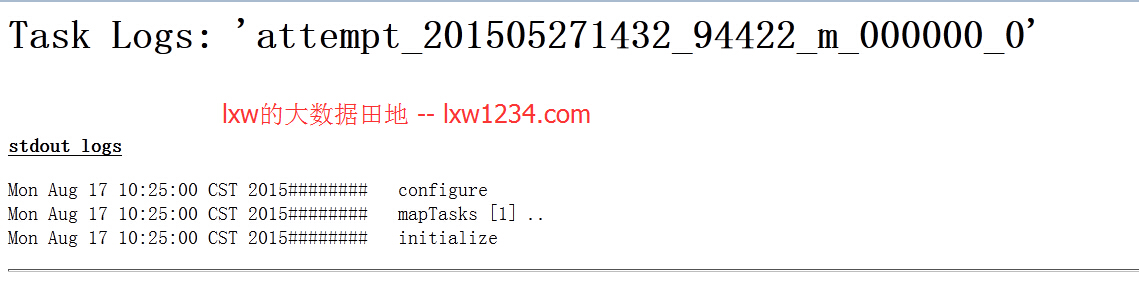
еҚіеңЁMapReduceйҳ¶ж®өпјҢGenericUDFеҮ дёӘж–№жі•зҡ„жү§иЎҢйЎәеәҸдёәпјҡ
configure–>initialize–>evaluate–>close
Hiveзӣёе…іж–Үз« пјҲжҢҒз»ӯжӣҙж–°пјүпјҡ
вҖ”-HiveжҰӮиҝ°пјҢHiveжҳҜд»Җд№Ҳ
вҖ”-HiveеҮҪж•°еӨ§е…Ё-е®Ңж•ҙзүҲ
вҖ”-Hiveдёӯзҡ„ж•°жҚ®еә“(Database)е’ҢиЎЁ(Table)
вҖ”-HiveдёӯJoinзҡ„еҺҹзҗҶе’ҢжңәеҲ¶
вҖ”-HiveдёӯJoinзҡ„зұ»еһӢе’Ңз”Ёжі•
вҖ”-Hiveж•ҙеҗҲHBaseпјҢж“ҚдҪңHBaseиЎЁ
вҖ”-Hiveзҡ„е…ғж•°жҚ®иЎЁз»“жһ„иҜҰи§Ј
вҖ”-еҲҶжһҗHiveиЎЁе’ҢеҲҶеҢәзҡ„з»ҹи®ЎдҝЎжҒҜ(Statistics)
вҖ”-Hiveзҡ„WEBйЎөйқўжҺҘеҸЈ-HWI
вҖ”-д»ҺHiveиЎЁдёӯиҝӣиЎҢж•°жҚ®жҠҪж ·-Sampling
hiveдјҳеҢ–д№ӢвҖ”вҖ”жҺ§еҲ¶hiveд»»еҠЎдёӯзҡ„mapж•°е’Ңreduceж•°
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » [дёҖиө·еӯҰHive]д№ӢеҚҒе…«-Hive UDFејҖеҸ‘

