关键字:SparkSQL on Yarn、SparkSQL Hive On Yarn
前面的文章介绍过如何向Yarn中提交Spark应用程序《Spark On Yarn:提交Spark应用程序到Yarn》,
以及在Yarn上运行spark-shell和spark-sql命令行《在Yarn上运行spark-shell和spark-sql命令行》。
本文将介绍以yarn-cluster模式运行SparkSQL应用程序,访问和操作Hive中的表,这个和在Yarn上运行普通的Spark应用程序有所不同,重点是需要将Hive的依赖包以及配置文件传递到Driver和Executor上,因为在yarn-cluster模式下,Driver和Executor都是由Yarn和分配的。
下面的代码完成了以下功能:
1. 在Hive的数据库liuxiaowen中,创建目标表lxw1234;
2. 从已存在的源表lxw_cate_id插入数据到目标表lxw1234;
3. 统计目标表lxw1234的记录数;
4. 统计源表lxw_cate_id的记录数;
5. 打印目标表lxw1234的limit 5记录;
package com.lxw1234.sparksql;
import java.io.File
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
import org.apache.spark.sql.hive.HiveContext
/**
* lxw的大数据田地 -- lxw1234.com
*/
object SparkSQLHiveOnYarn {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("SparkSQLHiveOnYarn")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
import hiveContext.implicits._
import hiveContext.sql
//在数据库liuxiaowen中创建表 lxw1234
println("create table lxw1234 .. ")
sql("USE liuxiaowen")
sql("CREATE TABLE IF NOT EXISTS lxw1234 (cate STRING, cate_id INT) STORED AS TEXTFILE")
//从已存在的源表lxw_cate_id插入数据到目标表lxw1234
println("insert data into table lxw1234 .. ")
sql("INSERT OVERWRITE TABLE lxw1234 select cate,cate_id FROM lxw_cate_id")
//目标表lxw1234的记录数
println("Result of 'select count(1) from lxw1234': ")
val count = sql("SELECT COUNT(1) FROM lxw1234").collect().head.getLong(0)
println(s"lxw1234 COUNT(1): $count")
//源表lxw_cate_id的记录数
println("Result of 'select count(1) from lxw_cate_id': ")
val count2 = sql("SELECT COUNT(1) FROM lxw_cate_id").collect().head.getLong(0)
println(s"lxw_cate_id COUNT(1): $count2")
//目标表lxw1234的limit 5记录
println("Result of 'SELECT * from lxw1234 limit 10': ")
sql("SELECT * FROM lxw1234 limit 5").collect().foreach(println)
//sleep 10分钟,为了从WEB界面上看日志
Thread.sleep(600000)
sc.stop()
}
}
将上面的程序打包成sparksql.jar,并上传至Spark和Hadoop所在的客户端机器上。
运行下面的命令,使用spark-submit将该SparkSQL应用程序提交到Yarn上:
cd $SPARK_HOME/bin ./spark-submit \ --class com.lxw1234.sparksql.SparkSQLHiveOnYarn \ --master yarn-cluster \ --driver-memory 4G \ --driver-java-options "-XX:MaxPermSize=1G" \ --verbose \ --files $HIVE_HOME/conf/hive-site.xml \ --jars $HIVE_HOME/lib/mysql-connector-java-5.1.15-bin.jar,$SPARK_HOME/lib/datanucleus-api-jdo-3.2.6.jar,$SPARK_HOME/lib/datanucleus-core-3.2.10.jar,$SPARK_HOME/lib/datanucleus-rdbms-3.2.9.jar,$SPARK_HOME/lib/guava-12.0.1.jar \ /tmp/sparksql.jar
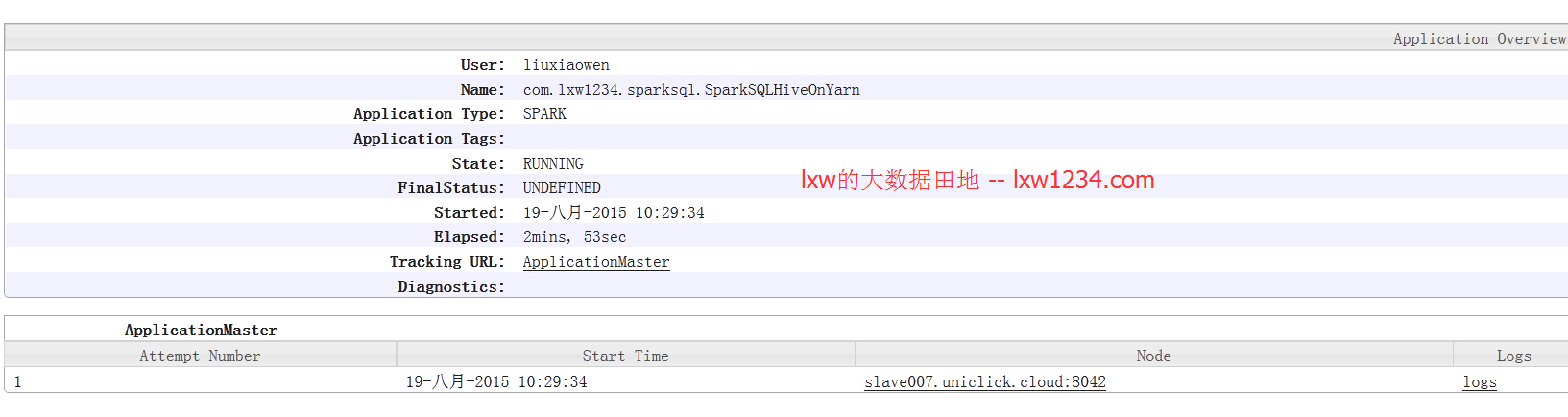
提交运行之后,在Yarn上可以看到该application:
点击logs,进入stdout,可以查看程序的标准输出:
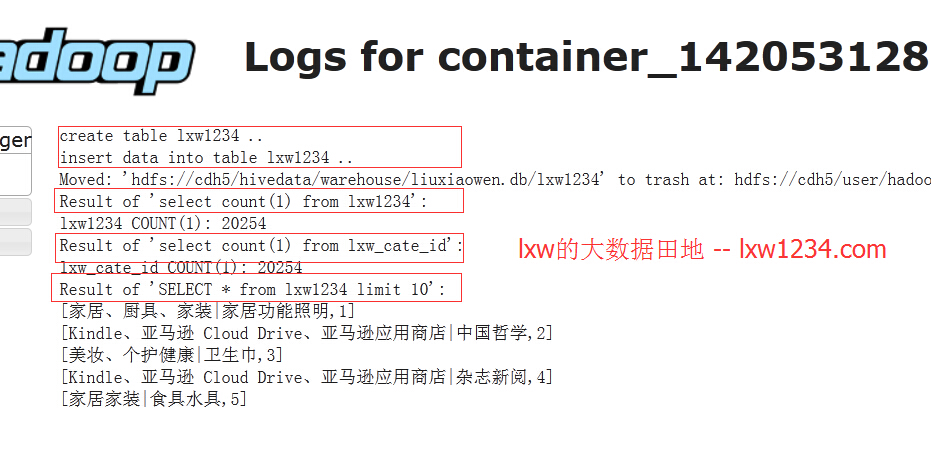
从日志中看到,程序已经成功执行。
点击ApplicationMaster的WEB URL,进入SparkMaster的WEB界面:
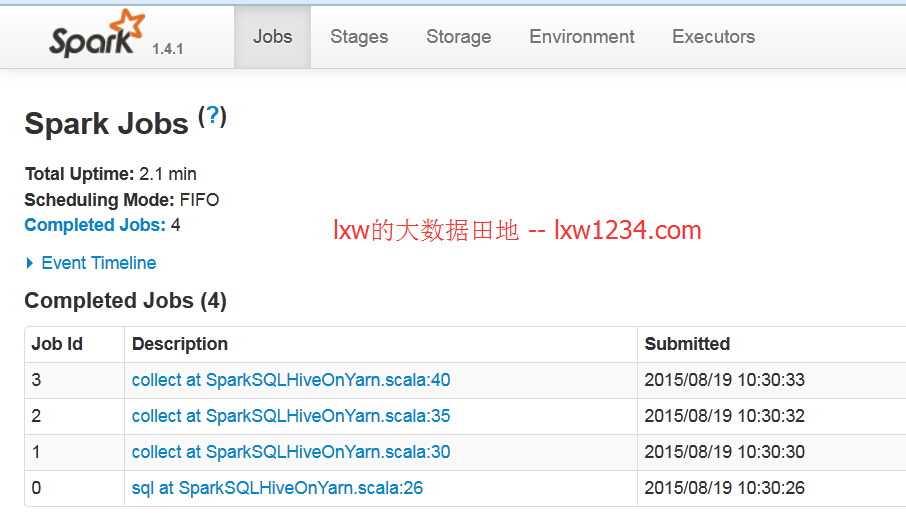
可以看到,每句SQL是一个Job.
在Hive中查看表lxw1234的数据:

没问题,和日志中打印出来的一样。
说明一下上面使用spark-submit提交的命令:
–master yarn-cluster //指定以yarn-cluster模式运行,关于yarn-cluster和yarn-client的区别,在之前的文章中提到过
–driver-memory 4G //指定Driver使用的内存为4G,
//如果太小的话,会报错:Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread “Driver”
–driver-java-options “-XX:MaxPermSize=1G” //指定Driver程序JVM参数
–files $HIVE_HOME/conf/hive-site.xml //将Hive的配置文件添加到Driver和Executor的classpath中
–jars $HIVE_HOME/lib/mysql-connector-java-5.1.15-bin.jar,…. //将Hive依赖的jar包添加到Driver和Executor的classpath中
//需要依赖的jar包有:mysql-connector-java-5.1.15-bin.jar、datanucleus-api-jdo-3.2.6.jar、datanucleus-core-3.2.10.jar、datanucleus-rdbms-3.2.9.jar、guava-12.0.1.jar
另外还有一点要注意:由于Driver和Executor需要访问Hive的元数据库,而Driver和Executor被分配到哪台机器上是不固定的,所以需要授权,使集群上所有机器都有操作Hive元数据库的权限。
您可以关注 我的博客,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。


