е…ій”®еӯ—пјҡHadoop еӨҡз”ЁжҲ·гҖҒиө„жәҗгҖҒfair scheduler
еңЁдёҖдёӘе…¬еҸёеҶ…йғЁзҡ„Hadoop YarnйӣҶзҫӨпјҢиӮҜе®ҡдјҡиў«еӨҡдёӘдёҡеҠЎгҖҒеӨҡдёӘз”ЁжҲ·еҗҢж—¶дҪҝз”ЁпјҢе…ұдә«Yarnзҡ„иө„жәҗпјҢеҰӮжһңдёҚеҒҡиө„жәҗзҡ„з®ЎзҗҶдёҺ规еҲ’пјҢйӮЈд№Ҳж•ҙдёӘYarnзҡ„иө„жәҗеҫҲе®№жҳ“иў«жҹҗдёҖдёӘз”ЁжҲ·жҸҗдәӨзҡ„ApplicationеҚ ж»ЎпјҢе…¶е®ғд»»еҠЎеҸӘиғҪзӯүеҫ…пјҢиҝҷз§ҚеҪ“然еҫҲдёҚеҗҲзҗҶпјҢжҲ‘们еёҢжңӣжҜҸдёӘдёҡеҠЎйғҪжңүеұһдәҺиҮӘе·ұзҡ„зү№е®ҡиө„жәҗжқҘиҝҗиЎҢMapReduceд»»еҠЎпјҢHadoopдёӯжҸҗдҫӣзҡ„е…¬е№іи°ғеәҰеҷЁ–Fair SchedulerпјҢе°ұеҸҜд»Ҙж»Ўи¶іиҝҷз§ҚйңҖжұӮгҖӮ
Fair Schedulerе°Ҷж•ҙдёӘYarnзҡ„еҸҜз”Ёиө„жәҗеҲ’еҲҶжҲҗеӨҡдёӘиө„жәҗжұ пјҢжҜҸдёӘиө„жәҗжұ дёӯеҸҜд»Ҙй…ҚзҪ®жңҖе°Ҹе’ҢжңҖеӨ§зҡ„еҸҜз”Ёиө„жәҗпјҲеҶ…еӯҳе’ҢCPUпјүгҖҒжңҖеӨ§еҸҜеҗҢж—¶иҝҗиЎҢApplicationж•°йҮҸгҖҒжқғйҮҚгҖҒд»ҘеҸҠеҸҜд»ҘжҸҗдәӨе’Ңз®ЎзҗҶApplicationзҡ„з”ЁжҲ·зӯүгҖӮ
ж №жҚ®з”ЁжҲ·еҗҚеҲҶй…Қиө„жәҗжұ
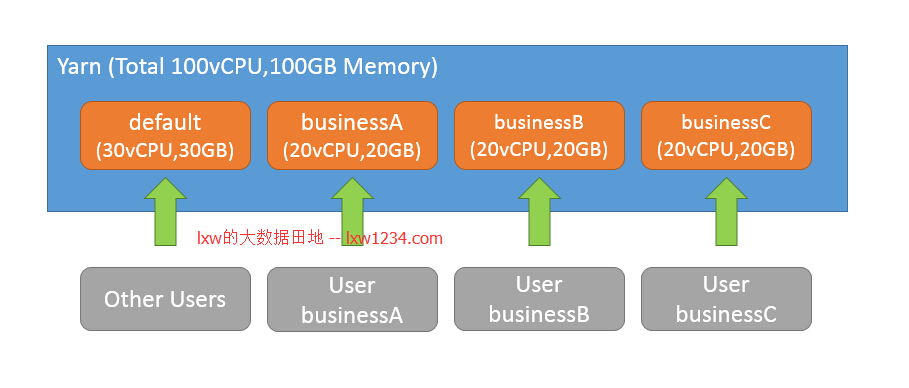
еҰӮеӣҫжүҖзӨәпјҢеҒҮи®ҫж•ҙдёӘYarnйӣҶзҫӨзҡ„еҸҜз”Ёиө„жәҗдёә100vCPUпјҢ100GBеҶ…еӯҳпјҢзҺ°еңЁдёә3дёӘдёҡеҠЎеҗ„иҮӘ规еҲ’дёҖдёӘиө„жәҗжұ пјҢеҸҰеӨ–пјҢ规еҲ’дёҖдёӘdefaultиө„жәҗжұ пјҢз”ЁдәҺиҝҗиЎҢе…¶д»–з”ЁжҲ·е’ҢдёҡеҠЎжҸҗдәӨзҡ„д»»еҠЎгҖӮеҰӮжһңжІЎжңүеңЁд»»еҠЎдёӯжҢҮе®ҡиө„жәҗжұ пјҲйҖҡиҝҮеҸӮж•°mapreduce.job.queuenameпјүпјҢйӮЈд№ҲеҸҜд»Ҙй…ҚзҪ®дҪҝз”Ёз”ЁжҲ·еҗҚдҪңдёәиө„жәҗжұ еҗҚз§°жқҘжҸҗдәӨд»»еҠЎпјҢеҚіз”ЁжҲ·businessAжҸҗдәӨзҡ„д»»еҠЎиў«еҲҶй…ҚеҲ°иө„жәҗжұ businessAдёӯпјҢз”ЁжҲ·businessCжҸҗдәӨзҡ„д»»еҠЎиў«еҲҶй…ҚеҲ°иө„жәҗжұ businessCдёӯгҖӮйҷӨдәҶй…ҚзҪ®зҡ„еӣәе®ҡз”ЁжҲ·пјҢе…¶д»–з”ЁжҲ·жҸҗдәӨзҡ„д»»еҠЎе°Ҷдјҡиў«еҲҶй…ҚеҲ°иө„жәҗжұ defaultдёӯгҖӮ
иҝҷйҮҢзҡ„з”ЁжҲ·еҗҚпјҢе°ұжҳҜжҸҗдәӨApplicationжүҖдҪҝз”Ёзҡ„Linux/Unixз”ЁжҲ·еҗҚгҖӮ
еҸҰеӨ–пјҢжҜҸдёӘиө„жәҗжұ еҸҜд»Ҙй…ҚзҪ®е…Ғи®ёжҸҗдәӨд»»еҠЎзҡ„з”ЁжҲ·еҗҚпјҢжҜ”еҰӮпјҢеңЁиө„жәҗжұ businessAдёӯй…ҚзҪ®дәҶе…Ғи®ёз”ЁжҲ·businessAе’Ңз”ЁжҲ·lxw1234жҸҗдәӨд»»еҠЎпјҢеҰӮжһңдҪҝз”Ёз”ЁжҲ·lxw1234жҸҗдәӨд»»еҠЎпјҢ并且еңЁд»»еҠЎдёӯжҢҮе®ҡдәҶиө„жәҗжұ дёәbusinessAпјҢйӮЈд№Ҳд№ҹеҸҜд»ҘжӯЈеёёжҸҗдәӨеҲ°иө„жәҗжұ businessAдёӯгҖӮ
ж №жҚ®жқғйҮҚиҺ·еҫ—йўқеӨ–зҡ„з©әй—Іиө„жәҗ
еңЁжҜҸдёӘиө„жәҗжұ зҡ„й…ҚзҪ®йЎ№дёӯпјҢжңүдёӘweightеұһжҖ§пјҲй»ҳи®Өдёә1пјүпјҢж Үи®°дәҶиө„жәҗжұ зҡ„жқғйҮҚпјҢеҪ“иө„жәҗжұ дёӯжңүд»»еҠЎзӯүеҫ…пјҢ并且йӣҶзҫӨдёӯжңүз©әй—Іиө„жәҗж—¶еҖҷпјҢжҜҸдёӘиө„жәҗжұ еҸҜд»Ҙж №жҚ®жқғйҮҚиҺ·еҫ—дёҚеҗҢжҜ”дҫӢзҡ„йӣҶзҫӨз©әй—Іиө„жәҗгҖӮ
жҜ”еҰӮпјҢиө„жәҗжұ businessAе’ҢbusinessBзҡ„жқғйҮҚеҲҶеҲ«дёә2е’Ң1пјҢиҝҷдёӨдёӘиө„жәҗжұ дёӯзҡ„иө„жәҗйғҪе·Із»Ҹи·‘ж»ЎдәҶпјҢ并且иҝҳжңүд»»еҠЎеңЁжҺ’йҳҹпјҢжӯӨж—¶йӣҶзҫӨдёӯжңү30дёӘContainerзҡ„з©әй—Іиө„жәҗпјҢйӮЈд№ҲпјҢbusinessAе°ҶдјҡйўқеӨ–иҺ·еҫ—20дёӘContainerзҡ„иө„жәҗпјҢbusinessBдјҡйўқеӨ–иҺ·еҫ—10дёӘContainerзҡ„иө„жәҗгҖӮ
жңҖе°Ҹиө„жәҗдҝқиҜҒ
еңЁжҜҸдёӘиө„жәҗжұ дёӯпјҢе…Ғи®ёй…ҚзҪ®иҜҘиө„жәҗжұ зҡ„жңҖе°Ҹиө„жәҗпјҢиҝҷжҳҜдёәдәҶйҳІжӯўжҠҠз©әй—Іиө„жәҗе…ұдә«еҮәеҺ»иҝҳжңӘеӣһ收зҡ„ж—¶еҖҷпјҢиҜҘиө„жәҗжұ жңүд»»еҠЎйңҖиҰҒиҝҗиЎҢж—¶еҖҷзҡ„иө„жәҗдҝқиҜҒгҖӮ
жҜ”еҰӮпјҢиө„жәҗжұ businessAдёӯй…ҚзҪ®дәҶжңҖе°Ҹиө„жәҗдёәпјҲ5vCPUпјҢ5GBпјүпјҢйӮЈд№ҲеҚідҪҝжІЎжңүд»»еҠЎиҝҗиЎҢпјҢYarnд№ҹдјҡдёәиө„жәҗжұ businessAйў„з•ҷеҮәжңҖе°Ҹиө„жәҗпјҢдёҖж—Ұжңүд»»еҠЎйңҖиҰҒиҝҗиЎҢпјҢиҖҢйӣҶзҫӨдёӯе·Із»ҸжІЎжңүе…¶д»–з©әй—Іиө„жәҗзҡ„ж—¶еҖҷпјҢиҝҷдёӘжңҖе°Ҹиө„жәҗд№ҹеҸҜд»ҘдҝқиҜҒиө„жәҗжұ businessAдёӯзҡ„д»»еҠЎеҸҜд»Ҙе…ҲиҝҗиЎҢиө·жқҘпјҢйҡҸеҗҺеҶҚд»ҺйӣҶзҫӨдёӯиҺ·еҸ–иө„жәҗгҖӮ
еҠЁжҖҒжӣҙж–°иө„жәҗй…Қйўқ
Fair SchedulerйҷӨдәҶйңҖиҰҒеңЁyarn-site.xmlж–Ү件дёӯеҗҜз”Ёе’Ңй…ҚзҪ®д№ӢеӨ–пјҢиҝҳйңҖиҰҒдёҖдёӘXMLж–Ү件жқҘй…ҚзҪ®иө„жәҗжұ д»ҘеҸҠй…ҚйўқпјҢиҖҢиҜҘXMLдёӯжҜҸдёӘиө„жәҗжұ зҡ„й…ҚйўқеҸҜд»ҘеҠЁжҖҒжӣҙж–°пјҢд№ӢеҗҺдҪҝз”Ёе‘Ҫд»Өпјҡyarn rmadmin вҖ“refreshQueues жқҘдҪҝеҫ—е…¶з”ҹж•ҲеҚіеҸҜпјҢдёҚз”ЁйҮҚеҗҜYarnйӣҶзҫӨгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡеҠЁжҖҒжӣҙж–°еҸӘж”ҜжҢҒдҝ®ж”№иө„жәҗжұ й…ҚйўқпјҢеҰӮжһңжҳҜж–°еўһжҲ–еҮҸе°‘иө„жәҗжұ пјҢеҲҷйңҖиҰҒйҮҚеҗҜYarnйӣҶзҫӨгҖӮ
Fair Schedulerй…ҚзҪ®зӨәдҫӢ
д»ҘдёҠйқўеӣҫдёӯжүҖзӨәзҡ„дёҡеҠЎеңәжҷҜдёәдҫӢгҖӮ
yarn-site.xmlдёӯзҡ„й…ҚзҪ®пјҡ
<!– scheduler start –>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/etc/hadoop/conf/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>default is True</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>default is True</description>
</property>
<!– scheduler end –>
- yarn.resourcemanager.scheduler.class
й…ҚзҪ®YarnдҪҝз”Ёзҡ„и°ғеәҰеҷЁжҸ’件зұ»еҗҚпјӣ
Fair SchedulerеҜ№еә”зҡ„жҳҜпјҡ
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
- yarn.scheduler.fair.allocation.file
й…ҚзҪ®иө„жәҗжұ д»ҘеҸҠе…¶еұһжҖ§й…Қйўқзҡ„XMLж–Ү件и·Ҝеҫ„пјҲжң¬ең°и·Ҝеҫ„пјүпјӣ
- yarn.scheduler.fair.preemption
ејҖеҗҜиө„жәҗжҠўеҚ гҖӮ
- yarn.scheduler.fair.user-as-default-queue
и®ҫзҪ®жҲҗtrueпјҢеҪ“д»»еҠЎдёӯжңӘжҢҮе®ҡиө„жәҗжұ зҡ„ж—¶еҖҷпјҢе°Ҷд»Ҙз”ЁжҲ·еҗҚдҪңдёәиө„жәҗжұ еҗҚгҖӮиҝҷдёӘй…ҚзҪ®е°ұе®һзҺ°дәҶж №жҚ®з”ЁжҲ·еҗҚиҮӘеҠЁеҲҶй…Қиө„жәҗжұ гҖӮ
- yarn.scheduler.fair.allow-undeclared-pools
жҳҜеҗҰе…Ғи®ёеҲӣе»әжңӘе®ҡд№үзҡ„иө„жәҗжұ гҖӮ
еҰӮжһңи®ҫзҪ®жҲҗtrueпјҢyarnе°ҶдјҡиҮӘеҠЁеҲӣе»әд»»еҠЎдёӯжҢҮе®ҡзҡ„жңӘе®ҡд№үиҝҮзҡ„иө„жәҗжұ гҖӮи®ҫзҪ®жҲҗfalseд№ӢеҗҺпјҢд»»еҠЎдёӯжҢҮе®ҡзҡ„жңӘе®ҡд№үзҡ„иө„жәҗжұ е°Ҷж— ж•ҲпјҢиҜҘд»»еҠЎдјҡиў«еҲҶй…ҚеҲ°defaultиө„жәҗжұ дёӯгҖӮ
fair-scheduler.xmlдёӯзҡ„й…ҚзҪ®:
<?xml version=”1.0″?>
<allocations>
<!– users max running apps –>
<userMaxAppsDefault>30</userMaxAppsDefault>
<!– queues –>
<queue name=”root”>
<minResources>51200mb,50vcores</minResources>
<maxResources>102400mb,100vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<weight>1.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name=”default”>
<minResources>10240mb,10vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name=”businessA”>
<minResources>5120mb,5vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<aclSubmitApps>businessA,lxw1234 group_businessA,group_lxw1234</aclSubmitApps>
<aclAdministerApps>businessA,hadoop group_businessA,supergroup</aclAdministerApps>
</queue>
<queue name=”businessB”>
<minResources>5120mb,5vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>businessB group_businessA</aclSubmitApps>
<aclAdministerApps>businessA,hadoop group_businessA,supergroup</aclAdministerApps>
</queue>
<queue name=”businessC”>
<minResources>5120mb,5vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>businessC group_businessC</aclSubmitApps>
<aclAdministerApps>businessC,hadoop group_businessC,supergroup</aclAdministerApps>
</queue>
</queue>
</allocations>
- minResources
жңҖе°Ҹиө„жәҗ
- maxResources
жңҖеӨ§иө„жәҗ
- maxRunningApps
жңҖеӨ§еҗҢж—¶иҝҗиЎҢapplicationж•°йҮҸ
- weight
иө„жәҗжұ жқғйҮҚ
- aclSubmitApps
е…Ғи®ёжҸҗдәӨд»»еҠЎзҡ„з”ЁжҲ·еҗҚе’Ңз»„пјӣ
ж јејҸдёәпјҡ з”ЁжҲ·еҗҚ з”ЁжҲ·з»„
еҪ“жңүеӨҡдёӘз”ЁжҲ·ж—¶еҖҷпјҢж јејҸдёәпјҡз”ЁжҲ·еҗҚ1,з”ЁжҲ·еҗҚ2 з”ЁжҲ·еҗҚ1жүҖеұһз»„,з”ЁжҲ·еҗҚ2жүҖеұһз»„
- aclAdministerApps
е…Ғи®ёз®ЎзҗҶд»»еҠЎзҡ„з”ЁжҲ·еҗҚе’Ңз»„пјӣ
ж јејҸеҗҢдёҠгҖӮ
В В В В В В Fair Scheduerеҗ„иө„жәҗжұ й…ҚзҪ®еҸҠдҪҝз”Ёжғ…еҶөпјҢеңЁResourceManagerзҡ„WEBзӣ‘жҺ§йЎөйқўдёҠд№ҹеҸҜд»ҘзңӢеҲ°пјҡ
жӮЁеҸҜд»Ҙе…іжіЁ lxwзҡ„еӨ§ж•°жҚ®з”°ең° пјҢжҲ–иҖ… еҠ е…ҘйӮ®д»¶еҲ—иЎЁ пјҢйҡҸж—¶жҺҘ收еҚҡе®ўжӣҙж–°зҡ„йҖҡзҹҘйӮ®д»¶гҖӮ
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » HadoopеӨҡз”ЁжҲ·иө„жәҗз®ЎзҗҶ–Fair Schedulerд»Ӣз»ҚдёҺй…ҚзҪ®

