е…ій”®еӯ—пјҡKafkaеҲҶеҢәгҖҒPartition
KafkaдёӯеҸҜд»Ҙе°ҶTopicд»Һзү©зҗҶдёҠеҲ’еҲҶжҲҗдёҖдёӘжҲ–еӨҡдёӘеҲҶеҢәпјҲPartitionпјүпјҢжҜҸдёӘеҲҶеҢәеңЁзү©зҗҶдёҠеҜ№еә”дёҖдёӘж–Ү件еӨ№пјҢд»ҘвҖқtopicName_partitionIndexвҖқзҡ„е‘ҪеҗҚж–№ејҸе‘ҪеҗҚпјҢиҜҘж–Ү件еӨ№дёӢеӯҳеӮЁиҝҷдёӘеҲҶеҢәзҡ„жүҖжңүж¶ҲжҒҜ(.log)е’Ңзҙўеј•ж–Ү件(.index)пјҢиҝҷдҪҝеҫ—Kafkaзҡ„еҗһеҗҗзҺҮеҸҜд»Ҙж°ҙе№іжү©еұ•гҖӮ
з”ҹдә§иҖ…еңЁз”ҹдә§ж•°жҚ®зҡ„ж—¶еҖҷпјҢеҸҜд»ҘдёәжҜҸжқЎж¶ҲжҒҜжҢҮе®ҡKeyпјҢиҝҷж ·ж¶ҲжҒҜиў«еҸ‘йҖҒеҲ°brokerж—¶пјҢдјҡж №жҚ®еҲҶеҢә规еҲҷйҖүжӢ©иў«еӯҳеӮЁеҲ°е“ӘдёҖдёӘеҲҶеҢәдёӯпјҢеҰӮжһңеҲҶеҢә规еҲҷи®ҫзҪ®зҡ„еҗҲзҗҶпјҢйӮЈд№ҲжүҖжңүзҡ„ж¶ҲжҒҜе°Ҷдјҡиў«еқҮеҢҖзҡ„еҲҶеёғеҲ°дёҚеҗҢзҡ„еҲҶеҢәдёӯпјҢиҝҷж ·е°ұе®һзҺ°дәҶиҙҹиҪҪеқҮиЎЎе’Ңж°ҙе№іжү©еұ•гҖӮеҸҰеӨ–пјҢеңЁж¶Ҳиҙ№иҖ…з«ҜпјҢеҗҢдёҖдёӘж¶Ҳиҙ№з»„еҸҜд»ҘеӨҡзәҝзЁӢ并еҸ‘зҡ„д»ҺеӨҡдёӘеҲҶеҢәдёӯеҗҢж—¶ж¶Ҳиҙ№ж•°жҚ®пјҲеҗҺз»ӯе°Ҷд»Ӣз»Қиҝҷеқ—пјүгҖӮ
дёҠйқўжүҖиҜҙзҡ„еҲҶеҢә规еҲҷпјҢжҳҜе®һзҺ°дәҶkafka.producer.PartitionerжҺҘеҸЈзҡ„зұ»пјҢеҸҜд»ҘиҮӘе®ҡд№үгҖӮжҜ”еҰӮпјҢдёӢйқўзҡ„д»Јз ҒSimplePartitionerдёӯпјҢе°Ҷж¶ҲжҒҜзҡ„keyеҒҡдәҶhashcodeпјҢ然еҗҺе’ҢеҲҶеҢәж•°пјҲnumPartitionsпјүеҒҡжЁЎиҝҗз®—пјҢдҪҝеҫ—жҜҸдёҖдёӘkeyйғҪеҸҜд»ҘеҲҶеёғеҲ°дёҖдёӘеҲҶеҢәдёӯпјҡ
package com.lxw1234.kafka;
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class SimplePartitioner implements Partitioner {
public SimplePartitioner (VerifiableProperties props) {
}
@Override
public int partition(Object key, int numPartitions) {
int partition = 0;
String k = (String)key;
partition = Math.abs(k.hashCode()) % numPartitions;
return partition;
}
}
еңЁеҲӣе»әTopicж—¶еҖҷеҸҜд»ҘдҪҝз”Ё–partitions <numPartitions>жҢҮе®ҡеҲҶеҢәж•°гҖӮд№ҹеҸҜд»ҘеңЁserver.propertiesй…ҚзҪ®ж–Ү件дёӯй…ҚзҪ®еҸӮж•°num.partitionsжқҘжҢҮе®ҡй»ҳи®Өзҡ„еҲҶеҢәж•°гҖӮ
дҪҶжңүдёҖзӮ№йңҖиҰҒжіЁж„ҸпјҢдёәTopicеҲӣе»әеҲҶеҢәж—¶пјҢеҲҶеҢәж•°жңҖеҘҪжҳҜbrokerж•°йҮҸзҡ„ж•ҙж•°еҖҚпјҢиҝҷж ·жүҚиғҪжҳҜдёҖдёӘTopicзҡ„еҲҶеҢәеқҮеҢҖзҡ„еҲҶеёғеңЁж•ҙдёӘKafkaйӣҶзҫӨдёӯпјҢеҒҮи®ҫжҲ‘зҡ„KafkaйӣҶзҫӨз”ұ4дёӘbrokerз»„жҲҗпјҢд»ҘдёӢеӣҫдёәдҫӢпјҡ
еҲӣе»әеёҰеҲҶеҢәзҡ„Topic
зҺ°еңЁеҲӣе»әдёҖдёӘtopic вҖңlxw1234вҖқпјҢдёәиҜҘtopicжҢҮе®ҡ4дёӘеҲҶеҢәпјҢйӮЈд№Ҳиҝҷ4дёӘеҲҶеҢәе°ҶдјҡеңЁжҜҸдёӘbrokerдёҠеҗ„еҲҶеёғдёҖдёӘпјҡ
./kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 1 --partitions 4 --topic lxw1234

иҝҷж ·жүҖжңүзҡ„еҲҶеҢәе°ұеқҮеҢҖеҲҶеёғеңЁйӣҶзҫӨдёӯпјҢеҰӮжһңеҲӣе»әtopicж—¶еҖҷжҢҮе®ҡдәҶ3дёӘеҲҶеҢәпјҢйӮЈд№Ҳе°ұжңүдёҖдёӘbrokerдёҠжІЎжңүиҜҘtopicзҡ„еҲҶеҢәгҖӮ
еёҰеҲҶеҢә规еҲҷзҡ„з”ҹдә§иҖ…
зҺ°еңЁз”ЁдёҖдёӘз”ҹдә§иҖ…зӨәдҫӢпјҲPartitionerProducerпјүпјҢеҗ‘Topic lxw1234дёӯеҸ‘йҖҒж¶ҲжҒҜгҖӮиҜҘз”ҹдә§иҖ…дҪҝз”Ёзҡ„еҲҶеҢә规еҲҷпјҢе°ұжҳҜдёҠйқўзҡ„SimplePartitionerгҖӮд»Һ0-10дёҖе…ұ11жқЎж¶ҲжҒҜпјҢжҜҸжқЎж¶ҲжҒҜзҡ„keyдёәвҖқkeyвҖқ+indexпјҢж¶ҲжҒҜеҶ…е®№дёәвҖқkeyвҖқ+index+вҖқ–valueвҖқ+indexгҖӮжҜ”еҰӮпјҡkey0–value0гҖҒkey1–value1гҖҒгҖҒгҖҒkey10–value10гҖӮ
package com.lxw1234.kafka;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class PartitionerProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "127.0.0.17:9091,127.0.0.17:9092,127.0.0.102:9091,127.0.0.102:9092");
props.put("partitioner.class", "com.lxw1234.kafka.SimplePartitioner");
Producer<String, String> producer = new Producer<String, String>(new ProducerConfig(props));
String topic = "lxw1234";
for(int i=0; i<=10; i++) {
String k = "key" + i;
String v = k + "--value" + i;
producer.send(new KeyedMessage<String, String>(topic,k,v));
}
producer.close();
}
}
зҗҶи®әдёҠжқҘиҜҙпјҢз”ҹдә§иҖ…еңЁеҸ‘йҖҒж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢдјҡжҢүз…§SimplePartitionerзҡ„规еҲҷпјҢе°Ҷkey0еҒҡhashcodeпјҢ然еҗҺе’ҢеҲҶеҢәж•°пјҲ4пјүеҒҡжЁЎиҝҗз®—пјҢеҫ—еҲ°еҲҶеҢәзҙўеј•пјҡ
hashcode(вҖқkey0вҖқ) % 4 = 1
hashcode(вҖқkey1вҖқ) % 4 = 2
hashcode(вҖқkey2вҖқ) % 4 = 3
hashcode(вҖқkey3вҖқ) % 4 = 0
В В В В В В В В вҖҰвҖҰ
еҜ№еә”зҡ„ж¶ҲжҒҜе°Ҷдјҡиў«еҸ‘йҖҒиҮізӣёеә”зҡ„еҲҶеҢәдёӯгҖӮ
з»ҹи®Ўеҗ„еҲҶеҢәж¶ҲжҒҜзҡ„ж¶Ҳиҙ№иҖ…
дёӢйқўзҡ„ж¶Ҳиҙ№иҖ…д»Јз Ғз”ЁжқҘйӘҢиҜҒпјҢеңЁж¶Ҳиҙ№ж•°жҚ®ж—¶пјҢжү“еҚ°еҮәж¶ҲжҒҜжүҖеңЁзҡ„еҲҶеҢәеҸҠж¶ҲжҒҜеҶ…е®№пјҡ
package com.lxw1234.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
public class MyConsumer {
public static void main(String[] args) {
String topic = "lxw1234";
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while(it.hasNext()) {
MessageAndMetadata<byte[], byte[]> mam = it.next();
System.out.println("consume: Partition [" + mam.partition() + "] Message: [" + new String(mam.message()) + "] ..");
}
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("group.id","group1");
props.put("zookeeper.connect","127.0.0.132:2181,127.0.0.133:2182,127.0.0.134:2183");
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
return new ConsumerConfig(props);
}
}
иҝҗиЎҢзЁӢеәҸйӘҢиҜҒз»“жһң
е…ҲеҗҜеҠЁж¶Ҳиҙ№иҖ…пјҢеҶҚиҝҗиЎҢз”ҹдә§иҖ…гҖӮ
д№ӢеҗҺеңЁж¶Ҳиҙ№иҖ…зҡ„жҺ§еҲ¶еҸ°еҸҜд»ҘзңӢеҲ°еҰӮдёӢиҫ“еҮәпјҡ
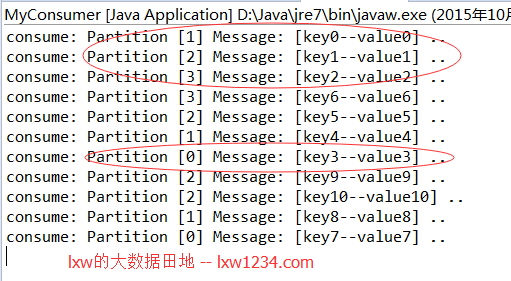
з»“жһңе’ҢжӯЈеёёйў„жңҹдёҖиҮҙгҖӮ
зӣёе…ійҳ…иҜ»пјҡ
Kafkaжһ¶жһ„е’ҢеҺҹзҗҶж·ұеәҰеү–жһҗ
Kafkaе®үиЈ…й…ҚзҪ®жөӢиҜ•
жҺҘдёӢжқҘе°ҶеӯҰд№ дҪҝз”ЁKafkaзҡ„еә•еұӮAPIпјҲlow-level APIпјүпјҢжҢҮе®ҡеҲҶеҢәе’ҢoffsetжқҘж¶Ҳиҙ№ж•°жҚ®гҖӮ
жӮЁеҸҜд»Ҙе…іжіЁ lxwзҡ„еӨ§ж•°жҚ®з”°ең° пјҢжҲ–иҖ… еҠ е…ҘйӮ®д»¶еҲ—иЎЁ пјҢйҡҸж—¶жҺҘ收еҚҡе®ўжӣҙж–°зҡ„йҖҡзҹҘйӮ®д»¶гҖӮ
еҰӮжһңи§үеҫ—жң¬еҚҡе®ўеҜ№жӮЁжңүеё®еҠ©пјҢиҜ· иөһеҠ©дҪңиҖ… гҖӮ
иҪ¬иҪҪиҜ·жіЁжҳҺпјҡlxwзҡ„еӨ§ж•°жҚ®з”°ең° » KafkaеҲҶеҢәжңәеҲ¶д»Ӣз»ҚдёҺзӨәдҫӢ


