关键字:spark、机器学习、特征处理、特征选择
Spark机器学习库中包含了两种实现方式,一种是spark.mllib,这种是基础的API,基于RDDs之上构建,另一种是spark.ml,这种是higher-level API,基于DataFrames之上构建,spark.ml使用起来比较方便和灵活。
Spark机器学习中关于特征处理的API主要包含三个方面:特征提取、特征转换与特征选择。本文通过例子介绍和学习Spark.ml中提供的关于特征处理API中的特征选择(Feature Selectors)部分。
特征选择(Feature Selectors)
1. VectorSlicer
VectorSlicer用于从原来的特征向量中切割一部分,形成新的特征向量,比如,原来的特征向量长度为10,我们希望切割其中的5~10作为新的特征向量,使用VectorSlicer可以快速实现。
package com.lxw1234.spark.features.selectors
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType
/**
* By http://lxw1234.com
*/
object TestVectorSlicer extends App {
val conf = new SparkConf().setMaster("local").setAppName("lxw1234.com")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
//构造特征数组
val data = Array(Row(Vectors.dense(-2.0, 2.3, 0.0)))
//为特征数组设置属性名(字段名),分别为f1 f2 f3
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])
//构造DataFrame
val dataRDD = sc.parallelize(data)
val dataset = sqlContext.createDataFrame(dataRDD, StructType(Array(attrGroup.toStructField())))
print("原始特征:")
dataset.take(1).foreach(println)
//构造切割器
var slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
//根据索引号,截取原始特征向量的第1列和第3列
slicer.setIndices(Array(0,2))
print("output1: ")
slicer.transform(dataset).select("userFeatures", "features").first()
//根据字段名,截取原始特征向量的f2和f3
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setNames(Array("f2","f3"))
print("output2: ")
slicer.transform(dataset).select("userFeatures", "features").first()
//索引号和字段名也可以组合使用,截取原始特征向量的第1列和f2
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array(0)).setNames(Array("f2"))
print("output3: ")
slicer.transform(dataset).select("userFeatures", "features").first()
}
程序运行输出为:
原始特征: [[-2.0,2.3,0.0]] output1: org.apache.spark.sql.Row = [[-2.0,2.3,0.0],[-2.0,0.0]] output2: org.apache.spark.sql.Row = [[-2.0,2.3,0.0],[2.3,0.0]] output3: org.apache.spark.sql.Row = [[-2.0,2.3,0.0],[-2.0,2.3]]
2. RFormula
RFormula用于将数据中的字段通过R语言的Model Formulae转换成特征值,输出结果为一个特征向量和Double类型的label。关于R语言Model Formulae的介绍可参考:https://stat.ethz.ch/R-manual/R-devel/library/stats/html/formula.html
package com.lxw1234.spark.features.selectors
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.feature.RFormula
/**
* By http://lxw1234.com
*/
object TestRFormula extends App {
val conf = new SparkConf().setMaster("local").setAppName("lxw1234.com")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
//构造数据集
val dataset = sqlContext.createDataFrame(Seq(
(7, "US", 18, 1.0),
(8, "CA", 12, 0.0),
(9, "NZ", 15, 0.0)
)).toDF("id", "country", "hour", "clicked")
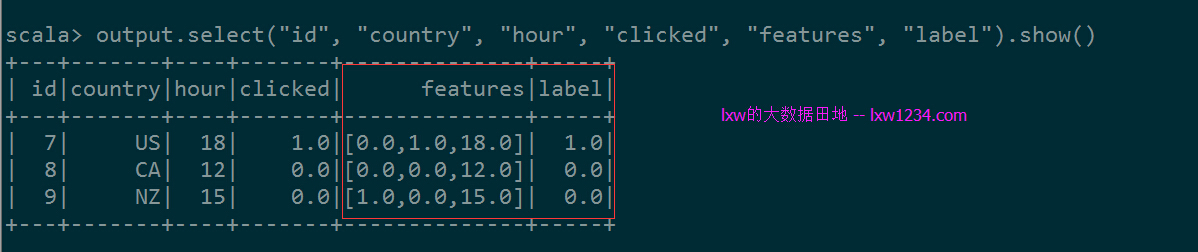
dataset.select("id", "country", "hour", "clicked").show()
//当需要通过country和hour来预测clicked时候,
//构造RFormula,指定Formula表达式为clicked ~ country + hour
val formula = new RFormula().setFormula("clicked ~ country + hour").setFeaturesCol("features").setLabelCol("label")
//生成特征向量及label
val output = formula.fit(dataset).transform(dataset)
output.select("id", "country", "hour", "clicked", "features", "label").show()
}
程序输出:

3. ChiSqSelector
ChiSqSelector用于使用卡方检验来选择特征(降维)。
package com.lxw1234.spark.features.selectors
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.mllib.linalg.Vectors
/**
* By http://lxw1234.com
*/
object TestChiSqSelector extends App {
val conf = new SparkConf().setMaster("local").setAppName("lxw1234.com")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
//构造数据集
val data = Seq(
(7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = sc.parallelize(data).toDF("id", "features", "clicked")
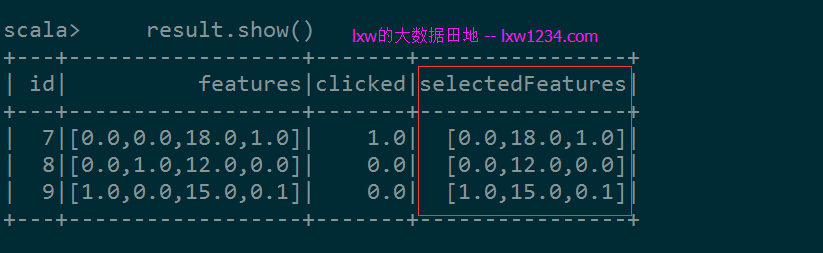
df.select("id", "features","clicked").show()
//使用卡方检验,将原始特征向量(特征数为4)降维(特征数为3)
val selector = new ChiSqSelector().setNumTopFeatures(3).setFeaturesCol("features").setLabelCol("clicked").setOutputCol("selectedFeatures")
val result = selector.fit(df).transform(df)
result.show()
}
程序输出为:

您可以关注 lxw的大数据田地 ,或者 加入邮件列表 ,随时接收博客更新的通知邮件。
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Spark机器学习API之特征处理(二)

