Cube是一种典型的多维数据分析技术,一个Cube可以有多个事实表,多个维表构成。如果您还不了解这些概念,建议您搜索下数据仓库、OLAP、Cube、星型模型、事实表、维度表等等。比如一个简单例子,分析网站流量的Cube,包含一个事实表和四个维度表:
事实表可能有以下字段:
天、来源ID、浏览器ID、操作系统ID、PV、PageNumber等等;
其中,小时、来源ID、浏览器ID、操作系统ID 为维度;
PV、PageNumber为指标;
一般事实表中的维度都采用外键ID的形式,一来可以节省存储,也可以很好的适用于其他分析工具;
维度表包括:
时间维表:年、月、日,其中天为最细粒度,也为该表主键;
访问来源维表:来源ID、来源名称;
浏览器维表:浏览器ID、浏览器名称、etc.
操作系统维表:操作系统ID、操作系统名称、etc.
事实表中的维度,分别与这四张维度表,通过主外键的方式关联。
Kylin中的Cube亦是这种模型。
创建Cube
之前的文章《分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例》介绍过在Kylin中定义数据模型和Cube。
Build Cube
定义好Cube之后,Apache Kylin通过MapReduce,将存储在Hive中的事实表和维度表,转换成Cube,存储在HBase中,以实现快速分析查询,整个过程如下图所示:
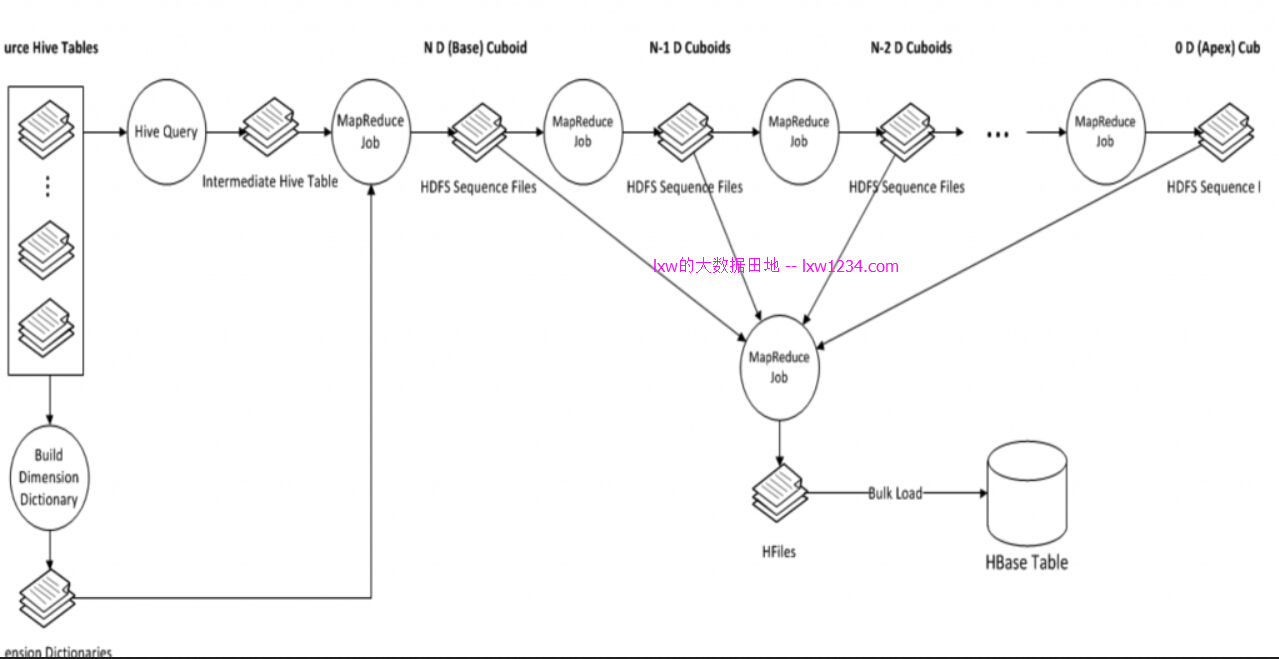
STEP1. 根据Cube定义的事实表和维度,在Hive中生成一张中间表;
Create Intermediate Flat Hive Table;
STEP2. 使用MapReduce,从事实表中抽取维度的Distinct值,并以字典树的方式压缩编码,同时也对所有维度表进行压缩编码,生成维度字典;
Extract Fact Table Distinct Columns
Build Dimension Dictionary
STEP3. 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid,后面会详细介绍。
Save Cuboid Statistics
STEP4. 创建HBase Table;
Create HTable
STEP5. 利用step1中间表的数据,使用MapReduce,生成每一种维度组合(Cuboid)的数据;
Build Base Cuboid Data;
Build N-Dimension Cuboid Data : 7-Dimension;
Build N-Dimension Cuboid Data : 6-Dimension;
。。。。。。
Build N-Dimension Cuboid Data : 2-Dimension;
Build Cube;
STEP6. 将Cuboid数据转换成HFile,并导入到HBase Table中:
Convert Cuboid Data to HFile;
Load HFile to HBase Table;
STEP7. 更新Cube信息,清理中间表:
Update Cube Info;
Garbage Collection;
整个Build过程结束。
关于维度组合Cuboid
Kylin中Cube的Build过程,其实是将所有的维度组合事先计算,存储于HBase中,以空间换时间,HTable对应的RowKey,就是各种维度组合,指标存在Column中,这样,将不同维度组合查询SQL,转换成基于RowKey的范围扫描,然后对指标进行汇总计算。
理论上来说,一个N维的Cube,便有2的N次方种维度组合,参考网上的一个例子,一个Cube包含time, item, location, supplier四个维度,那么组合(Cuboid)便有16种:
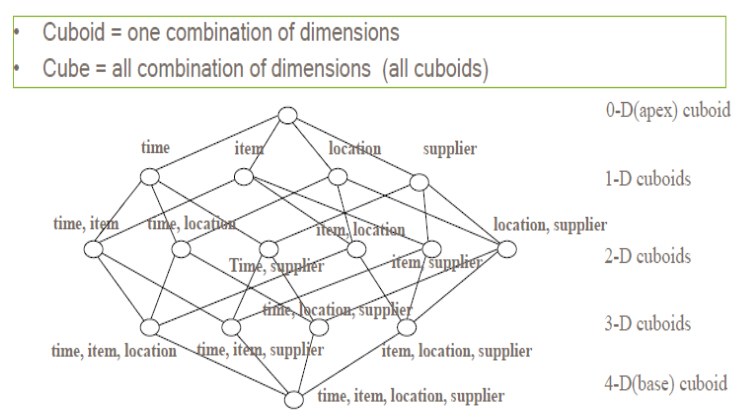
一个Cube中,当维度数量N超过一定数量后,空间以及计算消耗将会非常大,Kylin在定义Cube时候,可以将维度拆分成多个聚合组(Aggregation Groups),只在组内计算Cube,聚合组内查询效率高,跨组查询效率较差,所以需要根据业务场景,将常用的维度组合定义到一个聚合组中,提高查询性能,这也是Kylin中查询性能优化的一个重要方面。
后续将继续学习Kylin的原理及优化。
如果觉得本博客对您有帮助,请 赞助作者 。

