前面介绍了将Saiku和Kylin结合起来做OLAP多维分析,Saiku也支持多种其他数据源,如MySQL,JDBC等,本文介绍将Saiku和Hive结合起来使用的方法,并解决期间遇到的问题。
注:Saiku社区版(Saiku CE)的下载地址为:
http://community.meteorite.bi/?cedownload
Saiku与Hive
Saiku最新的社区版本中自带的Hive版本为0.13.1,我使用的Hive版本也为0.13.1,Saiku通过JDBC与HiveServer连接。
启动HiveServer2
注意:启动HiverServer2时候,可以后台运行,并将日志重定向到一个文件中,方便查看:./hiveserver2 >> /tmp/hiveserver.log 2>&1 &
启动Saiku
新建mondrian schema
基于Hive中已有的事实表lxw1234_kylin_fact(该表是之前为kylin创建的,这里直接使用,和表名无关)创建Schema:
hive> desc lxw1234_kylin_fact; OK day date cookieid string region string city string siteid string os string pv bigint
vi ad_schema2.xml
<?xml version="1.0"?> <Schema name="ad_schema2"> <Cube name="lxw1234_ad_cube_hive"> <!-- 事实表(fact table) --> <Table name="lxw1234_kylin_fact" /> <Dimension name="地域"> <Hierarchy hasAll="false"> <Table name="lxw1234_kylin_fact"></Table> <Level name="省份" column="region" table="lxw1234_kylin_fact"></Level> <Level name="城市" column="city" table="lxw1234_kylin_fact"/> </Hierarchy> </Dimension> <Measure name="曝光数" column="pv" aggregator="sum" datatype="Integer" /> </Cube> </Schema>
这里只取了两个维度,省份和城市,一个指标PV。
将schema文件上传到Saiku。
新建Hive数据源
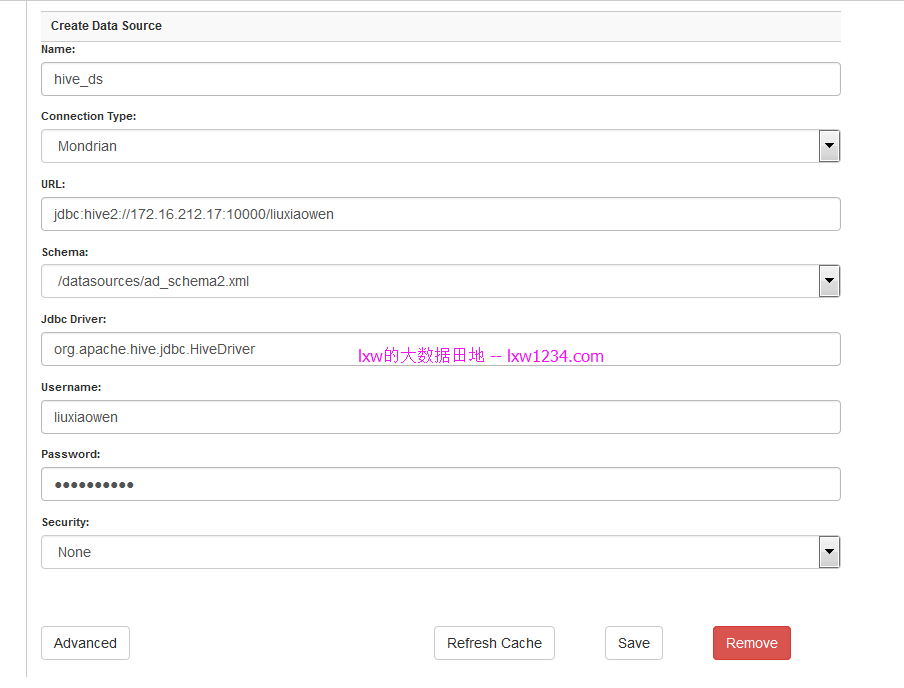
创建一个名为hive_ds的Hive JDBC数据源。
Hive-JDBC的错误
当进入到Home页,点击创建新查询之后,在多维数据集里面没有刚才新建的数据源hive_ds,查看saiku后台日志,发现以下错误(这里一并列出):
错误1:
ERROR [SecurityAwareConnectionManager] Error connecting: hive_ds mondrian.olap.MondrianException: Mondrian Error:Internal error: while quoting identifier Caused by: java.sql.SQLException: Method not supported at org.apache.hive.jdbc.HiveDatabaseMetaData.getIdentifierQuoteString (HiveDatabaseMetaData.java:342)
该错误是由于Mondrian中使用了hive-jdbc未实现的方法:getIdentifierQuoteString,hive-jdbc-0.13.1.jar源码中该方法为:
public String getIdentifierQuoteString() throws SQLException {
throw new SQLException("Method not supported");
}
错误2:
ERROR [SecurityAwareConnectionManager] Error connecting: hive_ds
mondrian.olap.MondrianException: Mondrian Error:Internal error: while detecting isReadOnly
Caused by: java.sql.SQLException: Method not supported
at org.apache.hive.jdbc.HiveDatabaseMetaData.isReadOnly
(HiveDatabaseMetaData.java:762)
错误原因同上。
解决的方法,需要修改hive-jdbc-0.13.1.jar中的源码org.apache.hive.jdbc.HiveDatabaseMetaData,将上面的两个方法改为:
public boolean isReadOnly() throws SQLException {
return false;
}
public String getIdentifierQuoteString() throws SQLException {
return " ";
}
注意,要快速修改源码,不要整个编译工程,通常我的做法是引入相关的jar包,这里需要引入hive-jdbc-0.13.1.jar 和 hive-metastore-0.13.1.jar ,然后新建一个package和源文件的package相同:org.apache.hive.jdbc , 再将源码 HiveDatabaseMetaData.java 拷贝到该package下进行修改,修改好后,将该类相关的class文件,替换到 hive-jdbc-0.13.1.jar 中即可。
用新的hive-jdbc-0.13.1.jar 替换Saiku中的jar包,位置在:~/saiku/saiku-server/tomcat/webapps/saiku/WEB-INF/lib下。
重启Saiku Server。
创建查询
重启后,再次进入创建查询页面,后台没有报错,多维数据集下已经有了hive_ds。选择维度和指标后,saiku生成查询语句,并通过JDBC提交查询到Hive。
saiku的日志:

另外,HiveServer2的日志中也有MapReduce运行日志产生。
但通过日志可以看到,这个简单的查询,貌似被分成好几步来执行查询,最后耗时87秒。

Hive查询过程分析
从ResourceManager的页面上看到,一共提交了三个SQL:
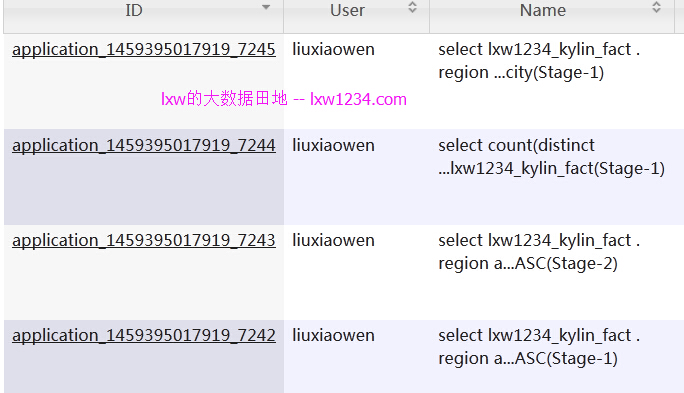
第一个SQL为:
SELECT lxw1234_kylin_fact.region as c0, lxw1234_kylin_fact.city as c1 FROM lxw1234_kylin_fact as lxw1234_kylin_fact GROUP BY lxw1234_kylin_fact.region,lxw1234_kylin_fact.city ORDER BY CASE WHEN lxw1234_kylin_fact.region IS NULL THEN 1 ELSE 0 END,lxw1234_kylin_fact.region ASC, CASE WHEN lxw1234_kylin_fact.city IS NULL THEN 1 ELSE 0 END,lxw1234_kylin_fact.city ASC
作用是从事实表中抽取所有维度并去重排序。
第二个SQL为:
SELECT count(DISTINCT city) FROM lxw1234_kylin_fact
看上去是获取所有city的不重复数。
第三个SQL为:
SELECT lxw1234_kylin_fact.region as c0, lxw1234_kylin_fact.city as c1, SUM(lxw1234_kylin_fact.pv) as m0 FROM lxw1234_kylin_fact as lxw1234_kylin_fact GROUP BY lxw1234_kylin_fact.region, lxw1234_kylin_fact.city
发现这个SQL才是最终显示结果要用的查询,那么前两个的作用是什么呢?
看下面的操作:
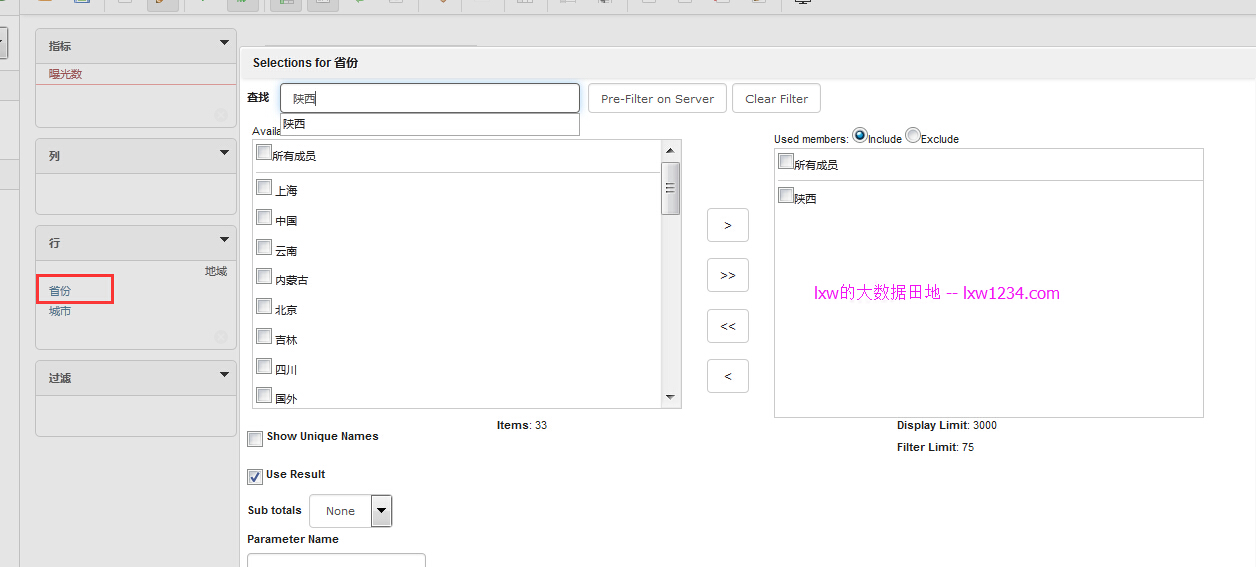
点击省份维度之后,便弹出筛选对话框,里面列出了所有的省份名称,点击城市维度之后也是如此,前两个SQL的用途便在这里,从事实表中提取出所有维度缓存起来,供筛选使用。
另外,Saiku对于Hive的查询结果也会缓存,这样,在做分析查询的时候,能从缓存中获取的数据便不会再从Hive中查询,可以试试,过滤几个省份,获取去掉城市维度,结果立刻就返回,并不是从Hive中查询,这点,使得Saiku+Hive的可行性增强了不少。
接下来就尝试使用Saiku和SparkSQL结合使用,效率应该比Hive好很多。请持续关注 “lxw的大数据田地” .
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » Saiku结合Hive做大数据多维数据分析

