关键字:Hive数据取样、Hive Sampling、Hive TABLESAMPLE.
在Hive中提供了数据取样(SAMPLING)的功能,用来从Hive表中根据一定的规则进行数据取样,Hive中的数据取样支持分桶表取样和数据块取样。
16.1 数据块取样(Block Sampling)
- block_sample: TABLESAMPLE (n PERCENT)
根据输入的inputSize,取样n%。
比如:输入大小为1G,TABLESAMPLE (50 PERCENT)将会取样512M的数据;
看例子:
表lxw1总大小约为64816816,总记录数为:2750714
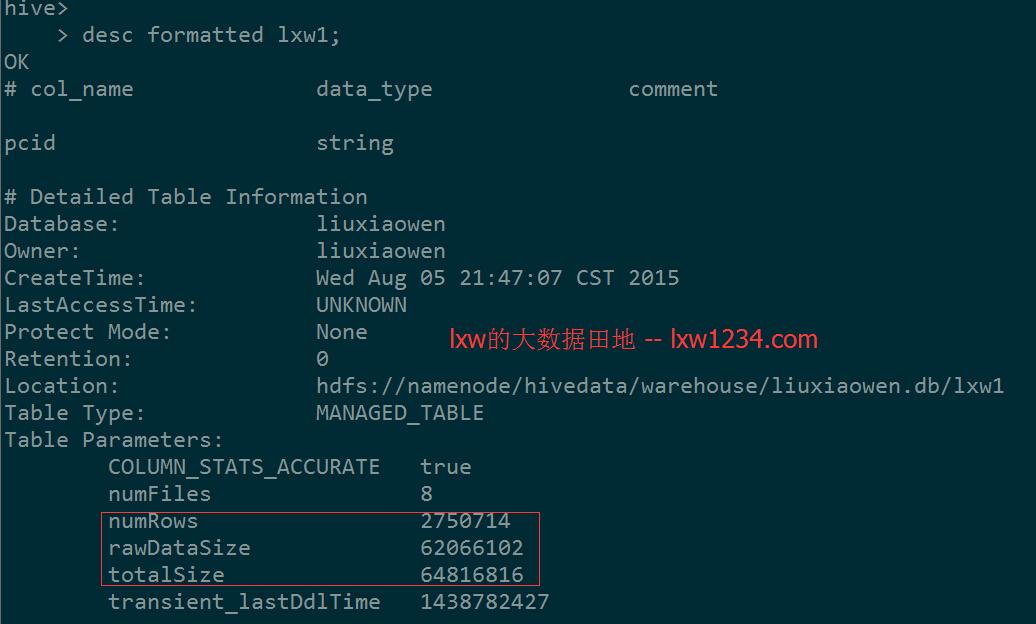
使用下面的语句,从表lxw111中取样50%的数据,创建一个新表:
CREATE TABLE lxw1234 AS
SELECT * FROM lxw1 TABLESAMPLE (50 PERCENT);
完成后看看表lxw1234的记录数和大小:
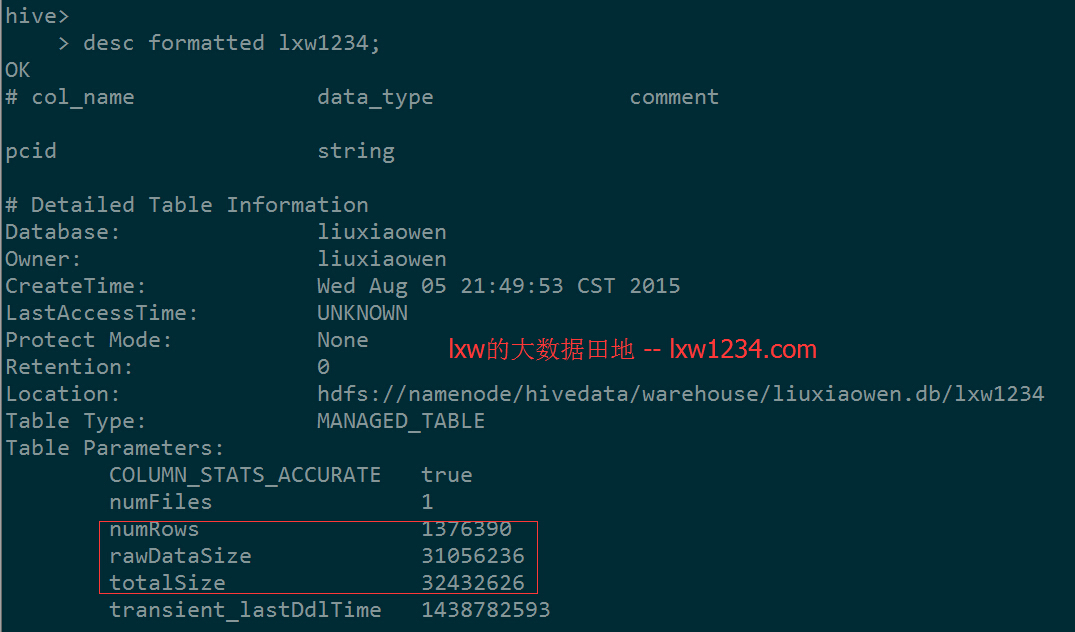
结果表记录数:1376390,总大小:32432626,基本上是原表的50%。
- block_sample: TABLESAMPLE (nM)
这种方式指定取样数据的大小,单位为M。
比如,下面的语句:
CREATE TABLE lxw1234_2 AS
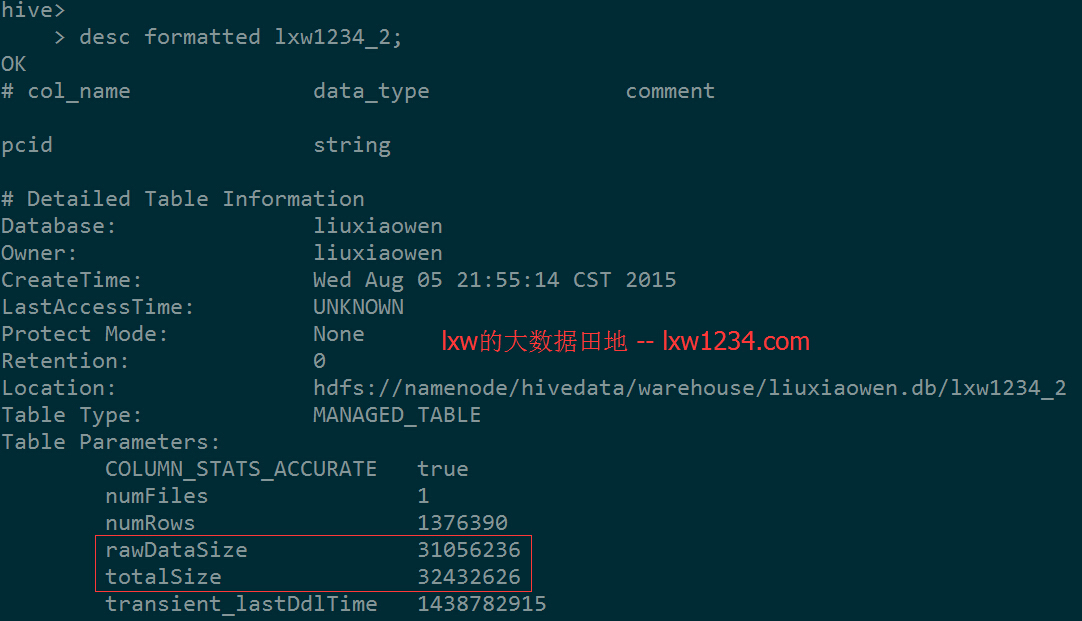
SELECT * FROM lxw1 TABLESAMPLE (30M);
将会从表lxw1中取样30M的数据:
- block_sample: TABLESAMPLE (n ROWS)
这种方式可以根据行数来取样,但要特别注意:这里指定的行数,是在每个InputSplit中取样的行数,也就是,每个Map中都取样n ROWS。
下面的语句:
SELECT COUNT(1) FROM (SELECT * FROM lxw1 TABLESAMPLE (200 ROWS)) x;
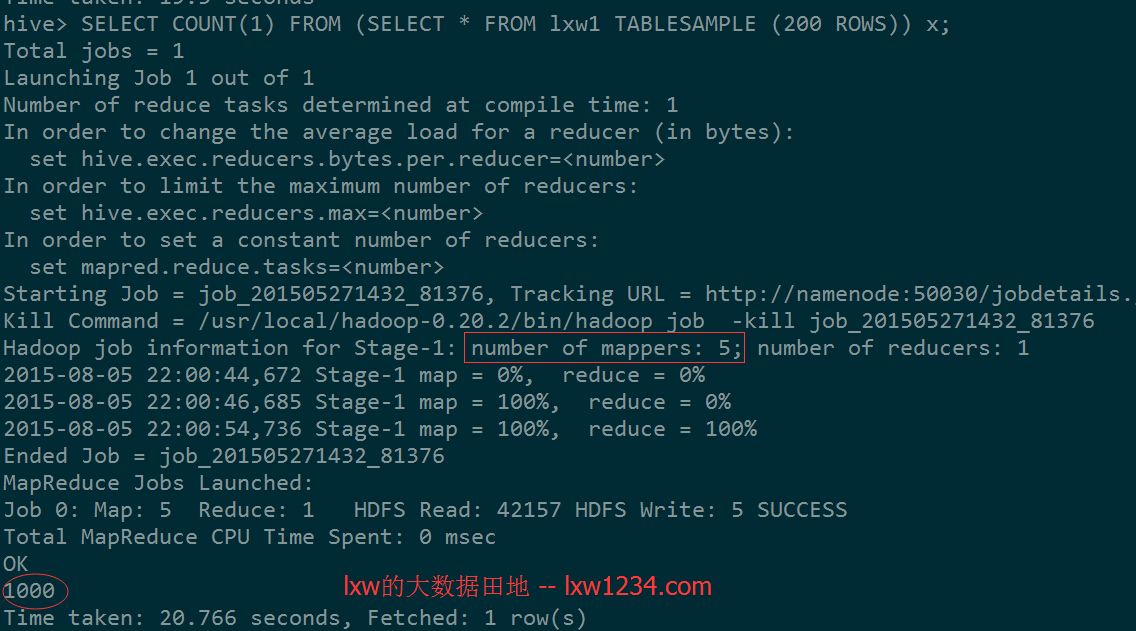
有5个Map Task(InputSplit),每个取样200行,一共1000行。
16.2 分桶表取样(Sampling Bucketized Table)
关于Hive中的分桶表(Bucket Table),在以后的文章中将会介绍,其实就是根据某一个字段Hash取模,放入指定数据的桶中,比如将表lxw1234按照ID分成100个桶,其算法是hash(id) % 100,这样,hash(id) % 100 = 0的数据被放到第一个桶中,hash(id) % 100 = 1的记录被放到第二个桶中。分桶表在创建时候使用CLUSTER BY语句创建。
Hive中分桶表取样的语法是:
table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
其中x是要抽样的桶编号,桶编号从1开始,colname表示抽样的列,y表示桶的数量。
例子1:
SELECT COUNT(1)
FROM lxw1 TABLESAMPLE (BUCKET 1 OUT OF 10 ON rand());
该语句表示将表lxw1随机分成10个桶,抽样第一个桶的数据;
前面介绍过,表lxw1总大小约为64816816,总记录数为:2750714
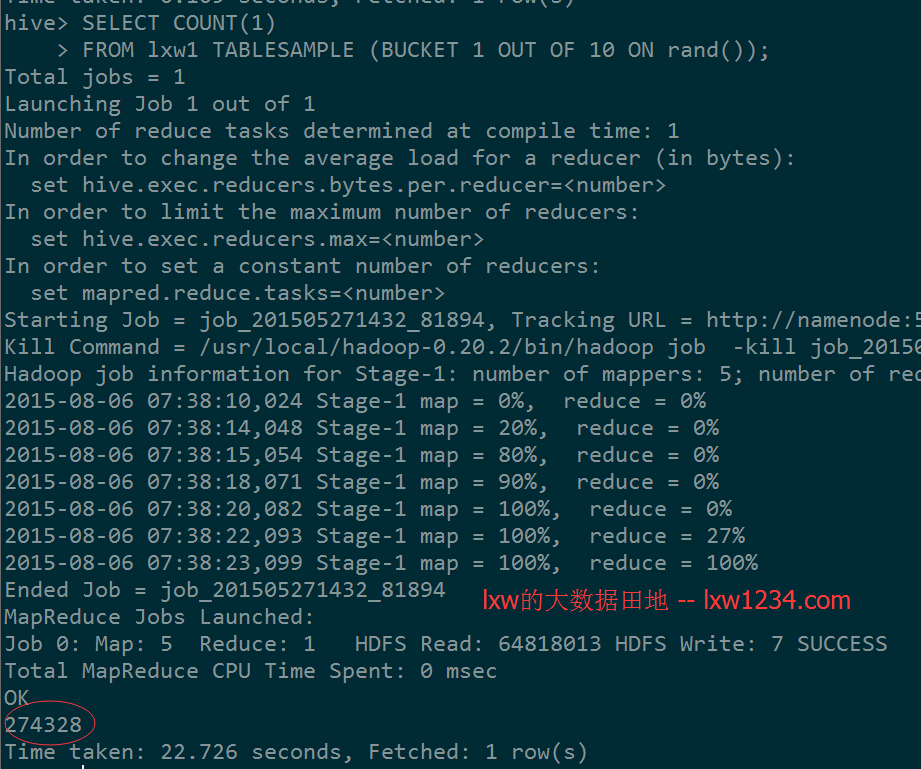
出来的结果基本上是原表的十分之一,注意:这个结果每次运行是不一样的,因为是按照随机数进行分桶取样的。
例子2:
如果基于一个已经分桶表进行取样,将会更有效率。
执行下面的语句,创建一个分桶表,并插入数据:
CREATE TABLE lxw1_bucketed (pcid STRING)
CLUSTERED BY(pcid) INTO 10 BUCKETS;
INSERT overwrite TABLE lxw1_bucketed
SELECT pcid FROM lxw1;
表lxw1_bucketed按照pcid字段分成10个桶,下面的语句表示从10个桶中抽样第一个桶的数据:
SELECT COUNT(1) FROM lxw1_bucketed TABLESAMPLE(BUCKET 1 OUT OF 10 ON pcid);
很好理解。
再看这个:
SELECT COUNT(1) FROM lxw1_bucketed TABLESAMPLE(BUCKET 1 OUT OF 20 ON pcid)
表只有10个桶,如果指定20,看结果:
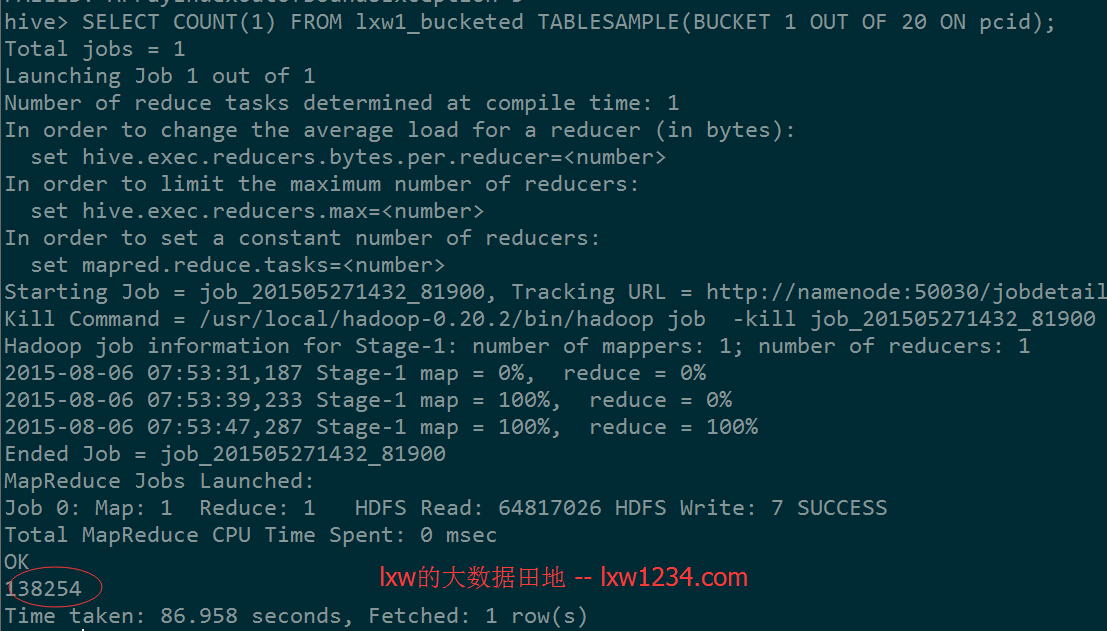
结果差不多是源表记录的1/20,Hive在运行时候,会在第一个桶中抽样一半的数据。
还有一点:
如果从源表中直接分桶抽样,也能达到一样的效果,比如:
SELECT COUNT(1) FROM lxw1 TABLESAMPLE(BUCKET 1 OUT OF 20 ON pcid);
区别在于基于已经分桶的表抽样,查询只会扫描相应桶中的数据,而基于未分桶表的抽样,查询时候需要扫描整表数据,先分桶,再抽样。
其它更详细的用法请参考Hive的官方文档说明。
更多关于Hadoop、Spark、Hive等的文章,请关注 我的博客 。
Hive相关文章(持续更新):
—-Hive中的数据库(Database)和表(Table)
hive优化之——控制hive任务中的map数和reduce数
如果觉得本博客对您有帮助,请 赞助作者 。

