关键字:Hive HQL Job数量、Hive执行计划、Hive LineageInfo
本文介绍使用Hive的API获取一条HQL的最终执行计划,从而获取这条HQL的Job数量,另外,介绍使用API分析一条HQL中所包含的输入表和输出表。这些信息在做元数据管理和Hive表的血缘分析时候很有用。
Hive在执行一条HQL的时候,会经过以下步骤:
- 语法解析:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象 语法树AST Tree;
- 语义解析:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
- 生成逻辑执行计划:遍历QueryBlock,翻译为执行操作树OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- 生成物理执行计划:遍历OperatorTree,翻译为MapReduce任务;
- 优化物理执行计划:物理层优化器进行MapReduce任务的变换,生成最终的执行计划;
关于这几个步骤,在美团的技术博客上有一篇文章介绍的非常好,可以参考:http://tech.meituan.com/hive-sql-to-mapreduce.html
一般情况下,HQL中的每一个表或者子查询都会生成一个job,这是逻辑执行计划中生成的,但后面Hive还会优化,比如:使用MapJoin,最终一条HQL语句生成的job数量很难通过HQL观察出来。
获取HQL的执行计划和Job数量
直接看代码吧:
package com.lxw1234.test;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.ql.Context;
import org.apache.hadoop.hive.ql.QueryPlan;
import org.apache.hadoop.hive.ql.exec.Utilities;
import org.apache.hadoop.hive.ql.parse.ASTNode;
import org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer;
import org.apache.hadoop.hive.ql.parse.ParseDriver;
import org.apache.hadoop.hive.ql.parse.ParseUtils;
import org.apache.hadoop.hive.ql.parse.SemanticAnalyzerFactory;
import org.apache.hadoop.hive.ql.session.SessionState;
/**
* lxw的大数据田地 -- lxw1234.com
* @author lxw1234
*
*/
public class HiveQueryPlan {
public static void main(String[] args) throws Exception {
HiveConf conf = new HiveConf();
conf.addResource(new Path("file:///usr/local/apache-hive-0.13.1-bin/conf/hive-site.xml"));
conf.addResource(new Path("file:///usr/local/apache-hive-0.13.1-bin/conf/hive-default.xml.template"));
conf.set("javax.jdo.option.ConnectionURL",
"jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf-8");
conf.set("hive.metastore.local", "true");
conf.set("javax.jdo.option.ConnectionDriverName","com.mysql.jdbc.Driver");
conf.set("javax.jdo.option.ConnectionUserName", "hive");
conf.set("javax.jdo.option.ConnectionPassword", "hive");
conf.set("hive.stats.dbclass", "jdbc:mysql");
conf.set("hive.stats.jdbcdriver", "com.mysql.jdbc.Driver");
conf.set("hive.exec.dynamic.partition.mode", "nonstrict");
String command = args[0];
SessionState.start(conf);
Context ctx = new Context(conf);
ParseDriver pd = new ParseDriver();
ASTNode tree = pd.parse(command, ctx);
tree = ParseUtils.findRootNonNullToken(tree);
BaseSemanticAnalyzer sem = SemanticAnalyzerFactory.get(conf, tree);
sem.analyze(tree, ctx);
sem.validate();
QueryPlan queryPlan = new QueryPlan(command,sem,0l);
int jobs = Utilities.getMRTasks(queryPlan.getRootTasks()).size();
System.out.println("Total jobs = " + jobs);
}
}
将上面的代码打包成testhive.jar,运行该类需要引入Hive的依赖包,在包含Hadoop和Hive客户端的机器上执行下面的命令:
for f in /usr/local/apache-hive-0.13.1-bin/lib/*.jar; do
HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:$f;
done
export HADOOP_CLASSPATH
分别解析下面三条HQL语句:
HQL1:SELECT COUNT(1) FROM liuxiaowen.lxw1; HQL2:SELECT COUNT(1) FROM (SELECT url FROM liuxiaowen.lxw1 GROUP BY url) x; HQL3:SELECT COUNT(1) FROM liuxiaowen.lxw1 a join liuxiaowen.lxw2 b ON (a.url = b.domain);
解析HQL1:
hadoop jar testhive.jar com.lxw1234.test.HiveQueryPlan "SELECT COUNT(1) FROM liuxiaowen.lxw1"
结果如下:

解析HQL2:
hadoop jar testhive.jar com.lxw1234.test.HiveQueryPlan "SELECT COUNT(1) FROM (SELECT url FROM liuxiaowen.lxw1 GROUP BY url) x"
结果如下:

解析HQL3:
hadoop jar testhive.jar com.lxw1234.test.HiveQueryPlan "SELECT COUNT(1) FROM liuxiaowen.lxw1 a join liuxiaowen.lxw2 b ON (a.url = b.domain)"
结果如下:
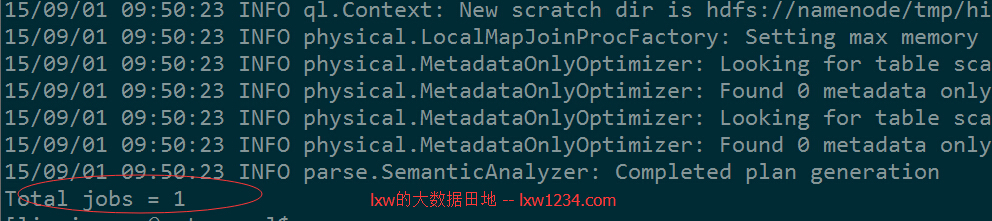
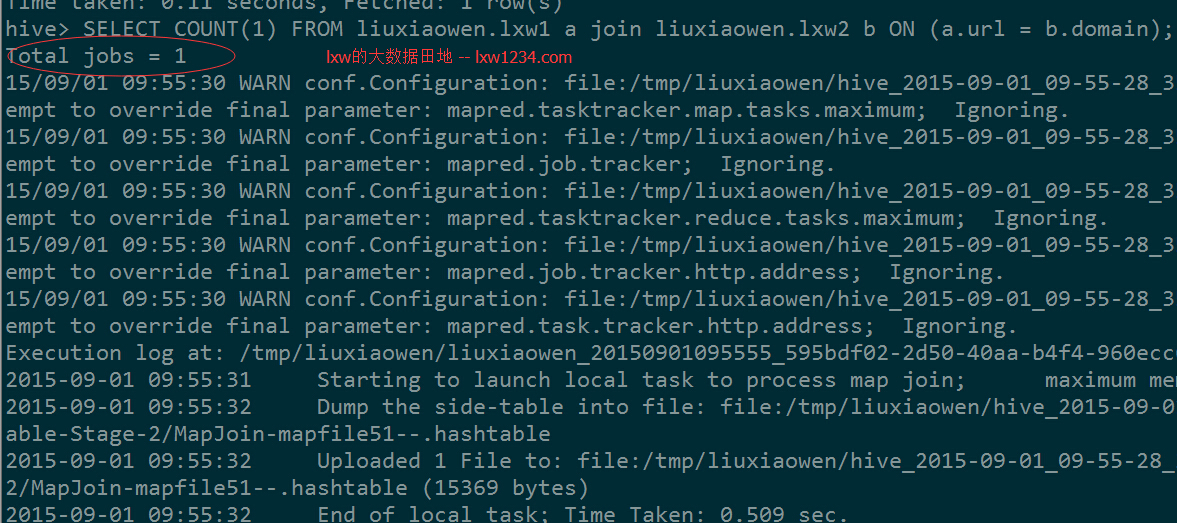
在HQL3中,由于Hive自动优化使用了MapJoin,因此,两个表的join最终只用了一个job,在Hive中执行验证一下:
解析HQL中表的血缘关系
在元数据管理中,可能需要知道Hive中有哪些表,以及这些表之间的关联关系,比如:A表是由B表和C表统计汇总而来。
Hive中本身自带了一个工具,用来分析一条HQL中的源表和目标表,org.apache.hadoop.hive.ql.tools.LineageInfo
但该类中目标表只能是使用INSERT语句插入数据的目标表,对于使用CREATE TABLE AS语句创建的表分析不出来。
下面的代码只对org.apache.hadoop.hive.ql.tools.LineageInfo做了小小的修改:
package com.lxw1234.test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Stack;
import java.util.TreeSet;
import org.apache.hadoop.hive.ql.lib.DefaultGraphWalker;
import org.apache.hadoop.hive.ql.lib.DefaultRuleDispatcher;
import org.apache.hadoop.hive.ql.lib.Dispatcher;
import org.apache.hadoop.hive.ql.lib.GraphWalker;
import org.apache.hadoop.hive.ql.lib.Node;
import org.apache.hadoop.hive.ql.lib.NodeProcessor;
import org.apache.hadoop.hive.ql.lib.NodeProcessorCtx;
import org.apache.hadoop.hive.ql.lib.Rule;
import org.apache.hadoop.hive.ql.parse.ASTNode;
import org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer;
import org.apache.hadoop.hive.ql.parse.HiveParser;
import org.apache.hadoop.hive.ql.parse.ParseDriver;
import org.apache.hadoop.hive.ql.parse.ParseException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
/**
* lxw的大数据田地 -- lxw1234.com
* @author lxw1234
*
*/
public class HiveLineageInfo implements NodeProcessor {
/**
* Stores input tables in sql.
*/
TreeSet inputTableList = new TreeSet();
/**
* Stores output tables in sql.
*/
TreeSet OutputTableList = new TreeSet();
/**
*
* @return java.util.TreeSet
*/
public TreeSet getInputTableList() {
return inputTableList;
}
/**
* @return java.util.TreeSet
*/
public TreeSet getOutputTableList() {
return OutputTableList;
}
/**
* Implements the process method for the NodeProcessor interface.
*/
public Object process(Node nd, Stack stack, NodeProcessorCtx procCtx,
Object... nodeOutputs) throws SemanticException {
ASTNode pt = (ASTNode) nd;
switch (pt.getToken().getType()) {
case HiveParser.TOK_CREATETABLE:
OutputTableList.add(BaseSemanticAnalyzer.getUnescapedName((ASTNode)pt.getChild(0)));
break;
case HiveParser.TOK_TAB:
OutputTableList.add(BaseSemanticAnalyzer.getUnescapedName((ASTNode)pt.getChild(0)));
break;
case HiveParser.TOK_TABREF:
ASTNode tabTree = (ASTNode) pt.getChild(0);
String table_name = (tabTree.getChildCount() == 1) ?
BaseSemanticAnalyzer.getUnescapedName((ASTNode)tabTree.getChild(0)) :
BaseSemanticAnalyzer.getUnescapedName((ASTNode)tabTree.getChild(0)) + "." + tabTree.getChild(1);
inputTableList.add(table_name);
break;
}
return null;
}
/**
* parses given query and gets the lineage info.
*
* @param query
* @throws ParseException
*/
public void getLineageInfo(String query) throws ParseException,
SemanticException {
/*
* Get the AST tree
*/
ParseDriver pd = new ParseDriver();
ASTNode tree = pd.parse(query);
while ((tree.getToken() == null) && (tree.getChildCount() > 0)) {
tree = (ASTNode) tree.getChild(0);
}
/*
* initialize Event Processor and dispatcher.
*/
inputTableList.clear();
OutputTableList.clear();
// create a walker which walks the tree in a DFS manner while maintaining
// the operator stack. The dispatcher
// generates the plan from the operator tree
Map<Rule, NodeProcessor> rules = new LinkedHashMap<Rule, NodeProcessor>();
// The dispatcher fires the processor corresponding to the closest matching
// rule and passes the context along
Dispatcher disp = new DefaultRuleDispatcher(this, rules, null);
GraphWalker ogw = new DefaultGraphWalker(disp);
// Create a list of topop nodes
ArrayList topNodes = new ArrayList();
topNodes.add(tree);
ogw.startWalking(topNodes, null);
}
public static void main(String[] args) throws IOException, ParseException,
SemanticException {
String query = args[0];
HiveLineageInfo lep = new HiveLineageInfo();
lep.getLineageInfo(query);
System.out.println("Input tables = " + lep.getInputTableList());
System.out.println("Output tables = " + lep.getOutputTableList());
}
}
将上面的程序打包成testhive.jar,同上面,执行时候需要引入Hive的依赖包:
分析下面两条HQL语句:
HQL1:CREATE TABLE liuxiaowen.lxw1234 AS SELECT * FROM liuxiaowen.lxw1; HQL2:INSERT OVERWRITE TABLE liuxiaowen.lxw3 SELECT a.url FROM liuxiaowen.lxw1 a join liuxiaowen.lxw2 b ON (a.url = b.domain);
执行命令:
hadoop jar testhive.jar com.lxw1234.test.HiveLineageInfo "CREATE TABLE liuxiaowen.lxw1234 AS SELECT * FROM liuxiaowen.lxw1"
hadoop jar testhive.jar com.lxw1234.test.HiveLineageInfo "INSERT OVERWRITE TABLE liuxiaowen.lxw3 SELECT a.url FROM liuxiaowen.lxw1 a
join liuxiaowen.lxw2 b ON (a.url = b.domain)"
分析结果:
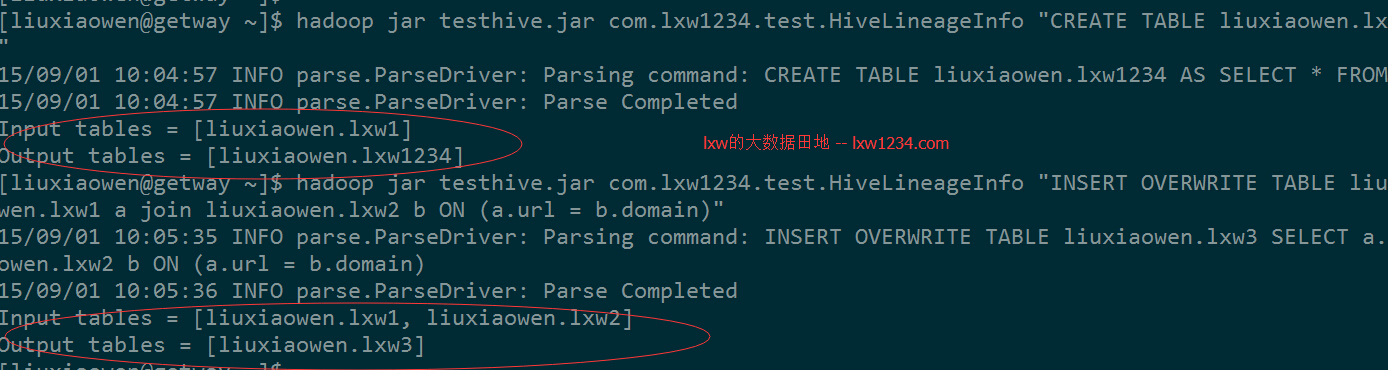
HQL中的Input table和Output table已经正确解析出来。
Hive相关文章(持续更新):
—-Hive中的数据库(Database)和表(Table)
hive优化之——控制hive任务中的map数和reduce数
如果觉得本博客对您有帮助,请 赞助作者 。
转载请注明:lxw的大数据田地 » [一起学Hive]之十九-使用Hive API分析HQL的执行计划、Job数量和表的血缘关系

